今天是我們正式進入實作的第一天,目標是把資料集載入Python,並且先做初步檢視。
實作流程很簡單,首先在專案資料夾(/IT_population_age)中放入CSV(將名稱改成IT_population_age)
然後使用Pandas載入:import pandas as pd
df = pd.read_csv("IT_population_age/IT_population_age.csv")
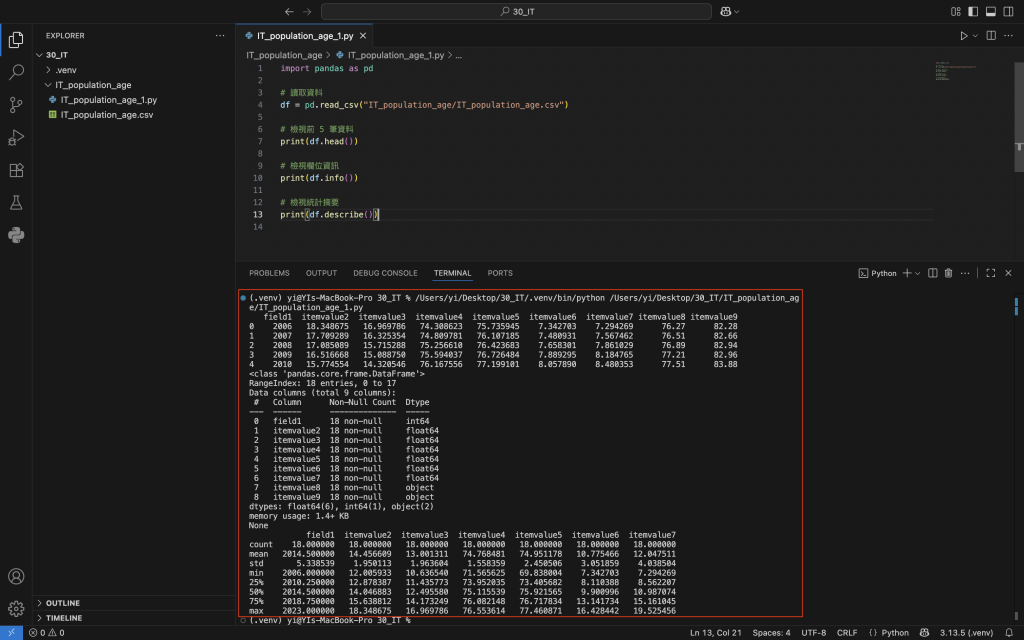
接著使用df.head()觀察前幾筆資料,確認欄位名稱是否正確;再用df.info()檢查欄位型態與缺值情況,最後可以用df.describe()觀察統計摘要。
import pandas as pd
#讀取資料
df = pd.read_csv("IT_population_age/IT_population_age.csv")
#檢視前 5 筆資料
print(df.head())
#檢視欄位資訊
print(df.info())
#檢視統計摘要
print(df.describe())
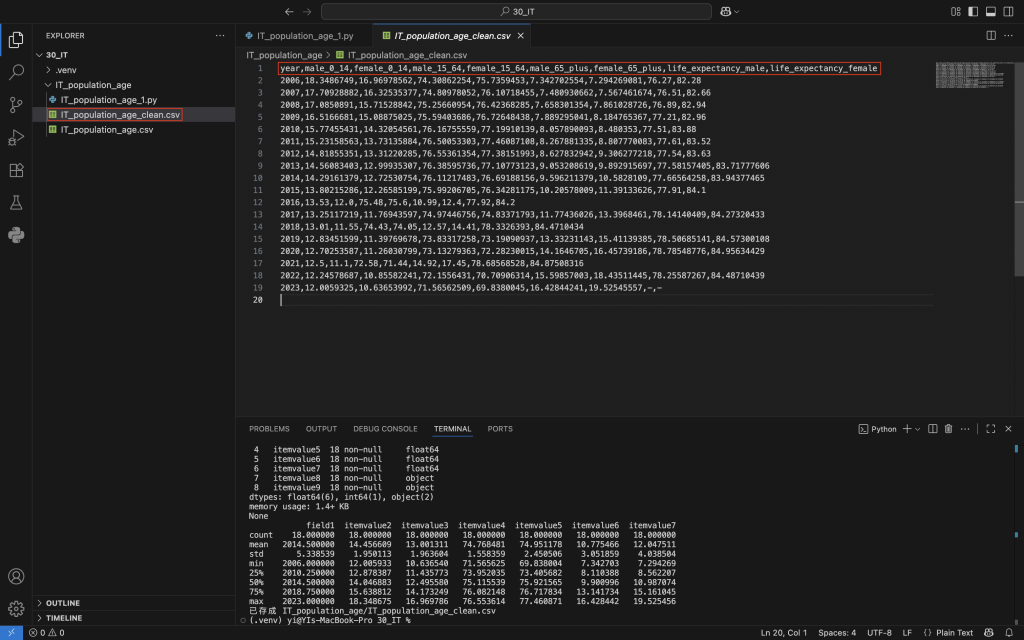
為了方便後續分析,我建議將欄位重新命名,並存成新檔,例如把itemvalue2改成male_0_14,itemvalue3改成female_0_14,依此類推,這樣閱讀起來更清楚。
df = df.rename(columns={
"field1": "year",
"itemvalue2": "male_0_14",
"itemvalue3": "female_0_14",
"itemvalue4": "male_15_64",
"itemvalue5": "female_15_64",
"itemvalue6": "male_65_plus",
"itemvalue7": "female_65_plus",
"itemvalue8": "life_expectancy_male",
"itemvalue9": "life_expectancy_female"
})
print(df.head())
df.to_csv("1_clean.csv", index=False)
print("已存成 1_clean.csv")
今天的目標不在於畫圖,而是確認資料結構是否合理,並確定每個欄位代表的意義。這些準備動作能幫助我們在後續分析過程中更加順利,明天就可以開始進行視覺化,先從最簡單的長條圖著手。


 iThome鐵人賽
iThome鐵人賽