昨天我們建立了 Prometheus 數據收集中心,今天要來打造真正實用的監控面板!我們使用的 kube-prometheus-stack 是業界標準的監控方案,也是 Rancher 監控功能的基礎元件。它整合了 Prometheus Operator、Grafana、AlertManager 等核心組件,提供完整的監控能力。雖然 Helm 管理的 Grafana 設定被「鎖住」無法在 UI 修改,但這反而更適合 GitOps 和團隊協作!

強制透過 Config 調整的優點:
kube-prometheus-stack 監控工作流程: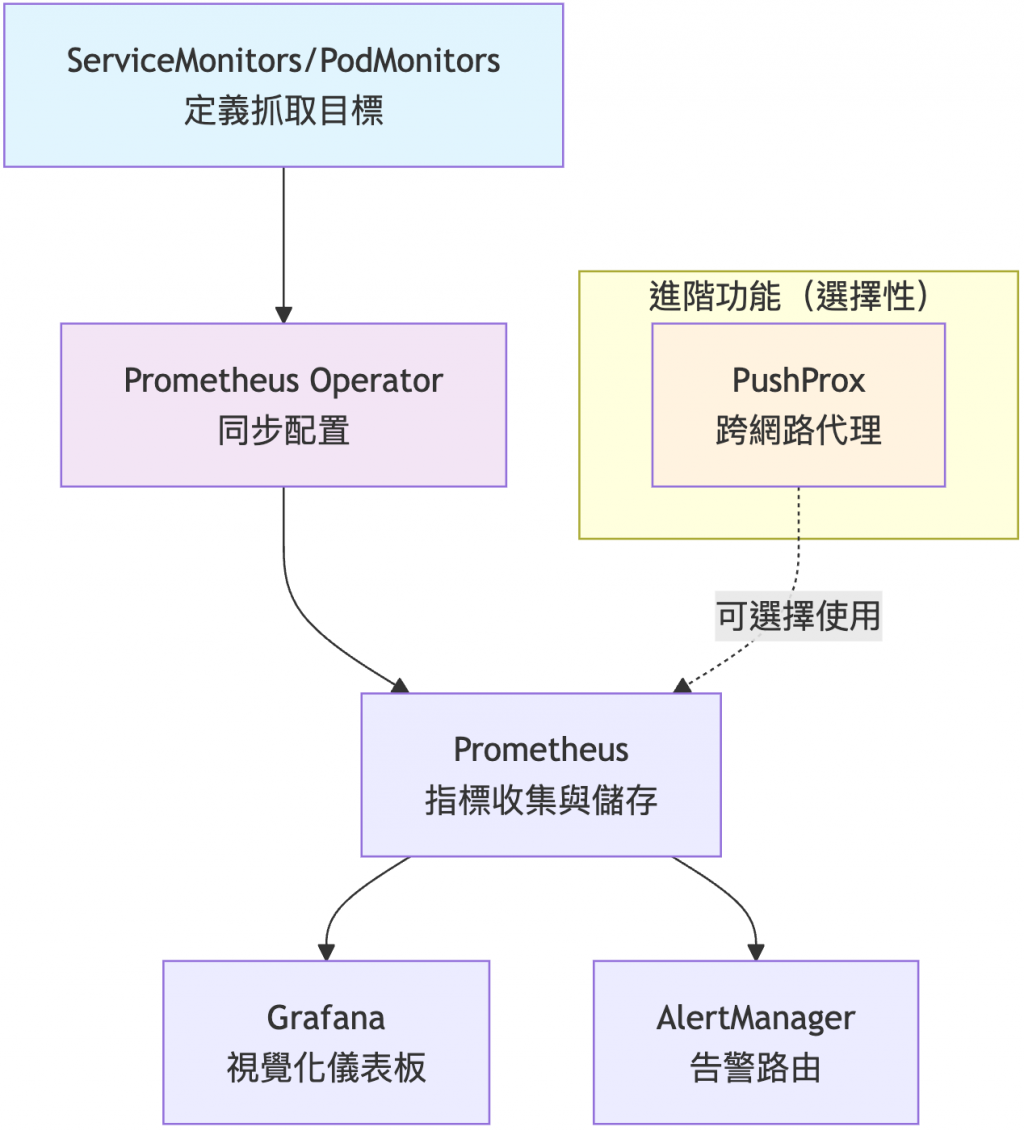
實務操作策略:
社群模板的優缺點:
# 優點:
+ 快速部署(5分鐘 vs 數天)
+ 專家級設計品質
+ 經過大量用戶驗證
+ 美觀的視覺效果
# 缺點:
- 通常不會 100% 符合需求
- 需要微調和客製化
- 可能包含不需要的面板
最佳實務策略:
內建的完整儀表板清單:
核心監控:
AlertManager / Overview - 告警管理總覽Grafana Overview - Grafana 自身監控Kubernetes 資源監控:
Kubernetes / API server - K8s API 伺服器效能Kubernetes / Compute Resources / Cluster - 叢集整體資源Kubernetes / Compute Resources / Namespace (Pods) - 命名空間 Pod 資源Kubernetes / Compute Resources / Node (Pods) - 節點級 Pod 資源Kubernetes / Compute Resources / Pod - 單一 Pod 詳細監控Kubernetes / Kubelet - Kubelet 健康狀態網路監控:
Kubernetes / Networking / Cluster - 叢集網路總覽Kubernetes / Networking / Namespace (Pods) - 命名空間網路流量Kubernetes / Networking / Pod - Pod 網路詳情儲存監控:
Kubernetes / Persistent Volumes - 持久化儲存監控節點系統監控:
Node Exporter / AIX - AIX 系統監控Node Exporter / MacOS - macOS 系統監控DNS 監控:
CoreDNS - 叢集 DNS 解析監控這些都是 mixin 專案維護的生產級品質儀表板,可以直接使用!
# 在 Grafana 中快速找到想要的儀表板
1. 左側選單 → Dashboards → Browse
2. 使用搜尋功能:
- 搜尋 "compute" 找資源使用相關
- 搜尋 "networking" 找網路相關
- 搜尋 "node" 找節點硬體相關
- 搜尋 "api" 找 K8s API 相關
# 推薦的日常監控儀表板
- 叢集總覽:Kubernetes / Compute Resources / Cluster
- 節點監控:Kubernetes / Compute Resources / Node (Pods)
- 故障排查:Kubernetes / Compute Resources / Pod
# 確認 Grafana 服務正在運行
kubectl get pods -n monitoring | grep grafana
# 使用 port-forward 存取(臨時方式)
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80
首次登入:
http://localhost:3000
admin
admin123(我們在 values.yaml 中設定的)資料來源確認:
http://kube-prometheus-stack-prometheus:9090
預設儀表板檢查:
Kubernetes / Compute Resources / Cluster
Node Exporter / Nodes
Kubernetes / Networking / Cluster
重要提醒:RKE2 的 Control Plane 組件可能會顯示 No data:
# 這些儀表板可能缺少資料
- Kubernetes / API server (部分指標)
- etcd 相關監控
- kube-scheduler 監控
- kube-controller-manager 監控
原因分析:
解決方案 - PushProx 代理機制:
# PushProx 是 Prometheus 生態系的開源專案
# https://github.com/prometheus-community/PushProx
# PushProx 架構:
# 1. Client DaemonSet 部署在 host network
# 2. 建立對中央 proxy 的出站連線
# 3. 允許 metrics 收集而不需開放入站埠口
# 4. 解決 NAT/Firewall 環境的監控問題
kube-prometheus-stack 的優勢:
Rancher Monitoring 的本質:
實務建議:
官方儀表板庫:
kubernetes、prometheus、node-exporter
實用建議:
# 最直接的方法
1. 看起來不錯?直接匯入試試看
2. 不合用?刪掉換下一個
3. 覺得太複雜?找簡單一點的
4. 缺少功能?再找個補足的
# 沒什麼標準,就是試用
- 匯入很快,刪除也很快
- 多試幾個自然知道哪個好用
- 適合自己環境的就是最好的
通用匯入流程:
# 在 Grafana UI 中操作
1. 左側選單 → Dashboards → New → Import
2. 輸入方式三選一:
- Dashboard ID (如: 1860)
- 上傳 JSON 檔案
- 貼上 JSON 內容
3. 點擊 Load
4. 設定參數:
- Name: 自訂儀表板名稱
- Folder: 選擇或建立資料夾
- Prometheus: 選擇資料來源
5. 點擊 Import
清理方法:
# 在 Grafana UI 中
1. 左側選單 → Dashboards → Browse
2. 找到不要的儀表板
3. 點擊儀表板 → Settings → Delete dashboard
4. 確認刪除
# 就是這麼簡單
重要限制:Helm 管理的 Grafana 中,無法修改預設儀表板,但可以:
複製儀表板操作:
1. 開啟想要修改的儀表板
2. 點擊右上角的 「齒輪」圖示 → Settings
3. 點擊 "Save As..."
4. 輸入新名稱,例如:"Custom K8s Monitoring"
5. 選擇儲存位置(建議建立 "Custom" 資料夾)
6. 現在可以自由編輯複製的版本
為什麼用 Helm values 而不是 UI 設定?
可以選擇的設定方式:
需要進階設定的話,可以參考官方文件進行 Helm values 調整。
今天我們深入了解了 Helm 管理 Grafana 的實務運用!從 GitOps 友善的配置管理到社群模板的活用,我們建立了實用的監控視覺化體系。
重點回顧:
實務心得:
明天我們要部署完整的 LGTM Stack 統一可觀測性平台,整合 Loki、Mimir、Tempo 到現有的 Grafana 中,讓我們的牧場擁有 Logs、Metrics、Traces 的全方位監控能力!
💡 牧場主小提示:Grafana 的價值在於把複雜的監控數據變成直觀的視覺化資訊!記住:善用社群模板比從零開始效率高很多,IaC 看似麻煩,但對於多人協作的團隊來說是天賜良物。當你能在 5 分鐘內匯入一個專業級儀表板時,你會感謝那些無私分享的社群貢獻者!

