
大家一路走來應該可以發現我們的系統越來越分散,雖然應用程式的可擴充性大增
但當 App 正式上線時我們會面臨一個問題 我們要怎麼知道它現在的健康狀態?
而在今天透過介紹 Monitoring & Obeservability 我們將會了解系統監控維運在雲原生背景下的基本概念
假設有兩組團隊在維護大型專案:
一個團隊使用自建的機房,運行的是一個單體應用,部署在固定數量的實體伺服器上。問題通常較集中,像是硬體故障或應用程式崩潰,排查範圍相對可控。
而另一個雲原生團隊使用 AWS 雲服務,應用拆分成數十個微服務,運行在 ECS 容器或 Lambda 函數上,並透過 API Gateway、DynamoDB 和 SQS 交互。當延遲或錯誤發生時,問題可能源自某個服務、網路連線,甚至是自動擴展的副作用。
雲原生系統的設計強調分散式架構,採用微服務、容器化(如 Kubernetes)、無伺服器(Serverless)等技術,帶來靈活性和擴展性的同時,也引入了更高的複雜性。與傳統自建機房相比,雲原生環境中的組件數量更多、相互依賴更複雜。
在雲端架構的世界裡,Monitoring(監控) 就像是血壓計,專注於「看數字、抓警報」。它會告訴你系統的表面狀況,比如:
「Lambda 這兩分鐘內跑了五百次」
「DynamoDB 的讀取量突然飆高」
「API Gateway 開始吐了 5xx 錯誤」
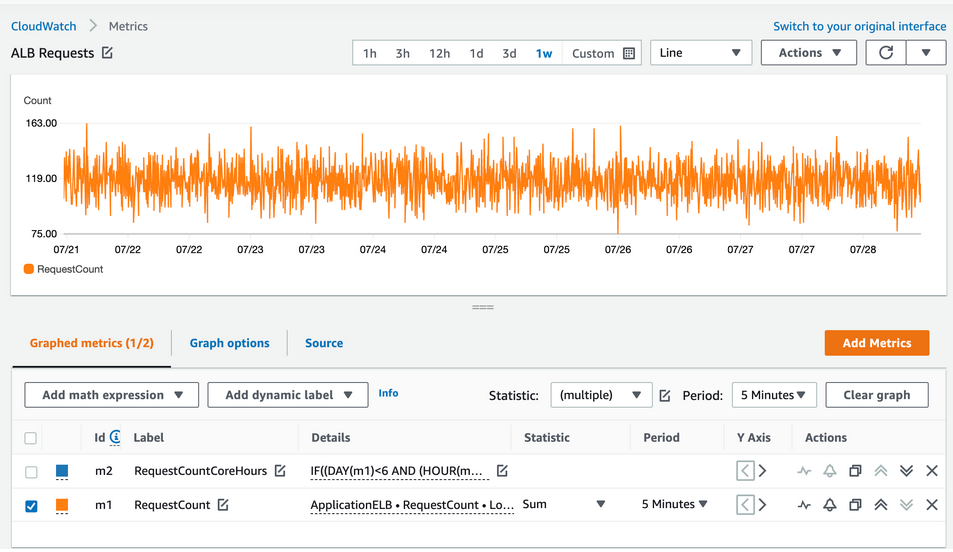
AWS Cloudwatch Metric 追蹤 ALB 的請求次數 取自Enhance CloudWatch metrics with metric math functions
則更進一步,通過整合 Metrics、Logs 和 Traces,提供對系統行為的全面洞察,幫助你快速定位問題根源。例
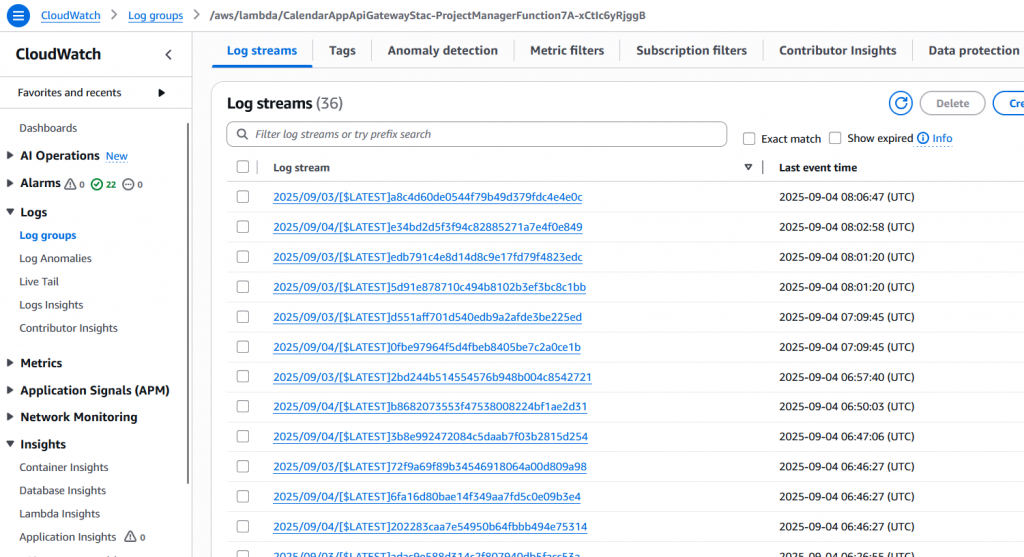
AWS CloudWatch Logs 收集 API Gateway 的實體日誌,並提供 Insight 工具查找異常
| 項目 | Monitoring(監控) | Observability(可觀測性) |
|---|---|---|
| 定義 | 測量並報告系統的關鍵指標(Metrics),確保系統維持正常運作。 | 整合 Metrics、Logs 和 Traces,深入分析分散式系統中的問題根源。 |
| 主要焦點 | 收集資料以識別系統中的異常現象,例如效能下降或錯誤。 | 調查異常現象的根本原因,理解問題的來龍去脈。 |
| 涉及的系統 | 通常針對單一系統或獨立元件進行監控。 | 涵蓋多個互連的系統,特別適用於微服務或分散式架構。 |
| 可追溯性 | 僅限於系統邊緣的指標數據,例如 API 回應時間或錯誤率。 | 支援跨系統的詳細追蹤,透過 Traces 檢視請求在各服務間的流轉路徑。 |
| 系統錯誤調查 | 提供「何時發生」和「發生了什麼」的資訊,例如錯誤發生的時間點及類型。 | 提供「為何發生」和「如何發生」的洞察,例如錯誤的來源、觸發條件及影響範圍。 |
表格參考自 (AWS Document)[https://aws.amazon.com/tw/compare/the-difference-between-monitoring-and-observability/]
儘管可以分別定義 Monitoring 和 Observability 的不同,但其實實務上兩者還是經常交替使用,大多數情況並沒有那麼嚴謹,只需要大概知道概念就可以了。
AWS 在 Serverless 架構下,主要提供了這些工具:
Amazon CloudWatch
AWS X-Ray
CloudTrail
在雲原生監控維運中,開源軟體如 Prometheus(Metrics)、Grafana(視覺化)、ELK Stack(Logs)和 Jaeger(Traces)因其免費、靈活和與雲原生生態(如 Kubernetes)的深度整合而廣受歡迎,特別適合預算有限或需要高度客製化的團隊。例如,Prometheus 可監控 Kubernetes 集群的 Pod 資源使用率,Jaeger 則追蹤微服務間的請求路徑。反之,商業工具如 Datadog、New Relic 或 AWS CloudWatch 提供開箱即用的整合、簡化的部署和企業級支援,適合需要快速上線或管理大規模多雲環境的企業。許多團隊採用混合模式,結合開源工具的彈性與商業工具的便利性,以滿足不同需求。
今天我們簡單介紹了雲原生環境中監控維運的重要性,以及 Monitoring 和 Observability 的核心概念。透過 AWS 的工具(如 CloudWatch、X-Ray)和開源軟體的結合,系統就可以在兼顧可擴充性以及可擴展性的同時控制住維運的複雜度。而在明天我們將會探討一些 AWS 上 可擴展性的 Solutions 敬請期待~

 iThome鐵人賽
iThome鐵人賽