昨天我們成功搭建了 Tempo 追蹤雷達基站,所有設備都已就緒並正常運行!今天牧場主要展示 Alloy 這個萬能收集器的真正實力。我們已經讓 Alloy 收集日誌了,現在要擴展它的能力,讓它同時處理追蹤和指標資料。就像訓練一個全能的牧場助手,不只會放牧,還會檢查健康、記錄活動,並且統一回報給管理中心!

Alloy 本質上就是 OpenTelemetry Collector 的一個商業級實作,由 Grafana 開發。它完全相容 OpenTelemetry 標準,同時提供了:
傳統多組件分散架構: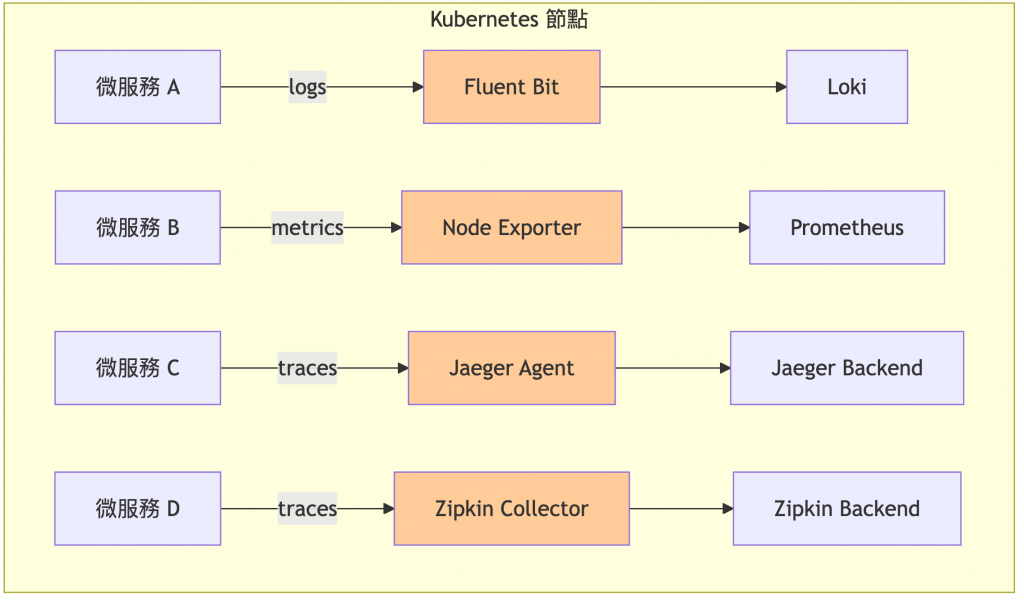
Alloy 統一收集架構: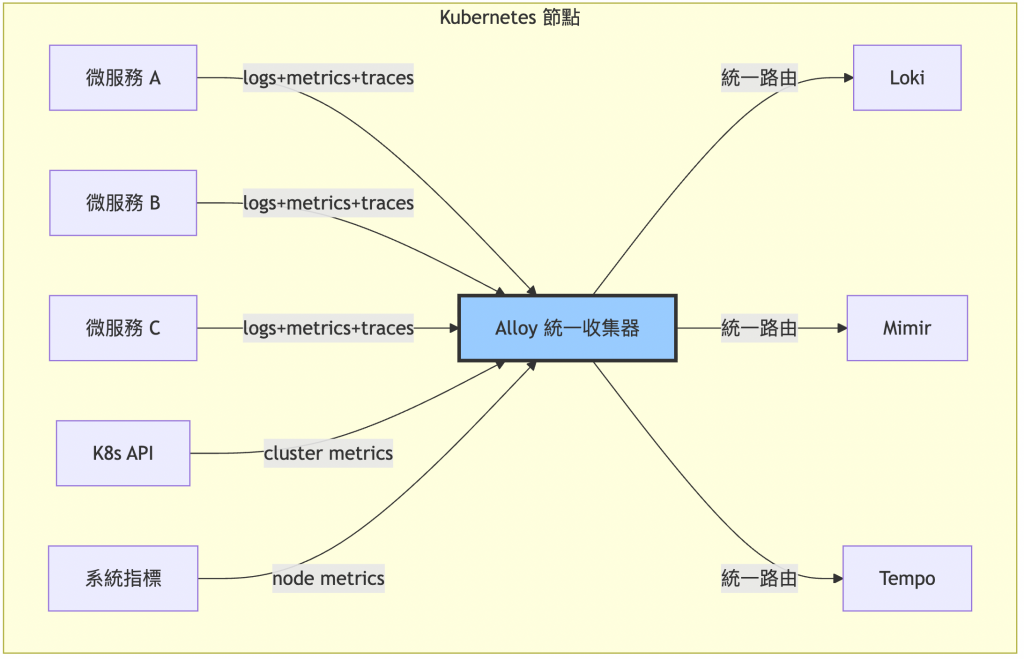
雖然我們不使用 OpenTelemetry Collector,但 OpenTelemetry 的資料格式和概念仍然重要,因為它是可觀測性的業界標準。
OpenTelemetry (OTEL) 是 CNCF 的開源可觀測性框架:
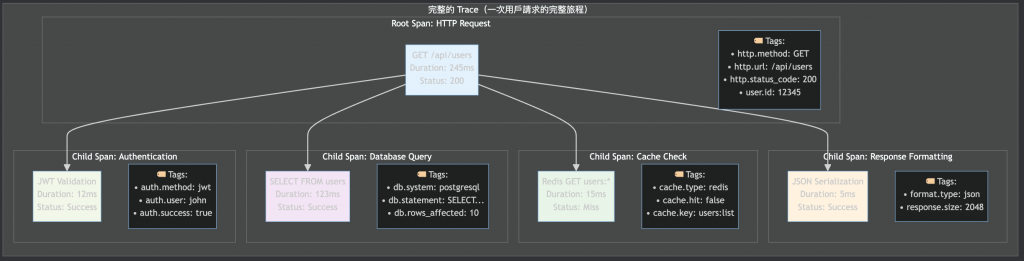
核心概念說明:
現在讓我們擴展現有的 Alloy 配置,加上追蹤和指標收集功能。
首先確認 Alloy 正常運行:
# 檢查 Alloy 狀態
kubectl get pods -n lgtm-stack -l app.kubernetes.io/name=alloy
# 檢查當前配置
kubectl get configmap alloy -n lgtm-stack -o yaml
我們需要擴展 alloy-values.yaml,從單純的日誌收集器變成統一的可觀測性收集器。主要新增內容:
🔧 關鍵擴展項目:
指標收集能力:
# 新增系統指標收集
prometheus.exporter.unix "default" {}
prometheus.scrape "node_exporter" { ... }
prometheus.scrape "kubelet" { ... }
prometheus.remote_write "mimir" { ... }
追蹤收集能力:
# 新增 OTLP 追蹤接收器
otelcol.receiver.otlp "default" {
grpc { endpoint = "0.0.0.0:4317" }
http { endpoint = "0.0.0.0:4318" }
}
otelcol.exporter.otlphttp "default" { ... }
Service 端口擴展:
# 新增 OTLP 追蹤端口
extraPorts:
- name: "otlp-grpc" # OpenTelemetry gRPC 端口
port: 4317
- name: "otlp-http" # OpenTelemetry HTTP 端口
port: 4318
創建完整的 alloy-values.yaml 配置檔案:
# Alloy 配置 - 統一可觀測性收集器(日誌、指標、追蹤)
alloy:
configMap:
content: |
// ================================================================
// Kubernetes 服務發現配置
// 功能:自動發現集群中的 Pods、節點和服務
// ================================================================
discovery.kubernetes "pods" {
role = "pod" // 發現所有 Pod
}
discovery.kubernetes "nodes" {
role = "node" // 發現所有節點
}
discovery.kubernetes "services" {
role = "service" // 發現所有服務
}
// ================================================================
// 日誌收集配置(保持現有功能)
// ================================================================
// 收集 Kubernetes Pod 日誌
loki.source.kubernetes "pods" {
targets = discovery.kubernetes.pods.targets
forward_to = [loki.process.pods.receiver]
}
// 日誌處理管道
loki.process "pods" {
forward_to = [loki.write.default.receiver]
// 添加集群標籤
stage.static_labels {
values = {
cluster = "rancher-cluster",
environment = "development",
}
}
// 解析日誌等級
stage.regex {
expression = "(?i)(?P<level>debug|info|warn|error|fatal)"
}
stage.labels {
values = {
level = "",
}
}
}
// 發送日誌到 Loki
loki.write "default" {
endpoint {
url = "http://lgtm-stack-loki-gateway.lgtm-stack.svc.cluster.local/loki/api/v1/push"
}
}
// ================================================================
// 指標收集配置
// ================================================================
// 收集節點系統指標
prometheus.scrape "node_exporter" {
targets = prometheus.exporter.unix.default.targets
forward_to = [prometheus.remote_write.mimir.receiver]
}
// 啟用節點指標收集器
prometheus.exporter.unix "default" {
// 收集基礎系統指標:CPU、記憶體、磁碟、網路等
}
// 收集 Kubernetes 相關指標
prometheus.scrape "kubelet" {
targets = discovery.kubernetes.nodes.targets
forward_to = [prometheus.remote_write.mimir.receiver]
// Kubelet 指標端點配置
metrics_path = "/metrics"
scheme = "https"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
}
// 收集容器指標(cAdvisor)
prometheus.scrape "cadvisor" {
targets = discovery.kubernetes.nodes.targets
forward_to = [prometheus.remote_write.mimir.receiver]
// cAdvisor 指標端點配置
metrics_path = "/metrics/cadvisor"
scheme = "https"
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
tls_config {
insecure_skip_verify = true
}
}
// 發送指標到 Mimir
prometheus.remote_write "mimir" {
endpoint {
url = "http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/api/v1/push"
}
// 添加全域標籤
external_labels = {
cluster = "rancher-cluster",
environment = "development",
}
}
// ================================================================
// 追蹤收集配置
// ================================================================
// 接收 OTLP gRPC 追蹤資料
otelcol.receiver.otlp "default" {
grpc {
endpoint = "0.0.0.0:4317" // OTLP gRPC 端口
}
http {
endpoint = "0.0.0.0:4318" // OTLP HTTP 端口
}
output {
traces = [otelcol.processor.batch.default.input]
}
}
// 批次處理器 - 提升傳輸效率
otelcol.processor.batch "default" {
timeout = "1s"
send_batch_size = 1024
output {
traces = [otelcol.processor.attributes.default.input]
}
}
// 屬性處理器 - 添加集群資訊
otelcol.processor.attributes "default" {
action {
key = "cluster.name"
value = "rancher-cluster"
action = "upsert"
}
action {
key = "environment"
value = "development"
action = "upsert"
}
output {
traces = [otelcol.exporter.otlphttp.default.input]
}
}
// 追蹤資料輸出到 Tempo (直接使用 Gateway)
otelcol.exporter.otlphttp "default" {
client {
endpoint = "http://lgtm-stack-tempo-gateway.lgtm-stack.svc.cluster.local:80"
tls {
insecure = true
}
}
}
# 啟用日誌收集相關的 mount
mounts:
varlog: true
dockercontainers: true
# 開放追蹤收集所需的額外端口
extraPorts:
- name: "otlp-grpc" # OTLP gRPC 端口
port: 4317
targetPort: 4317
protocol: "TCP"
- name: "otlp-http" # OTLP HTTP 端口
port: 4318
targetPort: 4318
protocol: "TCP"
# Controller 配置
controller:
type: daemonset # 在每個節點運行
# RBAC 配置
rbac:
create: true
# Service Account 配置
serviceAccount:
create: true
使用 Helm 升級來套用新的 Alloy 統一收集配置:
# 使用 Helm 升級 Alloy 配置
helm upgrade alloy grafana/alloy -n lgtm-stack -f alloy-values.yaml
# 檢查新的 Pod 狀態
kubectl get pods -n lgtm-stack -l app.kubernetes.io/name=alloy
檢查 Alloy 是否正確載入統一收集配置:
# 檢查 Pod 端口配置(應該看到 4317, 4318 等追蹤端口)
kubectl describe pod -n lgtm-stack -l app.kubernetes.io/name=alloy | grep -A 15 "Ports:"
# 檢查 Alloy 啟動日誌,確認各個收集器都正常啟動
kubectl logs -n lgtm-stack -l app.kubernetes.io/name=alloy --tail=30 | grep -E "(started|receiver|exporter)"
# 檢查 Service 端口配置(Helm 自動配置的端口)
kubectl describe svc alloy -n lgtm-stack
測試 Alloy 統一收集的三個資料類型:
# 1. 驗證指標收集:檢查 Mimir 中的 node 指標
kubectl port-forward -n lgtm-stack svc/lgtm-stack-mimir-nginx 9009:80 &
curl -s "http://localhost:9009/prometheus/api/v1/label/__name__/values" | jq '.data[]' | grep node_ | head -5
# 2. 驗證日誌收集:檢查 Loki 中的標籤
kubectl port-forward -n lgtm-stack svc/lgtm-stack-loki-gateway 3100:80 &
curl -s "http://localhost:3100/loki/api/v1/labels" | jq '.data'
# 3. 檢查 Alloy OTLP 追蹤端口是否就緒
kubectl get svc alloy -n lgtm-stack | grep -E "(4317|4318)"
為什麼需要追蹤產生器?
追蹤產生器是一個測試工具,用來:
現在部署一個簡單的追蹤產生器來測試我們的 Alloy 可觀測性管線:
kubectl apply -f - <<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: ranch-trace-generator
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: ranch-trace-generator
template:
metadata:
labels:
app: ranch-trace-generator
spec:
containers:
- name: generator
image: curlimages/curl:latest
command: ["/bin/sh"]
args:
- "-c"
- |
while true; do
echo "發送追蹤資料到 Alloy..."
TRACE_ID=$(head -c 1000 /dev/urandom | tr -dc 'a-f0-9' | fold -w 32 | head -n 1)
SPAN_ID=$(head -c 1000 /dev/urandom | tr -dc 'a-f0-9' | fold -w 16 | head -n 1)
TIMESTAMP_NS=$(($(date +%s) * 1000000000))
# 使用 sh 相容的隨機選擇方式
RAND_NUM=$(( $(date +%s) % 5 ))
case $RAND_NUM in
0) OPERATION="餵食作業"; ANIMAL="乳牛"; ZONE="A區"; WORKER="worker-1" ;;
1) OPERATION="健康檢查"; ANIMAL="肉牛"; ZONE="B區"; WORKER="worker-2" ;;
2) OPERATION="清潔工作"; ANIMAL="羊群"; ZONE="C區"; WORKER="worker-3" ;;
3) OPERATION="動物計數"; ANIMAL="雞群"; ZONE="隔離區"; WORKER="worker-4" ;;
*) OPERATION="疫苗接種"; ANIMAL="豬群"; ZONE="醫療區"; WORKER="worker-5" ;;
esac
curl -X POST http://alloy.lgtm-stack.svc.cluster.local:4318/v1/traces \
-H "Content-Type: application/json" \
-d "{
\"resourceSpans\": [{
\"resource\": {
\"attributes\": [{
\"key\": \"service.name\",
\"value\": {\"stringValue\": \"ranch-management-system\"}
}, {
\"key\": \"service.version\",
\"value\": {\"stringValue\": \"2.0.0\"}
}, {
\"key\": \"deployment.environment\",
\"value\": {\"stringValue\": \"development\"}
}]
},
\"scopeSpans\": [{
\"scope\": {\"name\": \"ranch-instrumentation\", \"version\": \"1.0.0\"},
\"spans\": [{
\"traceId\": \"${TRACE_ID}\",
\"spanId\": \"${SPAN_ID}\",
\"name\": \"${OPERATION}\",
\"kind\": 1,
\"startTimeUnixNano\": \"${TIMESTAMP_NS}\",
\"endTimeUnixNano\": \"$((TIMESTAMP_NS + 2000000000))\",
\"attributes\": [{
\"key\": \"ranch.operation.type\",
\"value\": {\"stringValue\": \"${OPERATION}\"}
}, {
\"key\": \"ranch.animal.type\",
\"value\": {\"stringValue\": \"${ANIMAL}\"}
}, {
\"key\": \"ranch.worker.id\",
\"value\": {\"stringValue\": \"${WORKER}\"}
}, {
\"key\": \"ranch.area.zone\",
\"value\": {\"stringValue\": \"${ZONE}\"}
}],
\"status\": {\"code\": 1}
}]
}]
}]
}" \
--max-time 5 --connect-timeout 3
if [ $? -eq 0 ]; then
echo "牧場作業追蹤 - 操作:$OPERATION, 動物:$ANIMAL, 區域:$ZONE, 工作者:$WORKER"
else
echo "追蹤資料發送失敗,30秒後重試..."
fi
sleep 30
done
resources:
requests:
cpu: 10m
memory: 32Mi
limits:
cpu: 50m
memory: 64Mi
---
# 部署一個簡單的測試服務
apiVersion: apps/v1
kind: Deployment
metadata:
name: ranch-demo-service
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: ranch-demo-service
template:
metadata:
labels:
app: ranch-demo-service
spec:
containers:
- name: service
image: nginx:alpine
ports:
- containerPort: 80
env:
# 模擬 OpenTelemetry 環境變數配置
- name: OTEL_SERVICE_NAME
value: "ranch-web-service"
- name: OTEL_SERVICE_VERSION
value: "1.0.0"
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://alloy.lgtm-stack.svc.cluster.local:4318"
- name: OTEL_RESOURCE_ATTRIBUTES
value: "deployment.environment=development,service.namespace=ranch"
resources:
requests:
cpu: 20m
memory: 64Mi
---
apiVersion: v1
kind: Service
metadata:
name: ranch-demo-service
namespace: default
spec:
selector:
app: ranch-demo-service
ports:
- port: 80
targetPort: 80
EOF
部署完成後,我們需要驗證追蹤資料是否成功從應用程式→ Alloy → Tempo 的完整流程。
# 檢查 Alloy 是否正常運行
echo "=== Alloy Pod 狀態 ==="
kubectl get pods -n lgtm-stack -l app.kubernetes.io/name=alloy
# 檢查追蹤產生器是否正常運行
echo "=== 追蹤產生器狀態 ==="
kubectl get pods -n default -l app=ranch-trace-generator
# 檢查 Tempo 服務狀態
echo "=== Tempo 服務狀態 ==="
kubectl get pods -n lgtm-stack -l app.kubernetes.io/name=tempo
# 測試 OTLP HTTP 端口連接性
kubectl port-forward -n lgtm-stack svc/alloy 4318:4318 &
PF_PID=$!
sleep 2
curl -v "http://localhost:4318/v1/traces" -X POST -H "Content-Type: application/json" -d '{"test": "connectivity"}' --max-time 3
kill $PF_PID 2>/dev/null
# 預期看到:
# - "Connected to localhost" - 連接建立成功
# - "HTTP/1.1 200 OK" - OTLP 接收器正常回應
# - {"partialSuccess":{}} - OTLP 標準回應格式
# 查看追蹤產生器是否正常發送資料
kubectl logs -n default -l app=ranch-trace-generator --tail=10
# 預期輸出類似:
# 發送追蹤資料到 Alloy...
# 牧場作業追蹤 - 操作:餵食作業, 動物:乳牛, 區域:A區, 工作者:worker-1
# 檢查 Alloy 是否收到並嘗試轉發追蹤資料
kubectl logs -n lgtm-stack -l app.kubernetes.io/name=alloy --tail=30 | grep -E "(started|receiver|exporter)"
# 預期看到類似(這是正常行為):
# 日誌收集正常:"opened log stream" component_id=loki.source.kubernetes.pods
# 追蹤轉發嘗試:"component":"otelcol.exporter.otlphttp.default"..."Exporting failed"
# 重試機制運作:"Will retry the request after interval"
# 透過 port-forward 測試 Tempo Gateway 連線
kubectl port-forward -n lgtm-stack svc/lgtm-stack-tempo-gateway 3200:80 &
PF_PID=$!
sleep 3
# 測試 Tempo Gateway 是否回應
echo "=== 測試 Tempo Gateway 連線 ==="
curl -s "http://localhost:3200/" && echo " - Gateway 正常回應"
# 測試 Tempo API 端點
echo "=== 測試 Tempo API 端點 ==="
curl -s "http://localhost:3200/api/echo" && echo " - API 端點正常"
# 清理 port-forward
kill $PF_PID 2>/dev/null
如果你已經設定好 Grafana(來自 Day 23),可以:
登入 Grafana:
kubectl port-forward -n monitoring svc/kube-prometheus-stack-grafana 3000:80
# 瀏覽器開啟:http://localhost:3000
檢查 Tempo 資料源:
http://lgtm-stack-tempo-gateway.lgtm-stack.svc.cluster.local:80
正常的驗證結果:
otelcol.receiver.otlp.default 收到資料otelcol.exporter.otlphttp.default 嘗試發送關於 "Exporting failed" 訊息:
這是完全正常的行為! 原因:
/otlp/v1/traces 端點返回 504 Gateway TimeoutWill retry the request after interval
loki.source.kubernetes.pods) 和指標收集正常工作重點成就:
今天我們成功將 Alloy 升級為統一的可觀測性收集器!透過單一工具實現了完整的 LGTM 資料收集,大幅簡化了架構複雜度。
今日重點成果:
關於實驗環境的限制:
由於我們的實驗環境資源有限(8Core 32G),LGTM Stack 的完整實驗就進行到這裡。雖然我們成功驗證了統一收集器的核心概念,但完整的追蹤系統整合需要更多資源和複雜配置。重要的是,我們已經理解了現代可觀測性系統的架構原理和實作方式,這些知識在生產環境中將非常寶貴。
明天我們將轉向 Day 28:叢集升級與備份策略 - 牧場的安全防護網!我們要學習如何安全地升級 RKE2 叢集、進行節點維護,以及建立完整的備份與災難恢復策略。這是每個牧場主都必須精通的重要技能!
💡 牧場主小提示:統一收集器就像訓練一個全能的牧場助手,能夠同時處理多種任務而不會互相干擾。Alloy 的強大之處在於它的模組化設計,讓我們可以像搭積木一樣組合不同的功能。記住,簡單的架構往往是最可靠的架構,用一個工具做好所有事情,比用十個工具各做一件事情更值得信賴!

