昨天搭建好了 Loki 日誌系統,牧場的活動軌跡都被完整記錄下來了!不過作為一個稱職的數位牧場主,光有日誌還不夠,我們還需要長期保存各種指標數據。今天要來部署 Mimir,讓它當我們牧場的數據倉庫,專門負責儲存 Prometheus 的長期指標!

在企業環境中,我們有兩種主要的 Mimir 部署策略,各有其適用場景:
優勢:
劣勢:
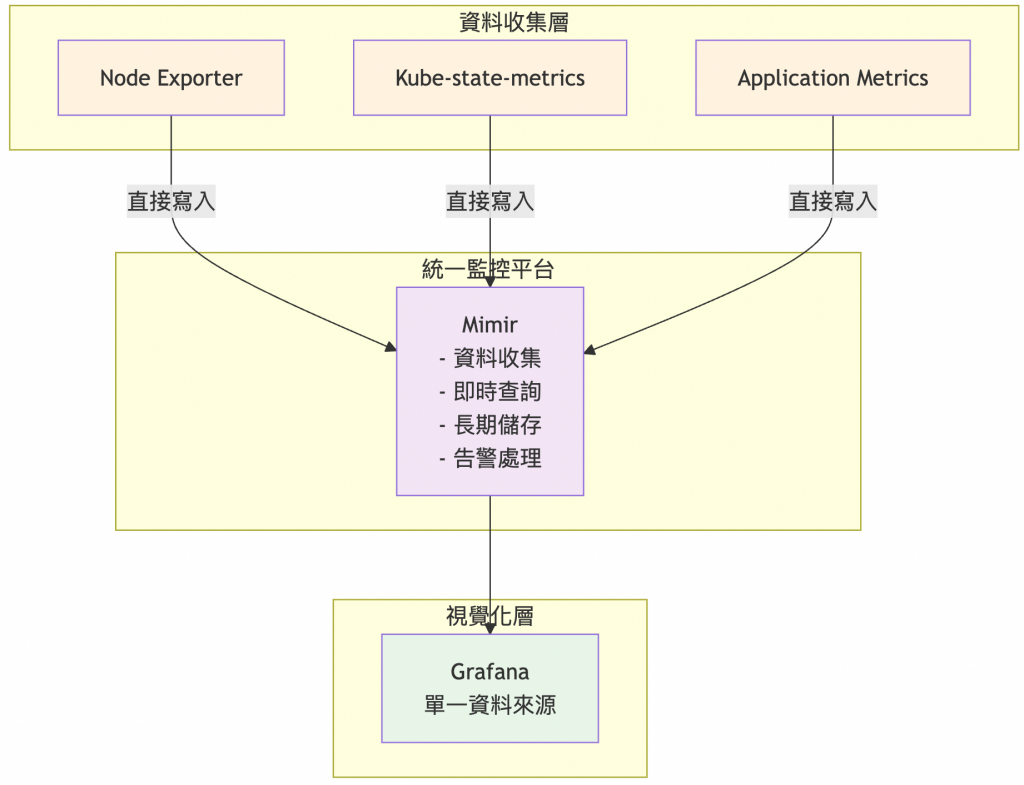
優勢:
劣勢:
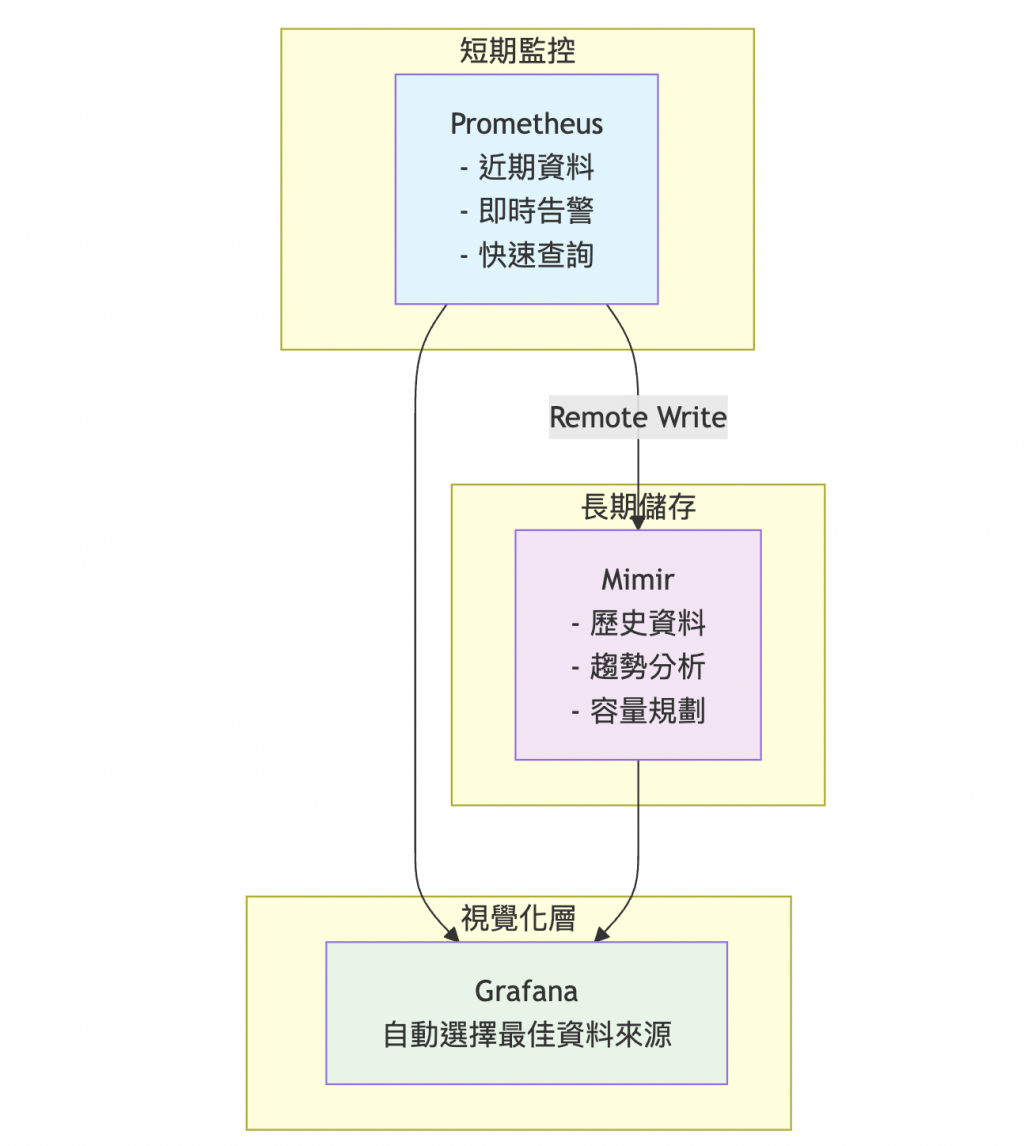
基於以下考量,我們選擇 Prometheus + Mimir 的混合架構:
我們現有的 Prometheus 設定:
# prometheus-values.yaml 中的限制
prometheus:
prometheusSpec:
retention: 7d # 只保留 7 天資料
retentionSize: 15GB # 磁碟空間限制
面臨的挑戰:
時間維度限制:
空間維度限制:
查詢維度限制:
無限擴展的時間維度:
彈性擴展的空間維度:
高效能的查詢維度:
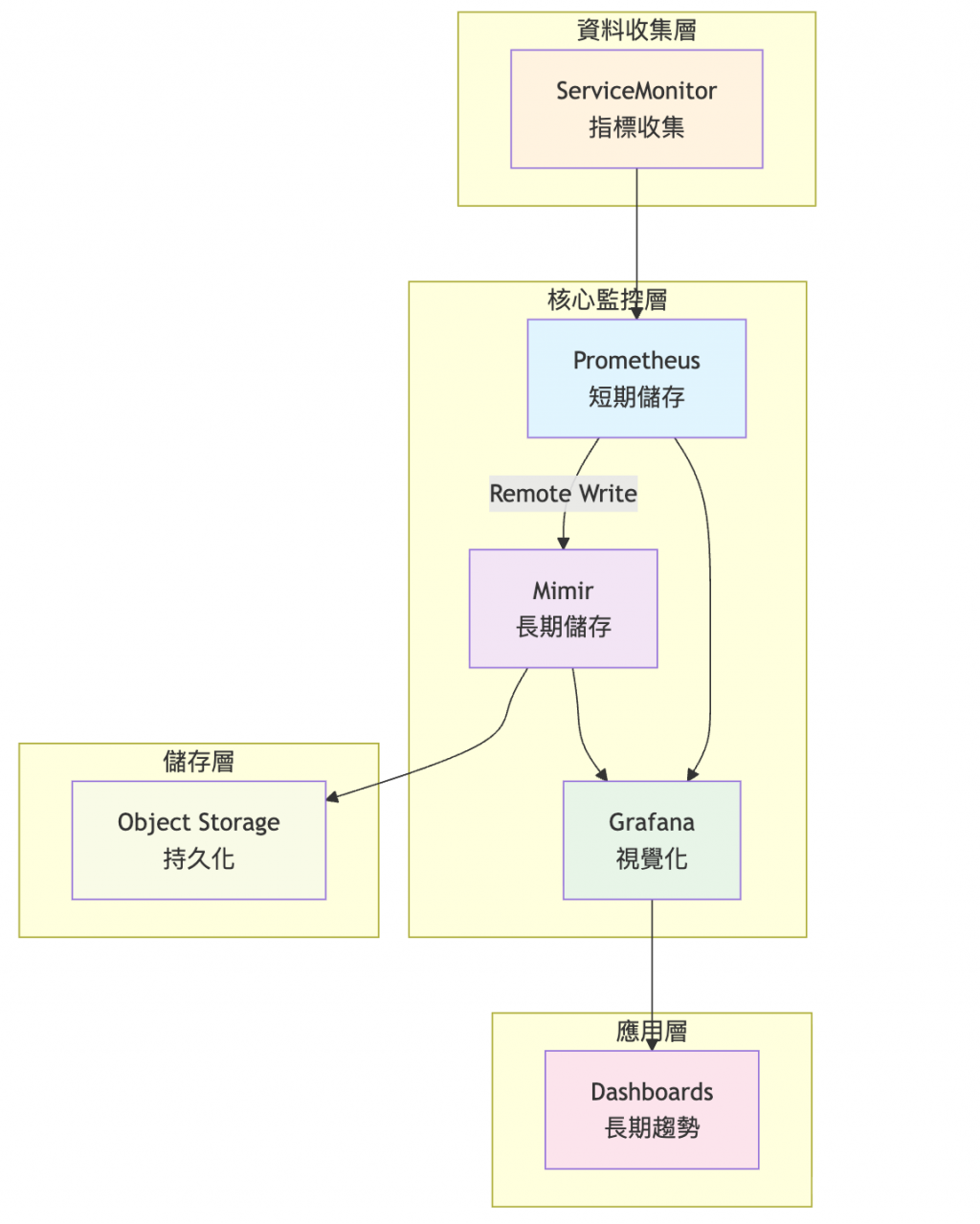
寫入路徑:
查詢路徑:
更新 lgtm-values.yaml 啟用 Mimir:
# LGTM Stack 配置 - 啟用 Loki + Mimir
grafana:
enabled: false
# Loki 日誌系統配置(保持現有設定)
loki:
enabled: true
loki:
auth_enabled: false
commonConfig:
replication_factor: 1
storage:
type: filesystem
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
gateway:
enabled: true
replicas: 1
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
nginxConfig:
resolver: "10.43.0.10" # RKE2 CoreDNS IP
backend:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
read:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
write:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m
memory: 512Mi
# Mimir 指標存儲系統
mimir:
enabled: true
# Mimir 核心配置
mimir:
structuredConfig:
# 多租戶功能(實驗環境關閉以簡化配置)
multitenancy_enabled: false
# 區塊儲存配置 - Mimir 的核心儲存引擎
blocks_storage:
backend: filesystem # 使用本地檔案系統(生產環境建議用 S3)
filesystem:
dir: /data/mimir-blocks # 時序資料區塊儲存路徑(避免與 ruler 衝突)
# 資料壓縮器配置 - 負責長期資料的壓縮和清理
compactor:
data_dir: /data/compactor # 壓縮過程中的暫存目錄
sharding_ring: # 多個 compactor 實例的協調機制
kvstore:
store: memberlist # 使用 memberlist 進行節點發現(輕量級)
# 資料攝取器配置 - 接收和處理 Remote Write 資料
ingester:
ring: # Ingester 叢集的狀態管理
kvstore:
store: memberlist
replication_factor: 1 # 實驗環境設定為1,避免需要多個副本
instance_limits: # 單一 Ingester 實例限制
max_series: 100000 # 最大時序數量(避免記憶體爆炸)
max_tenants: 10 # 最大租戶數量(多租戶環境用)
# 查詢引擎配置
querier:
max_concurrent: 4 # 最大並發查詢數(控制資源使用)
# 全域限制配置(防止系統過載)
limits:
ingestion_rate: 50000 # 每秒最大樣本攝取率
ingestion_burst_size: 200000 # 短期爆發時的最大樣本數
max_global_series_per_user: 150000 # 每用戶最大時序總數
max_global_series_per_metric: 20000 # 每指標最大時序數(控制基數)
# 告警規則配置(避免目錄衝突)
ruler_storage:
backend: filesystem
filesystem:
dir: /data/ruler # 告警規則儲存目錄(避免與 blocks 衝突)
# 告警管理配置(使用現有的 AlertManager)
alertmanager:
external_url: http://kube-prometheus-stack-alertmanager.monitoring.svc.cluster.local:9093
# === 各組件資源配置與用途說明 ===
# Ingester:資料攝取和短期儲存
# - 接收 Remote Write 資料並暫存在記憶體
# - 定期將資料寫入持久化區塊
# - 處理近期查詢請求
ingester:
replicas: 1 # 實驗環境使用單實例
resources:
requests:
cpu: 200m # 資料攝取需要較多 CPU
memory: 512Mi # 需要足夠記憶體暫存時序資料
limits:
cpu: 1000m
memory: 1Gi
persistentVolume:
enabled: true
size: 10Gi # 儲存未壓縮的原始區塊
# Distributor:負載均衡和資料分發
# - 接收 Prometheus Remote Write 請求
# - 根據時序 hash 分發到對應 Ingester
# - 處理資料驗證和限制檢查
distributor:
replicas: 1
resources:
requests:
cpu: 100m # 主要做資料轉發,CPU 需求較低
memory: 256Mi # 記憶體需求適中
limits:
cpu: 500m
memory: 512Mi
# Querier:查詢處理引擎
# - 處理 PromQL 查詢請求
# - 從 Ingester 和 Store Gateway 獲取資料
# - 執行查詢計算和資料合併
querier:
replicas: 1
resources:
requests:
cpu: 100m # 查詢計算需要 CPU
memory: 256Mi
limits:
cpu: 500m
memory: 512Mi
# Query Frontend:查詢優化和快取
# - 接收查詢請求並進行優化
# - 查詢結果快取和分片
# - 提供查詢排隊和限速功能
query_frontend:
replicas: 1
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 300m # 主要做查詢協調,資源需求較低
memory: 512Mi
# 注意:Compactor、Store Gateway、Ruler 在下方設定為 disabled
# Nginx Gateway:統一入口和負載均衡
# - 提供統一的查詢和寫入入口
# - 處理 HTTP 路由和負載均衡
# - 需要 DNS 解析器配置(RKE2 環境)
nginx:
enabled: true
replicas: 1
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
# 修正 RKE2 DNS 解析器問題
nginxConfig:
resolver: rke2-coredns-rke2-coredns.kube-system.svc.cluster.local.
# === 組件啟用/停用配置 ===
# AlertManager:使用現有的 kube-prometheus-stack AlertManager
alertmanager:
enabled: false # 關閉內建 AlertManager,使用現有的
# Compactor:資料壓縮(實驗環境可暫時關閉)
compactor:
enabled: false # 暫時關閉以簡化部署
# Store Gateway:長期資料存取(實驗環境可暫時關閉)
store_gateway:
enabled: false # 暫時關閉,只測試近期資料
# Ruler:告警規則處理(實驗環境可暫時關閉)
ruler:
enabled: false # 暫時關閉,避免配置複雜性
# Tempo 分散式追蹤系統(暫時 disable)
tempo:
enabled: false
# Grafana OnCall(不需要)
grafana-oncall:
enabled: false
# 升級 LGTM Stack 啟用 Mimir
helm upgrade lgtm-stack grafana/lgtm-distributed \
-n lgtm-stack \
-f lgtm-values.yaml
# 檢查 Mimir 組件部署狀態
kubectl get pods -n lgtm-stack | grep mimir
預期結果:
NAME READY STATUS
lgtm-stack-mimir-distributor-xxx 1/1 Running
lgtm-stack-mimir-ingester-0 1/1 Running
lgtm-stack-mimir-querier-xxx 1/1 Running
lgtm-stack-mimir-query-frontend-xxx 1/1 Running
lgtm-stack-mimir-compactor-0 1/1 Running
lgtm-stack-mimir-store-gateway-0 1/1 Running
lgtm-stack-mimir-nginx-xxx 1/1 Running
檢查部署狀態:
# 檢查所有 Mimir 組件狀態
kubectl get pods -n lgtm-stack | grep mimir
# 檢查特定組件日誌
kubectl logs -n lgtm-stack lgtm-stack-mimir-nginx-xxx --tail=10
kubectl logs -n lgtm-stack lgtm-stack-mimir-ingester-0 --tail=10
# 等待核心組件就緒
kubectl wait --for=condition=ready pod -l app.kubernetes.io/component=distributor -n lgtm-stack --timeout=300s
為什麼關閉某些組件:
AlertManager:
Compactor(暫時關閉):
Store Gateway(暫時關閉):
Ruler(暫時關閉):
核心功能仍完整:
更新 prometheus-values.yaml 添加 Remote Write 設定:
# 在現有 prometheus 區段中添加 Remote Write
prometheus:
prometheusSpec:
# 保持現有設定...
retention: 7d
retentionSize: 15GB
scrapeInterval: 30s
evaluationInterval: 30s
# 新增 Remote Write 配置
remoteWrite:
- url: http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/api/v1/push
queueConfig:
capacity: 10000
maxSamplesPerSend: 5000
batchSendDeadline: 5s
minShards: 1
maxShards: 10
writeRelabelConfigs:
# 添加 cluster 標籤(Kubernetes-mixin dashboard 需要)
- targetLabel: cluster
replacement: rancher-cluster
- sourceLabels: [__name__]
regex: 'up|prometheus_.*|node_.*|kube_.*|container_.*|namespace_.*|.*:.*:.*'
action: keep
# 安全設定(修正權限問題)
securityContext:
runAsNonRoot: true
runAsUser: 65534
fsGroup: 65534
# 資源配置(可能需要增加)
resources:
requests:
cpu: 200m
memory: 1Gi
limits:
cpu: 1000m
memory: 2Gi
# 儲存設定
storageSpec:
volumeClaimTemplate:
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 20Gi
# 其他設定保持不變...
grafana:
adminPassword: "admin123"
persistence:
enabled: true
size: 5Gi
additionalDataSources:
- name: Loki
type: loki
url: http://lgtm-stack-loki-gateway.lgtm-stack.svc.cluster.local
access: proxy
isDefault: false
editable: true
jsonData:
maxLines: 1000
# 新增 Mimir 資料來源
- name: Mimir
type: prometheus
url: http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/prometheus
access: proxy
isDefault: false
editable: true
jsonData:
httpMethod: POST
timeInterval: "30s"
# 升級 Prometheus Stack 配置
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack \
-n monitoring \
-f prometheus-values.yaml
# 檢查 Prometheus 配置載入
kubectl get prometheus -n monitoring -o yaml | grep -A 10 remoteWrite
# 檢查 Prometheus Pod 重啟狀態
kubectl rollout status statefulset/prometheus-kube-prometheus-stack-prometheus -n monitoring
# 如果出現 CrashLoopBackOff,檢查日誌
kubectl logs -n monitoring prometheus-kube-prometheus-stack-prometheus-0 -c prometheus --tail=20
在實際部署過程中,我們遇到了幾個典型問題,這些經驗對其他牧場主很有參考價值:
錯誤現象:
kubectl logs -n lgtm-stack lgtm-stack-mimir-nginx-xxx
# host not found in resolver "kube-dns.kube-system.svc.cluster.local."
根本原因:
rke2-coredns-rke2-coredns
解決步驟:
# 1. 檢查你的叢集 DNS 設定
kubectl get svc -n kube-system | grep dns
# 輸出:rke2-coredns-rke2-coredns ClusterIP 10.43.0.10 <none> 53/UDP,53/TCP
# 2. 更新 lgtm-values.yaml 中的 nginx 配置
nginx:
nginxConfig:
resolver: rke2-coredns-rke2-coredns.kube-system.svc.cluster.local.
錯誤現象:
kubectl logs -n lgtm-stack lgtm-stack-mimir-ingester-0
# at least 2 live replicas required, could only find 1
根本原因:
replication_factor: 3,需要至少 2 個 ingester 實例解決步驟:
# 在 lgtm-values.yaml 中添加 replication_factor 設定
mimir:
mimir:
structuredConfig:
ingester:
ring:
kvstore:
store: memberlist
replication_factor: 1 # 實驗環境設為1
錯誤現象:
# Prometheus 日誌顯示 Remote Write 500 錯誤
# Mimir nginx 回傳 Internal Server Error
根本原因:
解決步驟:
錯誤現象:
根本原因:
/prometheus 路徑前綴解決步驟:
# 修正 Grafana 資料來源配置
additionalDataSources:
- name: Mimir
type: prometheus
# 錯誤:url: http://lgtm-stack-mimir-query-frontend.lgtm-stack.svc.cluster.local
url: http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/prometheus # 正確
錯誤現象:
根本原因:
解決步驟:
# 1. 在 Remote Write 中添加 cluster 標籤
remoteWrite:
- url: http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/api/v1/push
writeRelabelConfigs:
# 添加 cluster 標籤
- targetLabel: cluster
replacement: rancher-cluster
# 擴展過濾規則包含 recording rules
- sourceLabels: [__name__]
regex: 'up|prometheus_.*|node_.*|kube_.*|container_.*|namespace_.*|.*:.*:.*'
action: keep
為什麼需要這些修正:
namespace_.*:包含 namespace_workload_pod:kube_pod_owner:relabel 等關鍵 recording rule.*:.*:.*:涵蓋所有標準格式的 recording rules(格式:level:metric:operation)cluster 標籤:讓 Kubernetes-mixin dashboard 能正確聚合和顯示多叢集資料錯誤現象:
kubectl logs -n monitoring prometheus-kube-prometheus-stack-prometheus-0
# open /prometheus/queries.active: permission denied
根本原因:
解決步驟:
# 在 prometheus-values.yaml 中確保正確的安全設定
prometheus:
prometheusSpec:
securityContext:
runAsNonRoot: true
runAsUser: 65534
fsGroup: 65534
錯誤現象:
解決步驟:
# 1. 檢查 Mimir distributor 狀態
kubectl get pods -n lgtm-stack | grep distributor
# 2. 測試網路連通性(修正版)
kubectl exec -n monitoring prometheus-kube-prometheus-stack-prometheus-0 -- \
wget -O- --timeout=5 http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/ready
# 注意:應該測試 nginx gateway,而非直接測試 distributor
1. 逐層排查法:
# 第1層:檢查 Pod 狀態
kubectl get pods -n lgtm-stack | grep mimir
# 第2層:檢查服務發現
kubectl get svc -n lgtm-stack | grep mimir
# 第3層:檢查日誌
kubectl logs -n lgtm-stack deployment/lgtm-stack-mimir-distributor --tail=20
# 第4層:測試網路連通性
kubectl exec -n monitoring prometheus-xxx -- wget -O- --timeout=5 \
http://lgtm-stack-mimir-nginx.lgtm-stack.svc.cluster.local/ready
2. 資料流驗證法:
# 驗證 Prometheus → Mimir 資料流
# 1. Prometheus Remote Write 統計
curl http://localhost:9090/api/v1/query?query=prometheus_remote_storage_samples_total
# 2. Mimir 接收統計
curl http://localhost:8081/prometheus/api/v1/query?query=up | jq '.data.result | length'
# 存取 Prometheus UI 檢查 Remote Write 狀態
kubectl port-forward -n monitoring svc/kube-prometheus-stack-prometheus 9090:9090 &
# 瀏覽器開啟 http://localhost:9090
# 前往 Status → Configuration 檢查 remote_write 設定
# 檢查 Mimir Distributor 日誌
kubectl logs -n lgtm-stack deployment/lgtm-stack-mimir-distributor --tail=20
# 檢查 Mimir Ingester 日誌
kubectl logs -n lgtm-stack statefulset/lgtm-stack-mimir-ingester --tail=20
# 測試 Mimir Query API
kubectl port-forward -n lgtm-stack svc/lgtm-stack-mimir-query-frontend 8080:8080 &
curl "http://localhost:8080/prometheus/api/v1/query?query=up"
在 Grafana Explore 中:
# 檢查基本指標
up
# 檢查節點指標
node_load1
# 檢查 Kubernetes 指標
kube_pod_info
# 檢查基本指標(一定有資料)
up
# 檢查帶 cluster 標籤的指標
up{cluster="rancher-cluster"}
# 檢查 Mimir 儲存使用情況
kubectl exec -n lgtm-stack statefulset/lgtm-stack-mimir-ingester -- \
df -h /data
kubectl exec -n lgtm-stack statefulset/lgtm-stack-mimir-compactor -- \
df -h /data
kubectl exec -n lgtm-stack statefulset/lgtm-stack-mimir-store-gateway -- \
df -h /data
# 檢查各組件健康狀態
kubectl port-forward -n lgtm-stack deployment/lgtm-stack-mimir-distributor 8080:8080 &
curl http://localhost:8080/ready
kubectl port-forward -n lgtm-stack statefulset/lgtm-stack-mimir-ingester 8080:8080 &
curl http://localhost:8080/ready
kubectl port-forward -n lgtm-stack deployment/lgtm-stack-mimir-querier 8080:8080 &
curl http://localhost:8080/ready
查詢效能優化:
儲存效能優化:
今天我們成功部署了 Mimir 長期指標儲存系統,為牧場建立了一個強大的數據倉庫!透過 Remote Write 機制,Prometheus 的所有指標現在都會同步儲存到 Mimir,讓我們能夠進行長期的趨勢分析和歷史數據查詢。
重點回顧:
架構完整性:
明天我們要部署 LGTM Stack 的最後一塊拼圖 - Tempo 分散式追蹤系統,讓牧場的可觀測性達到完整的三支柱整合!
💡 牧場主小提示:Mimir 部署看似複雜,但掌握核心原理就不難!RKE2 環境記得修正 DNS 解析器;單實例部署務必設定
replication_factor: 1;Remote Write 過濾規則要包含 recording rules,否則 Kubernetes 儀表板會一片空白;cluster 標籤是多叢集監控的靈魂,千萬別忘了加!遇到問題先看日誌,再測網路,最後驗證資料流,逐層排查事半功倍!

