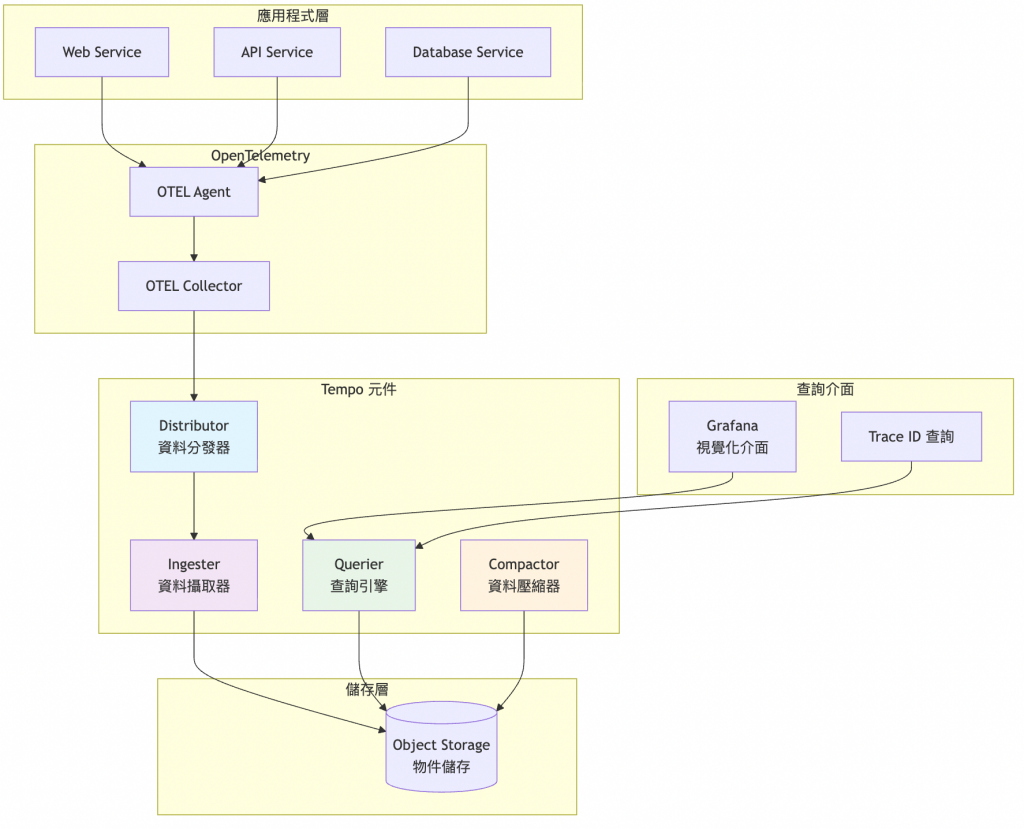
昨天我們成功部署了 Mimir 長期指標儲存系統,現在牧場的指標資料可以安全地存放在倉庫裡了!今天牧場主要來建設新的基礎設施:Tempo 分散式追蹤系統。如果說指標是牧場的體溫計,日誌是牧場的日記本,那麼追蹤就是牧場的監控雷達 - 今天我們先把雷達基站架設好,明天再教每頭牛如何發送定位信號!
在現代微服務架構中,一個用戶請求可能會經過十幾個不同的服務才完成。就像牧場裡的一頭牛可能要經過:入口閘道→健康檢查→飼料配給→清潔服務→記錄系統等多個環節。
分散式追蹤系統能夠:

修改我們的 lgtm-values.yaml,啟用 Tempo 元件:
# Tempo 分散式追蹤系統
tempo:
enabled: true
# Tempo 核心配置
tempo:
# 多租戶設定(實驗環境關閉)
multitenancy_enabled: false
# 儲存配置
storage:
backend: filesystem
filesystem:
path: /var/tempo
# 資料攝取限制
ingestion:
# 每秒最大 span 數量
rate_limit_bytes: 15000000
# 每個追蹤的最大 span 數量
max_spans_per_trace: 50000
# 資料保留設定
retention_period: 24h
# 壓縮配置
compactor:
# 每 2 小時執行一次壓縮
compaction_window: 2h
# 保留最近 4 小時的資料在快取中
retention_concurrency: 20
# 查詢限制
query_frontend:
# 查詢並發數限制
max_outstanding_per_tenant: 100
# 單次查詢最大時間範圍
max_query_length: 24h
# === Tempo 各元件配置 ===
# Distributor:接收追蹤資料並分發
distributor:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
config:
receivers:
jaeger:
protocols:
grpc:
endpoint: 0.0.0.0:14250
thrift_http:
endpoint: 0.0.0.0:14268
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
# Ingester:短期儲存和批次寫入
ingester:
replicas: 1
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
# 持久化儲存配置
persistence:
enabled: true
size: 5Gi
# Querier:處理查詢請求
querier:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
# Compactor:資料壓縮和清理
compactor:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 200m
memory: 512Mi
# Query Frontend:查詢優化和快取
query_frontend:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 200m
memory: 512Mi
# Gateway:統一入口點
gateway:
enabled: true
replicas: 1
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
# RKE2 DNS 解析器配置
nginxConfig:
resolver: rke2-coredns-rke2-coredns.kube-system.svc.cluster.local.
在 prometheus-values.yaml 中添加 Tempo 資料來源:
grafana:
adminPassword: "admin123"
persistence:
enabled: true
size: 5Gi
additionalDataSources:
- name: Loki
type: loki
url: http://lgtm-stack-loki-gateway.lgtm-stack.svc.cluster.local
access: proxy
isDefault: false
editable: true
jsonData:
maxLines: 1000
- name: Mimir
type: prometheus
url: http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/prometheus
access: proxy
isDefault: false
editable: true
jsonData:
httpMethod: POST
timeInterval: "30s"
# 新增 Tempo 資料來源
- name: Tempo
type: tempo
url: http://lgtm-stack-tempo-gateway.lgtm-stack.svc.cluster.local
access: proxy
isDefault: false
editable: true
jsonData:
# 啟用資料來源間的關聯查詢
tracesToLogsV2:
datasourceUid: 'loki' # 連接到 Loki 資料來源
spanStartTimeShift: '-1h'
spanEndTimeShift: '1h'
filterByTraceID: true
filterBySpanID: true
tracesToMetrics:
datasourceUid: 'mimir' # 連接到 Mimir 資料來源
spanStartTimeShift: '-1h'
spanEndTimeShift: '1h'
tags:
- key: 'service.name'
value: 'service_name'
serviceMap:
datasourceUid: 'mimir'
# 更新 LGTM Stack
helm upgrade lgtm-stack grafana/lgtm-distributed -n lgtm-stack -f lgtm-values.yaml
# 更新 Prometheus Stack(包含 Grafana 資料來源)
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring -f prometheus-values.yaml
# 檢查 Tempo 相關 Pods
kubectl get pods -n lgtm-stack -l app.kubernetes.io/component=distributor
kubectl get pods -n lgtm-stack -l app.kubernetes.io/component=ingester
kubectl get pods -n lgtm-stack -l app.kubernetes.io/component=querier
# 檢查服務端點
kubectl get svc -n lgtm-stack | grep tempo
# 檢查 Tempo 元件日誌
kubectl logs -n lgtm-stack -l app.kubernetes.io/component=distributor --tail=50
# 檢查所有 Tempo 元件是否正常運行
kubectl get pods -n lgtm-stack -l app.kubernetes.io/name=tempo
# 檢查服務端點
kubectl get svc -n lgtm-stack | grep tempo
預期結果:
Running
重要:現階段無法進行功能測試,實際的追蹤功能驗證需要等到 Day 27 有應用程式發送追蹤資料後才能進行。
今天我們成功部署了 Tempo 分散式追蹤系統的基礎設施,為我們的 LGTM 可觀測性堆疊增加了第三個重要組件!牧場的追蹤雷達基站已經架設完成,所有組件都正常運行。
今日重點成果:
明天我們將進入實戰階段:Day 27 Alloy 追蹤整合實戰!我們將擴展現有的 Alloy 配置,讓它不只收集日誌,還能接收應用程式的追蹤資料並轉發到 Tempo。包括 OpenTelemetry 的概念、實際的程式碼整合範例,以及如何在 Grafana 中查看和分析追蹤資料。雷達基站已經準備好了,明天我們來教每頭牛如何透過統一的 Alloy 收集器發送定位信號!
💡 牧場主小提示:建設基礎設施就像搭建牧場的圍欄和基礎設施,雖然看起來沒有立即的效果,但這是後續所有功能的基礎。今天我們搭好了追蹤系統的骨架,明天就能讓它真正發揮作用!記住,穩固的基礎是成功的一半。

