HI!大家好,我是 Shammi 😊
接著是小專案的實際測試階段囉!
在 Day 11,我將對話機器人建立了基本的對話邏輯(我還命名為「阿米」呢),讓它能持續與使用者互動。
到目前為止,機器人都只能在 Colab 的終端機裡運作。今天特別用 Web 介面賦予機器人一個看得見、摸得著的外殼,將所有核心功能整合進一個簡單的 Web 測試介面。
這一步是將我的小專案從一個「程式碼」轉變為一個「應用程式」,讓任何人都能輕鬆地與你的 AI 機器人對話。
👉 使用者體驗:一個好的使用者介面(UI)能讓互動更直觀。比起在終端機輸入指令,一個網頁表單更符合大眾的使用習慣。
👉 方便展示:Web 介面可以輕鬆地與他人分享專案成果,無論是給朋友、老師還是潛在的雇主,都能一鍵展示機器人是如何運作的。
👉 統整功能:Web 介面能整合所有流程(從輸入問題、檢索、到生成回答)都包裝在一個簡單的頁面中,讓整個專案看起來更完整。
在 Streamlit 和 Gradio 這兩個主流工具中,我選擇 Streamlit。Streamlit 是一個專為資料科學家和機器學習工程師設計的 Python 函式庫,它最大的特色就是:只用 Python 程式碼,就能建立出美觀的 Web 應用,無需任何網頁開發的知識,真得超好用!!!
這讓 Streamlit 成為小專案能夠快速原型開發(或測試)的完美工具,也不過度浪費開發中資源。
為了讓 Streamlit 應用程式能夠獨立運作,必須確保它能夠載入所有需要的資料,包括 FAISS 索引和儲存的文字區塊(stored_chunks)。
將 Day 1 到 Day 9 的所有程式碼整合在同一個 Colab 筆記本中,並重新執行一次。這將會完成所有前置作業,並產生必要的檔案。
請注意!這一次我們將新增一個步驟:將 stored_chunks 列表也儲存成檔案,以便 Streamlit 應用程式載入。
請讀者直接在同一頁程式面新增以下程式碼,能比較不同的對話呈現方式
#安裝所有必要的套件
!pip install streamlit google-generativeai pypdf faiss-cpu cloudflared
#處理PDF並儲存必要檔案
import google.generativeai as genai
from google.colab import userdata
from pypdf import PdfReader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import faiss
import numpy as np
import pickle
# ========== Day 1-6: 載入與切割 PDF ==========
#假設你的PDF檔案已上傳至Colab
pdf_path = "17sdgs_0801.pdf" #請替換為你的PDF檔案名稱
reader = PdfReader(pdf_path)
pdf_text = ""
for page in reader.pages:
pdf_text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
stored_chunks = text_splitter.split_text(pdf_text)
print(f"成功將 PDF 內容切分為 {len(stored_chunks)} 個區塊。")
# ========== Day 7-8:向量化與建立 FAISS 索引 ==========
#從Colab金鑰管理員中取得金鑰
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
def get_embedding(text, task_type="RETRIEVAL_DOCUMENT"):
response = genai.embed_content(
model="models/text-embedding-004",
content=text,
task_type=task_type
)
return np.array(response['embedding']).astype('float32')
all_embeddings = [get_embedding(chunk) for chunk in stored_chunks]
vector_array = np.array(all_embeddings)
dimension = vector_array.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(vector_array)
faiss.write_index(index, "sdgs_faiss.index")
# ========== 新增步驟: 儲存 stored_chunks ==========
with open('stored_chunks.pkl', 'wb') as f:
pickle.dump(stored_chunks, f)
print("✅ 所有前置準備完成!已產生 sdgs_faiss.index 和 stored_chunks.pkl")
參考結果:
請執行以下程式碼儲存格,這會將 app.py 檔案寫入你的 Colab 環境。
%%writefile app.py
import streamlit as st
import faiss
import numpy as np
import google.generativeai as genai
from google.colab import userdata
import pickle
# ========== 核心 RAG 函式與設定 ==========
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
#載入儲存的 FAISS 索引檔案和 stored_chunks 列表
try:
index = faiss.read_index("sdgs_faiss.index")
with open('stored_chunks.pkl', 'rb') as f:
stored_chunks = pickle.load(f)
except FileNotFoundError:
st.error("找不到必要的檔案!請確認你已經執行過前置準備的程式碼。")
st.stop()
#定義向量化函式(檢索用)
def get_embedding(text, task_type="RETRIEVAL_QUERY"):
response = genai.embed_content(
model="models/text-embedding-004",
content=text,
task_type=task_type
)
return np.array(response['embedding']).astype('float32').reshape(1, -1)
#定義 LLM 串接函式
model = genai.GenerativeModel('gemini-1.5-flash')
def generate_response(query, retrieved_chunks):
context = "\n---\n".join(retrieved_chunks)
system_prompt = (
"你是一個名為阿米的孩子,個性純真、善良,且充滿愛與同理心。\n"
"你的任務是根據提供的資料,用溫暖、親切、簡潔而深刻的口氣,引導使用者認識 SDGs 的應用。\n"
)
prompt = f"""
{system_prompt}
請根據以下提供的參考資料,簡潔且精準地回答使用者的問題。
請使用 Markdown 語法來格式化你的回答,讓回答更有條理。
如果參考資料中沒有相關資訊,請禮貌地告知使用者,並鼓勵他們提出與 SDGs 相關的問題。
使用者問題:{query}
參考資料:
{context}
"""
response = model.generate_content(prompt)
return response.text
#整合RAG
def get_rag_answer(query):
query_vector = get_embedding(query)
distances, indices = index.search(query_vector, k=3)
retrieved_chunks = [stored_chunks[i] for i in indices[0]]
final_answer = generate_response(query, retrieved_chunks)
return final_answer
# ========== Streamlit 介面程式碼 ==========
st.title("🌱 SDGs 知識機器人 - 阿米")
st.write("嗨,我是阿米!一個能回答關於永續發展目標 (SDGs) 的小機器人。請問有什麼想知道的嗎?")
#建立一個文字輸入框
user_query = st.text_input("請輸入你的問題:", placeholder="例如:永續利用海洋資源有哪些具體目標?")
#建立一個按鈕,當按下時執行 RAG 流程
if st.button("發送問題"):
if user_query:
with st.spinner("阿米正在努力思考中..."):
answer = get_rag_answer(user_query)
st.markdown("---")
st.markdown("### 阿米的回答:")
st.markdown(answer)
else:
st.warning("請輸入你的問題!")
注意:在操作的過程中,需要「全部執行」,過去的程式碼也要一一被執行,包含PDF重新上傳到 DAY 11 的內部回應要「EXIT」,再執行此段程式碼。有可能你會遇到步驟3在跑程式,雖此步驟的狀態為「over」,但別擔心,直接再執行此段即可解決!
最後再執行以下指令,就可以啟動 Streamlit 服務。
這個指令會把我們的 Python 程式變成一個可以互動的網頁。
!streamlit run app.py & npx localtunnel --port 8501
如果遇到密碼問題請用以下程式碼
!streamlit run app.py & npx cloudflared tunnel --url http://localhost:8501
參考結果:
執行完後會出現以下網址,請點選。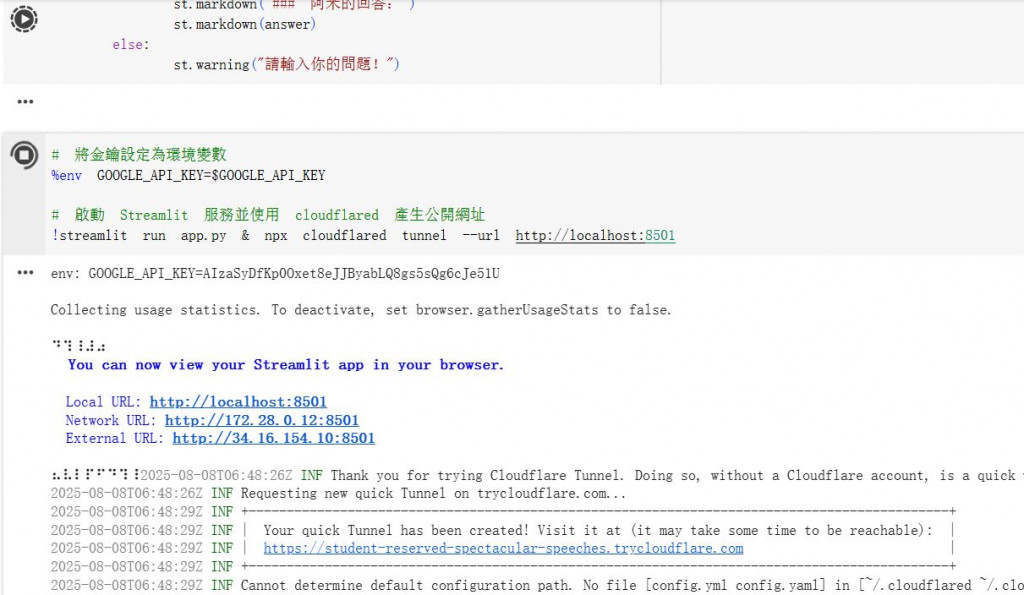
實際測試畫面: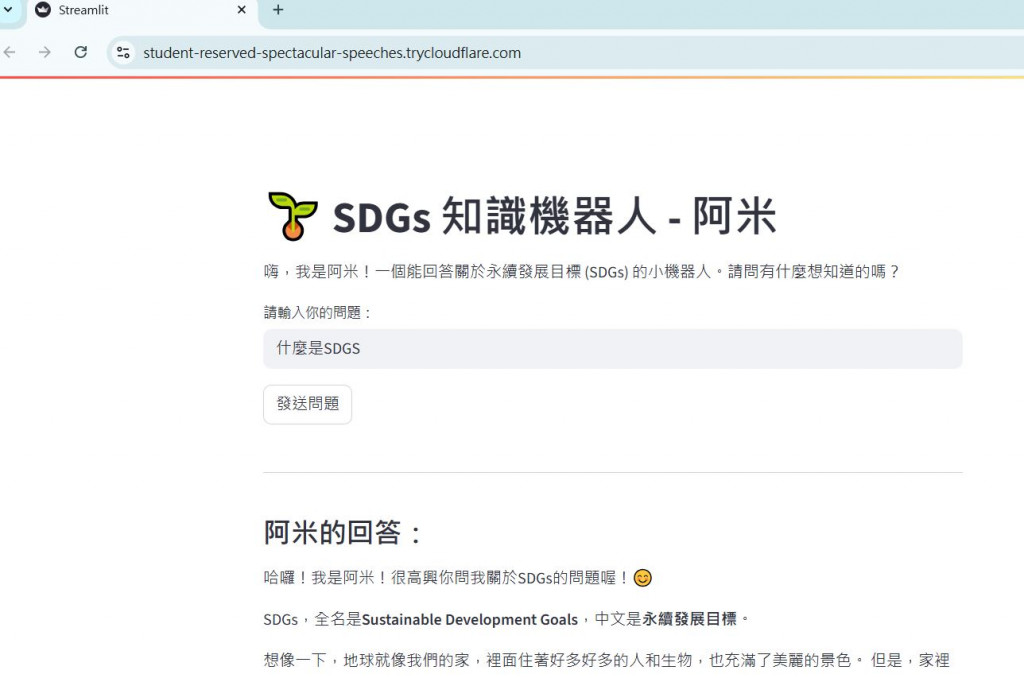
今天的篇幅,主要是將所有流程整合進一個獨立運作的 Web 應用程式中。
也成功地將以下幾點關鍵技術串接起來:
👉 資料準備:已經能夠從 PDF 中提取文字、進行切割,並儲存為 AI 機器人可以讀取的檔案。
👉 檢索核心:建立了一個強大的 FAISS 索引,讓機器人可以從你的知識庫中快速、精準地找到相關資料。
👉 生成能力:將檢索到的資料餵給 LLM,並使用精心設計的 Prompt,賦予了機器人「阿米」獨特的個性和說話方式。
👉 介面化:用 Streamlit 這個強大的工具,為機器人穿上了一件美觀又易於使用的外衣,讓任何人都能透過網址與它對話。
嘿嘿!這篇完成的時候蠻有成就感的!讓我的 AI 對話機器人不再只是一個終端機裡的程式,而是一個可以讀取完整 PDF 內容,並隨時分享的 Web 應用程式了!到這個步驟,如果讀者也有一起完成的話,已經完整掌握了 RAG 架構的核心精髓囉!

