
HI!大家好,我是 Shammi 😊
在過去十天,我成功建構了 RAG 架構的核心骨幹,讓機器人可以從 PDF 知識庫中,找到並回答使用者的問題。但目前的機器人還像是一個圖書館的管理員,只會精準地丟出書裡的內容。
從今天開始,我要試著讓它學會「說人話」。先設計基本的對話流程,並將回答進行格式化,讓它看起來更像是一個真正的 AI 機器人。
將 Day 10 的 RAG 流程,包裝進一個簡單的對話迴圈中。
首先,先將 Day 10 中定義的 get_rag_answer 函式沿用過來。
這個函式將負責從接收問題、檢索、到生成答案的整個流程。
#程式碼無需再新增,僅示意步驟
def get_rag_answer(query):
#step1. 將問題向量化 (檢索)
query_vector = get_embedding(query)
#step2. 在 FAISS 索引中搜尋
distances, indices = index.search(query_vector, k=3)
#step3. 取得最相關的原始內容
retrieved_chunks = [stored_chunks[i] for i in indices[0]]
#step4. 傳給 LLM 產生最終回覆 (生成)
final_answer = generate_response(query, retrieved_chunks)
return final_answer
接著,再撰寫一個 while 迴圈,讓機器人可以持續接收使用者的輸入,並將回覆進行簡單的格式化。
def chat_loop():
print("嗨,我是 SDGs 知識機器人,我叫阿米!請問有什麼關於 SDGs 的問題嗎?")
print("輸入 'exit' 或 'quit' 可以隨時結束對話。")
while True:
# 接收使用者輸入
user_query = input("你:")
# 檢查是否為結束指令
if user_query.lower() in ['exit', 'quit']:
print("阿米:期待下次為你服務!")
break
# 呼叫我們整合好的 RAG 函式
answer = get_rag_answer(user_query)
# 格式化並印出回覆
print("\n" + "="*50)
print("阿米:")
print(answer)
print("="*50 + "\n")
# 啟動對話迴圈
chat_loop()
在這個迴圈中,我們加上了簡單的結束指令,並用分隔線來讓每一輪的對話更清晰。
為了讓回覆內容更有條理,我們可以在 Day 10 的 generate_response 函式中,修改 Prompt,直接要求 LLM 輸出帶有格式的內容。
def generate_response(query, retrieved_chunks):
prompt = f"""
你是一位專精於永續發展目標 (SDGs) 的專家。
請根據以下提供的參考資料,簡潔且精準地回答使用者的問題。
請使用 **Markdown 語法**來格式化你的回答,例如粗體、標題或條列式清單,讓回答更有條理。
如果參考資料中沒有相關資訊,請禮貌地告知使用者。
使用者問題:{query}
參考資料:
{context}
"""
(後段程式碼不變)請沿用 Day 10 generate_response 函式中,沒有被修改的程式碼,只更新 prompt 的內容即可。
這樣一來,LLM 在生成回覆時,就會自動幫我們整理出一個美觀又易讀的答案。
參考結果: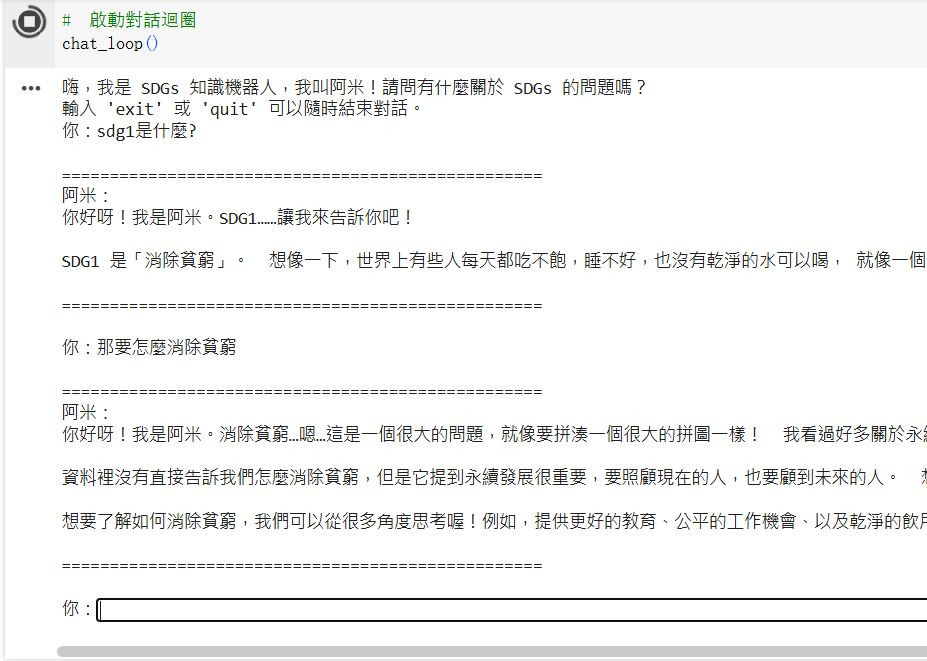
今天的篇幅讓機器人加上了基本的對話邏輯,從一個單向的「問答機」升級為能持續互動的「聊天機器人」。
接下來,將進入專案下一個階段:功能擴充與優化。明天的文章,我將繼續探討如何加入更進階的功能,例如處理更複雜的對話,或是在回覆中加入原始資料來源的連結,讓機器人變得更加強大。🤖🤖🤖
