一、資料處理
首先將原始資料讀入,並將發布時間欄位轉為 日期時間格式,方便後續分析:df["publishtime"] = pd.to_datetime(df["publishtime"])
接著,依據AQI數值將測站分為七個等級:
二、AQI等級分布
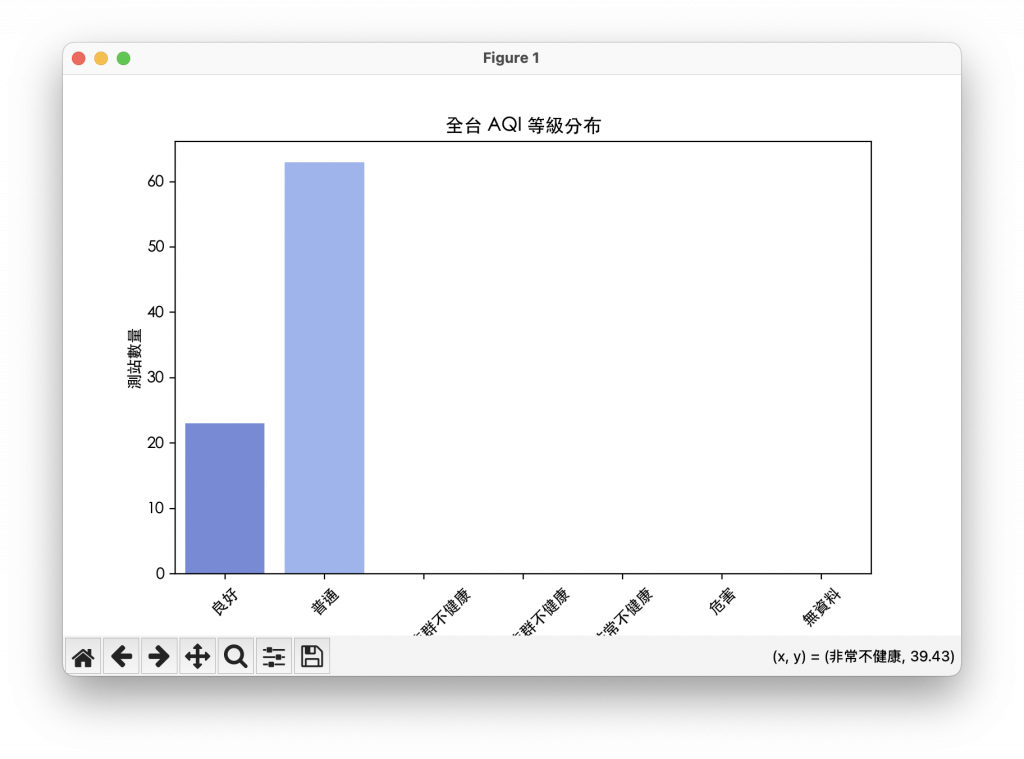
統計結果顯示各AQI等級的測站數量,並使用長條圖呈現,圖表結果清楚呈現出,全台大部分測站的空氣品質屬於 良好或普通,僅少數測站顯示對敏感族群不健康或更高等級。這對一般民眾和政策制定者皆有參考價值。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 設定中文字型
plt.rcParams["font.family"] = "Heiti TC"
plt.rcParams["axes.unicode_minus"] = False
# 讀取資料
df = pd.read_csv("IT_AQI/AQI.csv")
# 轉換時間格式
df["publishtime"] = pd.to_datetime(df["publishtime"])
# AQI 等級分類函數
def aqi_category(aqi):
if pd.isna(aqi):
return "無資料"
elif aqi <= 50:
return "良好"
elif aqi <= 100:
return "普通"
elif aqi <= 150:
return "對敏感族群不健康"
elif aqi <= 200:
return "對所有族群不健康"
elif aqi <= 300:
return "非常不健康"
else:
return "危害"
df["AQI_Level"] = df["aqi"].apply(aqi_category)
# AQI 等級分布統計
level_counts = (
df["AQI_Level"]
.value_counts()
.reindex(
[
"良好",
"普通",
"對敏感族群不健康",
"對所有族群不健康",
"非常不健康",
"危害",
"無資料",
],
fill_value=0,
)
)
plt.figure(figsize=(8, 5))
sns.barplot(x=level_counts.index, y=level_counts.values, palette="coolwarm")
plt.title("全台 AQI 等級分布")
plt.ylabel("測站數量")
plt.xlabel("AQI 等級")
plt.xticks(rotation=45)
plt.show()
三、分析心得
空氣品質整體良好:絕大多數測站AQI在0–100範圍內,表示空氣污染尚在可接受範圍。
少數測站需注意:部分測站AQI屬對敏感族群不健康或更高級別,提示特定地區需加強環境監控或改善空污源。


 iThome鐵人賽
iThome鐵人賽