R-CNN 系列演算法都有獲取候選區域這個步驟,然而也是因為分為兩步驟進行,雖然精準,但偵測速度受到了限制。因此另一派演算法選擇拋去這個步驟,最具代表性的模型為 YOLO (You Only Look Once) 與 SSD (Single Shot multibox Detector)。
YOLO 由 Joseph Redmon 在 2015 年提出,核心思想是「將目標偵測視為一個單一的回歸問題,直接從完整的圖像像素,預測出邊界框座標和類別機率。」流程如下
劃分網格:YOLO 首先將輸入圖片縮放到一個固定尺寸(例如 416×416),然後將其劃分成一個 S×S 的網格(例如 13×13)。
中心點歸屬:如果一個物體的中心點,落在了某一個網格單元 (grid cell) 內,那麼這個網格單元就全權負責預測這個物體。
單次預測:每個網格單元,都會同時預測 B 個邊界框 (bounding box),以及這些邊界框的置信度 (confidence score),還有 C 個類別的條件機率。
邊界框:每個框包含5個值 (x, y, w, h, confidence)。x, y 是相對於網格單元的中心點座標,w, h 是相對於整張圖的寬和高。
置信度: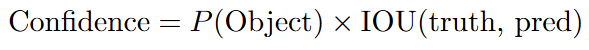
它同時反映了這個框內「包含物體的機率」以及「預測框與真實框的交併比 (IOU)」。
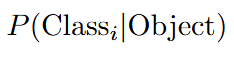
它表示在「確定這個網格包含物體」的前提下,這個物體屬於各個類別的機率。
YOLO 將整個偵測問題,用一個單一的卷積神經網路來端到端地解決,這使得它的速度極快,光 YOLOv1 當時就能達到 45 FPS。
SSD 在 YOLOv1 提出後不久也相繼誕生,它借鑑了 Faster R-CNN 中的錨框概念,並在一個 CNN 網路不同深度的卷積層上,分別進行預測。流程如下
多尺度特徵圖: SSD 使用一個 VGG-16 作為主幹網路,但它並不像分類任務那樣只使用最後一層的特徵。它會從主幹網路中,由淺到深地選取多個不同尺寸的特徵圖。
分層預測:
淺層的、高解析度的特徵圖(例如 38×38),被用來偵測小目標。因為它們保留了更多細節的空間資訊。
深層的、低解析度的特徵圖(例如 10×10, 3×3),被用來偵測大目標。因為它們擁有更大的感受域和更抽象的語意資訊。
透過在多個尺度的特徵圖上同時進行預測,SSD 能夠適當地處理不同大小的物體,在保持極高速度的同時,其偵測精度甚至能媲美當時的 Faster R-CNN,是一個在速度與精度上都取得了平衡的模型。
首先到以下網址下載 cfg、weights 跟 coco.names
https://pjreddie.com/darknet/yolo/
https://github.com/pjreddie/darknet/blob/master/data/coco.names
import cv2
import numpy as np
# --- 1. 載入 YOLOv3 模型 ---
print("正在載入 YOLOv3 模型...")
# cv2.dnn.readNet(weights_path, config_path)
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
# 載入所有類別名稱
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
# 獲取輸出層的名稱
layer_names = net.getLayerNames()
output_layers = [layer_names[i - 1] for i in net.getUnconnectedOutLayers()]
print("模型載入完成!")
# --- 2. 讀取圖片 ---
image_path = "dog.jpg" # 換成你自己的圖片
img = cv2.imread(image_path)
height, width, channels = img.shape
# --- 3. 圖片預處理並送入網路 ---
# YOLO 需要特定的輸入尺寸,這裡使用 416x416
# cv2.dnn.blobFromImage(image, scalefactor, size, mean, swapRB, crop)
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# --- 4. 解讀輸出並進行非極大值抑制 ---
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
# 過濾掉置信度低的預測
if confidence > 0.5:
# 將邊界框座標還原到原始圖片的尺寸
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# 計算左上角的座標
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
# 使用非極大值抑制 (NMS) 來消除多餘的重疊框
# score_threshold: 置信度閾值
# nms_threshold: NMS 的 IoU 閾值
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
# --- 5. 視覺化最終結果 ---
font = cv2.FONT_HERSHEY_PLAIN
colors = np.random.uniform(0, 255, size=(len(classes), 3)) # 為每個類別隨機生成一種顏色
if len(indexes) > 0:
for i in indexes.flatten():
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
confidence = str(round(confidences[i], 2))
color = colors[class_ids[i]]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label + " " + confidence, (x, y + 20), font, 20, color, 20)
cv2.imshow("YOLOv3 Detection", img)
cv2.waitKey(0)
cv2.imwrite("result.jpg", img)
cv2.destroyAllWindows()
結果


 iThome鐵人賽
iThome鐵人賽