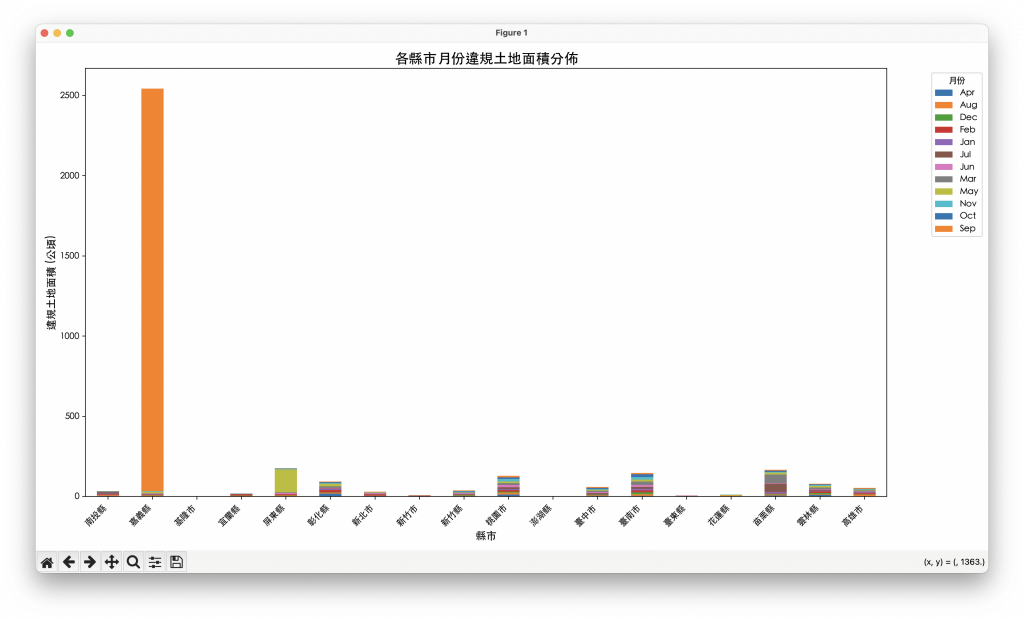
在分別分析了各縣市的違規面積排名和整體月份趨勢後,下一步是將這兩個維度整合起來,以進行更深入的觀察。透過一張堆疊長條圖(Stacked Bar Chart),我們能同時呈現每個縣市在不同月份的違規面積貢獻,這有助於我們理解:
單一縣市的月份分佈:某個縣市的違規面積高峰是否集中在特定月份?
縣市間的月份比較:不同縣市的月份趨勢是否相同?例如,A縣市在夏季違規面積最高,而B縣市在春季。
這種多維度整合圖表,能夠提供比單一圖表更豐富的資訊。例如,管理者不僅知道「臺北市違規面積最多」,還能進一步了解「臺北市的違規面積主要集中在哪些月份」,從而針對性地調整巡查計畫。
程式實作
我們將使用Pandas的groupby()函式來對數據進行分組,並繪製堆疊長條圖。首先,需要將原始的月份欄位進行「融化(melt)」操作,將橫向的月份數據轉為縱向的「月份」與「面積」欄位,方便後續的數據處理與繪圖。
import pandas as pd
import matplotlib.pyplot as plt
# 設定中文字型
plt.rcParams["font.family"] = "Heiti TC"
plt.rcParams["axes.unicode_minus"] = False
# 讀取 CSV,跳過中文標題列
df = pd.read_csv("IT_land_violation/land_violation.csv", skiprows=[1])
# 定義月份欄位
months = [
"Jan",
"Feb",
"Mar",
"Apr",
"May",
"Jun",
"Jul",
"Aug",
"Sep",
"Oct",
"Nov",
"Dec",
]
# 轉數字
df[months] = df[months].apply(pd.to_numeric, errors="coerce")
# 移除「總計」列
df = df[df["County_Area_Hectare"] != "總計"]
# 融化數據:將月份欄位轉為單一列
df_melted = df.melt(
id_vars=["County_Area_Hectare"],
value_vars=months,
var_name="Month",
value_name="Violation_Area",
)
# 繪製堆疊長條圖
fig, ax = plt.subplots(figsize=(15, 8))
df_melted.groupby(["County_Area_Hectare", "Month"])[
"Violation_Area"
].sum().unstack().plot(kind="bar", stacked=True, ax=ax)
# 調整圖表標題與標籤
plt.title("各縣市月份違規土地面積分佈", fontsize=16)
plt.xlabel("縣市", fontsize=12)
plt.ylabel("違規土地面積 (公頃)", fontsize=12)
plt.xticks(rotation=45, ha="right")
plt.legend(title="月份", bbox_to_anchor=(1.05, 1), loc="upper left")
plt.tight_layout()
plt.show()


 iThome鐵人賽
iThome鐵人賽