昨天,我們幫自動部署加上了 Deployment Protection Rule,多了一顆剎車鍵,避免「手滑 push」就直接炸 production。
今天要來思考另一個問題:
上線之後,怎麼確保服務不只是「活著」,而是「活得健康」?
就像打王時,你不能只看角色血條 > 0,就以為能繼續戰鬥。血條可能還在,但藍條空了、Buff 全掉光,下一 秒就全團滅。
這就是 Observability(可觀測性) 的第一步:從單純的 /healthz,進化到 Metrics。
Q:「健康檢查不是已經夠了嗎?為什麼還要多搞一個 metrics?」
A: 健康檢查只能回答「活著沒死」,metrics 才能回答「狀態好不好」。
在前面,我們已經有 /healthz,會回應 200,保證服務有在跑。
今天再加一個 /metrics,輸出 Prometheus 格式的數據,例如:
http_requests_total 42
app_memory_usage_bytes 12345678
這些數字看似無聊,但一旦丟進監控系統,就是血條、藍條、技能冷卻狀態的完整畫面。
「這些數字看起來亂七八糟,我怎麼知道有什麼用?」
它們就是觀測點。單看沒感覺,但一旦畫成圖表,就能看出流量趨勢、資源壓力,甚至提前預測故障。
pip install prometheus-client
在程式裡掛一個 /metrics,輸出格式讓 Prometheus 可以讀懂。
from prometheus_client import Counter, generate_latest
from flask import Flask, Response, request
app = Flask(__name__)
# 定義一個 Counter
REQUESTS = Counter("http_requests_total", "Total HTTP requests")
@app.before_request
def count_requests():
# 每次有 HTTP request 進來,就把 Counter +1
REQUESTS.inc()
@app.route("/metrics")
def metrics():
return Response(generate_latest(), mimetype="text/plain")
@app.route("/")
def index():
return "Hello Metrics!"
這樣流程才完整:
(i). 宣告一個 Counter → 「角色面板上新增擊殺數欄位」。
(ii). 更新這個 Counter (REQUESTS.inc()) → 「每殺一隻怪就 +1」。
(iii). 輸出 /metrics → 「打開角色面板,顯示目前擊殺數」。
Push 程式碼 → CI build image → GHCR → EC2 拉取 → docker compose up -d。
在 EC2 或瀏覽器打:
curl http://localhost:8000/metrics
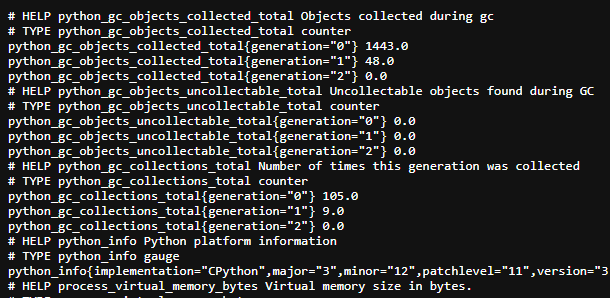
觀測不是只有一種數字,常見的有三類:
Counter(計數器)
只能往上加,例如「請求總數」。
→ 像遊戲角色的擊殺數,只會增加,不會減少。
Gauge(量表)
能上下波動,例如「CPU 使用率」、「記憶體用量」。
→ 像血條和藍條,有時滿、有時空。
Histogram / Summary(分佈統計)
用來量測分佈,例如「請求延遲時間」。
→ 像 Boss 出招頻率表,幾秒一次重擊。
Metrics 本身只是數字,真正的價值在於觸發 告警(Alert)。
「有了 metrics,就能自動告警了嗎?」
「不是,metrics 是原料,告警是成品。今天先學會收集食材,明天才能開始煮菜。」
今天我們不只讓服務喊「我活著」,還能讓它告訴我們「我狀態好不好」。
這是可觀測性的第一步,也是 DevSecOps 的進化方向:
不是只追求快,而是要有能見度。
健康檢查是角色的血條,Metrics 則是完整的角色面板。
只有看見真實狀態,才能打得久、打得穩。

