昨天我們建立了漂亮的 Grafana 儀表板,今天要來認識現代可觀測性的終極解決方案 - LGTM Stack!就像現代牧場主需要全方位監控系統來追蹤每頭牛的健康、活動和行為,我們也需要統一的可觀測性平台。今天先從整體架構介紹開始,並部署第一個組件 Loki,讓我們的 Kubernetes 牧場開始收集完整的活動日誌!

LGTM = Loki + Grafana + Tempo + Mimir
這是 Grafana Labs 推出的統一可觀測性解決方案,涵蓋現代 SRE 所需的三大支柱: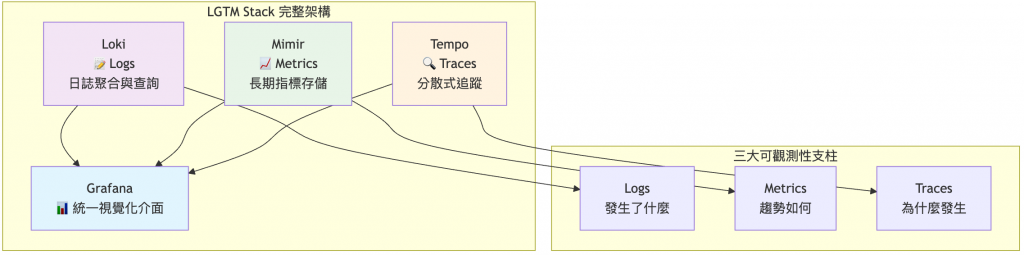
傳統分散式監控:
# 傳統痛點
❌ Prometheus (短期指標) + ELK (日誌) + Jaeger (追蹤)
❌ 三套不同系統,學習成本高
❌ 資料孤島,難以關聯分析
❌ 維護複雜,各自獨立升級
LGTM 統一方案:
# LGTM 優勢
✅ 統一的 Grafana 介面
✅ 一致的查詢體驗
✅ 資料自動關聯
✅ 統一部署和維護
現有環境回顧:
接下來三天的計畫:
Loki 設計哲學:「Like Prometheus, but for logs」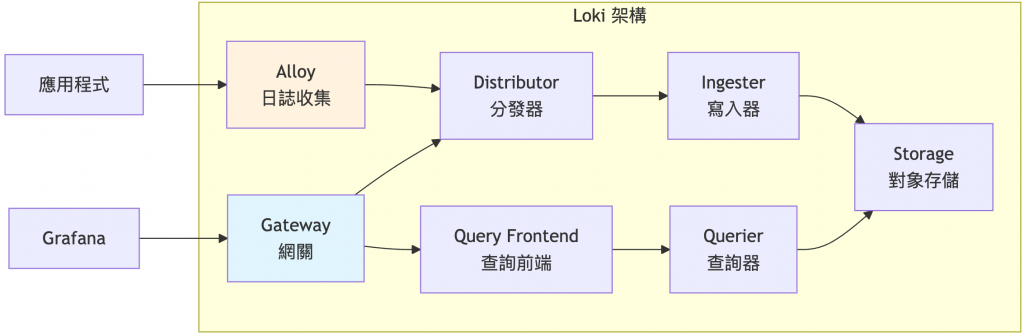
ELK = Elasticsearch + Logstash + Kibana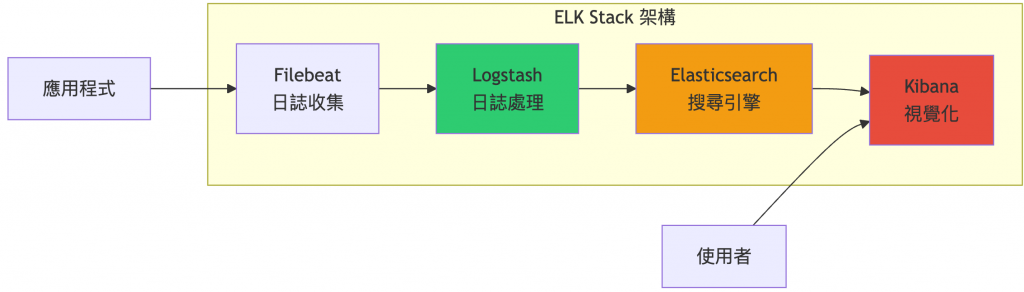
ELK 的技術特性:
| 技術面向 | Loki | ELK Stack |
|---|---|---|
| 索引策略 | 只索引 Labels (metadata) | 全文索引 (Full-text Index) |
| 搜尋機制 | 標籤過濾 + grep 模式匹配 | 基於 Lucene 的複雜查詢 |
| 儲存格式 | 日誌流壓縮儲存 | JSON 文檔存儲 |
| 磁碟使用 | 較低 (高壓縮率) | 較高 (索引開銷) |
| 記憶體需求 | 較低 | 較高 |
| 查詢語法 | LogQL (類似 PromQL) | KQL/DSL (複雜查詢語言) |
| 擴展方式 | 水平擴展各微服務 | 分片 (Sharding) 機制 |
| 運維複雜度 | 較簡單 | 較複雜 |
Loki 的 Label-Only 索引:
# Loki 只索引這些標籤
labels:
namespace: "kube-system"
pod: "coredns-12345"
container: "coredns"
level: "info"
# 日誌內容不建索引,使用 grep 風格搜尋
content: "2024-01-01 10:00:00 INFO: DNS query processed"
ELK 的全文索引:
{
"@timestamp": "2024-01-01T10:00:00Z",
"namespace": "kube-system",
"pod": "coredns-12345",
"message": "DNS query processed",
"_index": {
"DNS": ["dns", "query"],
"query": ["query", "processed"],
"processed": ["processed"]
}
}
Loki 的成本優勢:
ELK 的資源需求:
Loki LogQL 範例:
# 簡潔直觀,類似 PromQL
{namespace="kube-system"}
|= "error"
| rate[5m]
# 日誌聚合統計
sum by (pod) (
rate({namespace="kube-system"} |= "error" [5m])
)
ELK KQL/DSL 範例:
{
"query": {
"bool": {
"must": [
{"match": {"namespace": "kube-system"}},
{"match": {"message": "error"}}
],
"filter": {
"range": {
"@timestamp": {
"gte": "now-5m"
}
}
}
}
},
"aggs": {
"errors_by_pod": {
"terms": {"field": "pod"}
}
}
}
選擇 Loki 的場景:
✅ 成本敏感的環境
✅ 已有 Prometheus + Grafana
✅ 主要做故障排查和趨勢分析
✅ 團隊熟悉 PromQL 語法
✅ 需要長期日誌保存
✅ 雲端原生環境
選擇 ELK 的場景:
✅ 需要複雜的全文搜尋
✅ 業務分析和報表需求
✅ 需要豐富的視覺化選項
✅ 已有大量 ELK 運維經驗
✅ 合規要求詳細的日誌分析
✅ 不在意成本和複雜度
架構優勢:
生態整合:
運維友善:
# 檢查現有環境
kubectl get pods -n monitoring | grep grafana
kubectl get svc -n monitoring
# 添加 Grafana Helm Repository
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
# 檢視 LGTM Stack 版本
helm search repo grafana/lgtm-distributed
建立適合實驗環境的 LGTM Stack 配置(只啟用 Loki):
# 建立 lgtm-values.yaml
cat > lgtm-values.yaml << 'EOF'
# LGTM Stack 配置 - 只啟用 Loki
grafana:
# 關鍵:不部署新的 Grafana,使用現有的
enabled: false
# Loki 日誌系統配置
loki:
enabled: true
# 針對實驗環境的資源配置
loki:
auth_enabled: false
commonConfig:
replication_factor: 1
storage:
type: filesystem
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
# Gateway 配置
gateway:
enabled: true
replicas: 1
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
# 修正 RKE2 的 DNS resolver 問題
nginxConfig:
resolver: "10.43.0.10" # RKE2 CoreDNS IP
# Backend (Write Path)
backend:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
# Read 組件
read:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
# Write 組件
write:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
# Mimir 指標存儲系統(暫時 disable)
mimir:
enabled: false
# Tempo 分散式追蹤系統(暫時 disable)
tempo:
enabled: false
# Grafana OnCall(不需要)
grafana-oncall:
enabled: false
EOF
# 建立 namespace
kubectl create namespace lgtm-stack
# 部署 LGTM Stack(只啟用 Loki)
helm install lgtm-stack grafana/lgtm-distributed \
-n lgtm-stack \
-f lgtm-values.yaml
# 檢查部署狀態
kubectl get pods -n lgtm-stack -w
預期結果:
NAME READY STATUS
lgtm-stack-loki-gateway-xxx 1/1 Running
lgtm-stack-loki-backend-xxx 1/1 Running
lgtm-stack-loki-read-xxx 1/1 Running
lgtm-stack-loki-write-xxx 1/1 Running
為什麼選擇 Alloy?
環境準備:
# 添加 Grafana Helm Repository(如果還沒有的話)
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
# 建立 alloy-values.yaml
cat > alloy-values.yaml << 'EOF'
# Alloy 配置 - 專門用於日誌收集
alloy:
configMap:
content: |
// Kubernetes Service Discovery
discovery.kubernetes "pods" {
role = "pod"
}
// 日誌收集規則
loki.source.kubernetes "pods" {
targets = discovery.kubernetes.pods.targets
forward_to = [loki.process.pods.receiver]
}
// 日誌處理管道
loki.process "pods" {
forward_to = [loki.write.default.receiver]
stage.static_labels {
values = {
cluster = "rancher-custom",
}
}
// 解析日誌等級
stage.regex {
expression = "(?i)(?P<level>debug|info|warn|error|fatal)"
}
stage.labels {
values = {
level = "",
}
}
}
// 發送到 Loki
loki.write "default" {
endpoint {
url = "http://lgtm-stack-loki-gateway.lgtm-stack.svc.cluster.local/loki/api/v1/push"
}
}
# 啟用日誌收集相關的 mount
mounts:
varlog: true
dockercontainers: true
# Controller 配置
controller:
type: daemonset # 在每個節點運行
# RBAC 配置
rbac:
create: true
# Service Account 配置
serviceAccount:
create: true
EOF
# 部署 Alloy 到 lgtm-stack namespace
helm install alloy grafana/alloy \
--version 1.2.1 \
-n lgtm-stack \
-f alloy-values.yaml
# 檢查部署狀態
kubectl get pods -n lgtm-stack | grep alloy
預期結果:
NAME READY STATUS
alloy-xxxxx 2/2 Running # 每個節點一個 Pod
# 存取 Grafana
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80
# 測試 Loki 連線
kubectl port-forward -n lgtm-stack svc/lgtm-stack-loki-gateway 3100:80 &
curl http://localhost:3100/ready
curl http://localhost:3100/
透過 Helm values 配置資料來源:
更新現有的 prometheus-values.yaml 文件,在 grafana 區段添加 Loki 資料來源:
# 在現有的 grafana 區段中添加 additionalDataSources
grafana:
# 保持現有設定...
adminPassword: "admin123"
persistence:
enabled: true
size: 5Gi
# 新增 Loki 資料來源
additionalDataSources:
- name: Loki
type: loki
url: http://lgtm-stack-loki-gateway.lgtm-stack.svc.cluster.local
access: proxy
isDefault: false
editable: true
jsonData:
maxLines: 1000
升級 Prometheus Stack 配置:
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack \
-n monitoring \
-f prometheus-values.yaml
在 Grafana Explore 中測試以下查詢:
重要:確保在 Explore 中選擇 Loki 資料來源,並將時間範圍設為「Last 5 minutes」。
# 查看所有日誌(使用我們配置的 cluster 標籤)
{cluster="rancher-custom"}
# 查看特定服務的日誌(使用 instance 標籤)
{cluster="rancher-custom"} |= "cattle-system"
# 查看錯誤日誌
{cluster="rancher-custom", level="Error"}
# 查看 Alloy 本身的日誌
{cluster="rancher-custom"} |= "alloy"
# 查看特定 Pod 的日誌
{cluster="rancher-custom"} |= "fleet-agent"
# 使用正規表達式過濾
{cluster="rancher-custom"} |~ "error|failed"
如果查不到結果,請檢查:
kubectl logs -n lgtm-stack daemonset/alloy --tail=5
# 檢查 Alloy Pods
kubectl get pods -n lgtm-stack | grep alloy
# 檢查 Alloy 日誌
kubectl logs -n lgtm-stack daemonset/alloy
# 檢查 Alloy metrics
kubectl port-forward -n lgtm-stack daemonset/alloy 12345:12345
curl http://localhost:12345/metrics | grep loki
今天我們深入認識了 LGTM Stack 的完整架構,並成功部署了第一個組件 - Loki 日誌聚合系統!透過現代化的 Grafana Alloy 收集器,我們的 Kubernetes 牧場現在能夠收集完整的活動日誌,並整合到現有的 Grafana 中查看。
重點回顧:
明天我們要部署 Mimir,讓它作為 Prometheus 的長期指標儲存後端,解決 Prometheus 本地儲存的限制,真正實現企業級的指標管理!
💡 牧場主小提示:LGTM Stack 的威力在於統一體驗,但部署策略要靈活!分階段部署讓你每一步都看得到效果,避免一次性部署的複雜性。Alloy 作為 Promtail 的替代方案值得關注,多了解不同工具的特性總是好事!

