
雖然這次的 side project 是致敬 WooTalk,但該有的規格還是要畫出來!沒有一些基本資料來對照的話,一邊開發一邊想流程對我來說還蠻困難的。
我使用 Miro 進行繪製:連結
網站的功能不多,繪製的概念也類似先前提到的 pseudo code,將主要步驟和判斷點畫出來後,整個流程的輪廓就會清晰不少。
不過目前就是畫個大概~在比較大型的專案中通常還會配上系統分析,對這些流程做更細部的拆解,制定各步驟的具體資料規格等。
我不太喜歡把流程圖畫得太長,如果是可以獨立運作的,我會歸類成一組功能流程。因為圖表延伸得太長就會很難閱讀,且焦點容易發散。而且每個步驟要寫多少程式碼也是說不準的 XD
如果能將流程盡量拆分好,無論是自己寫或是交由 AI Agent 執行,準確率也會更好:
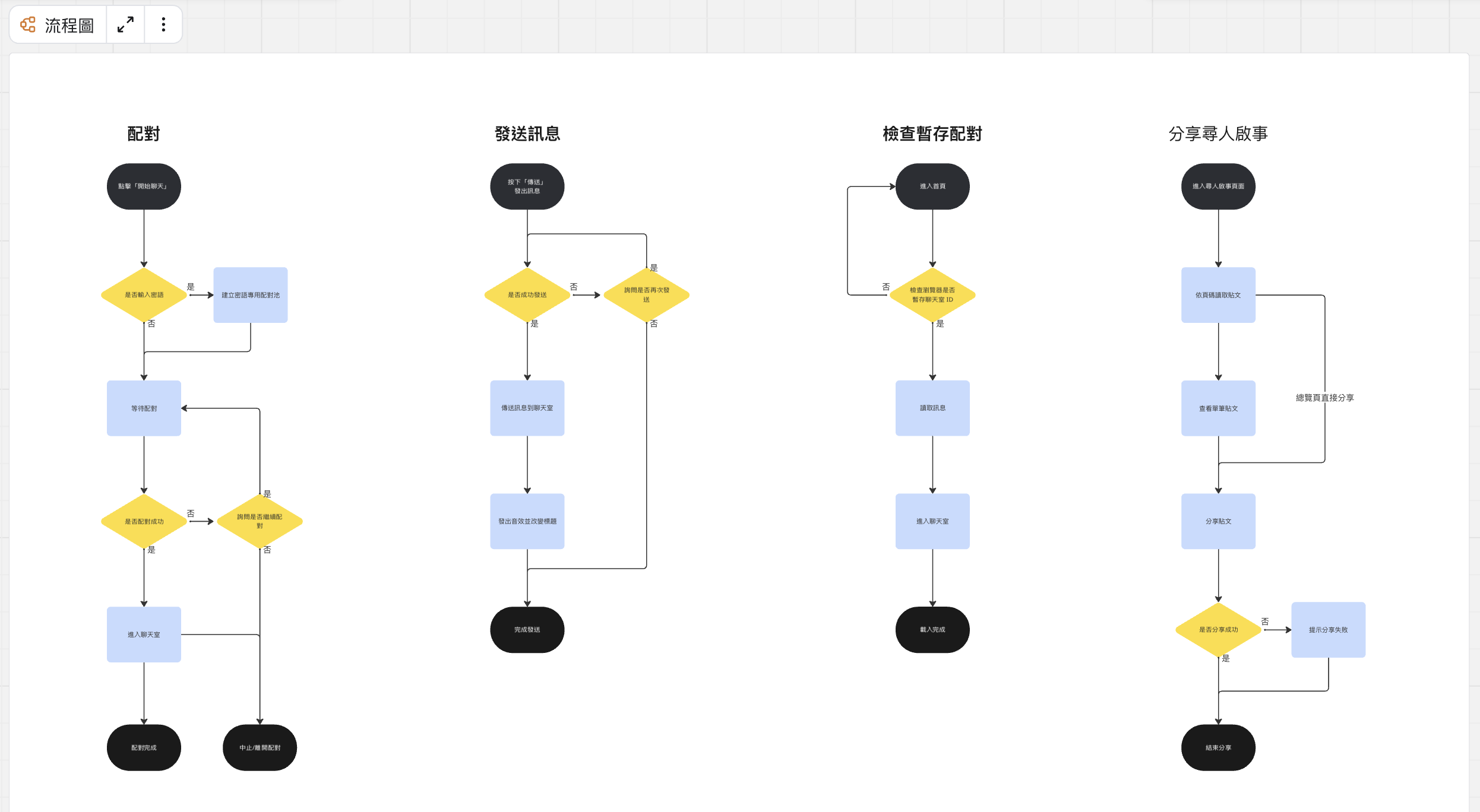
先將核心功能的流程畫出來,再看看其他功能是需要畫一組新的流程圖,或是在現有的圖上加工。使用者故事也可以列在旁邊做對照,方便盤點有什麼功能已經畫好:
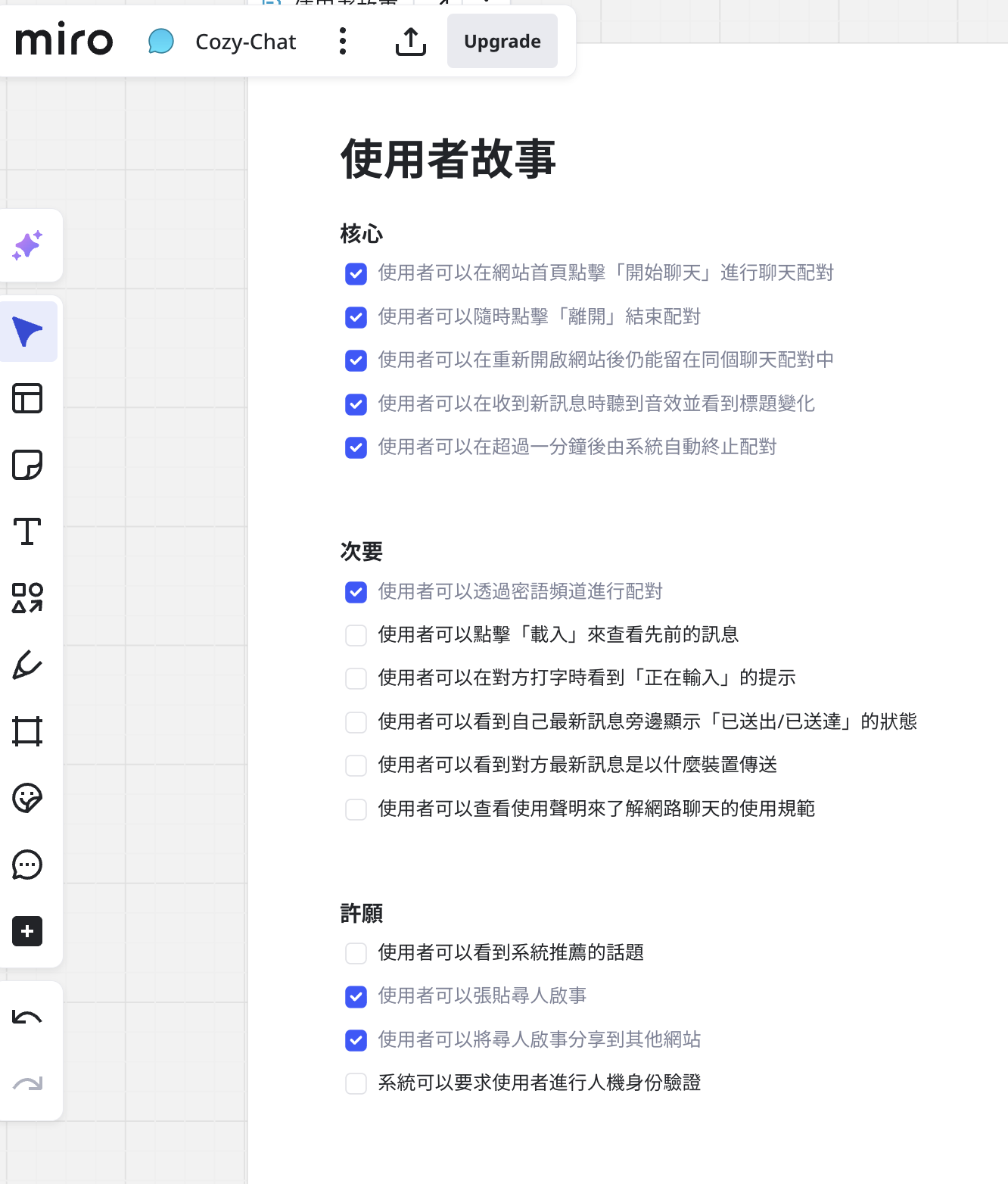
目前已經繪製:
我打算用比較彈性(容易偷懶)的 MongoDB 來進行,根據上面的流程來看,大概有 4 個 collection:
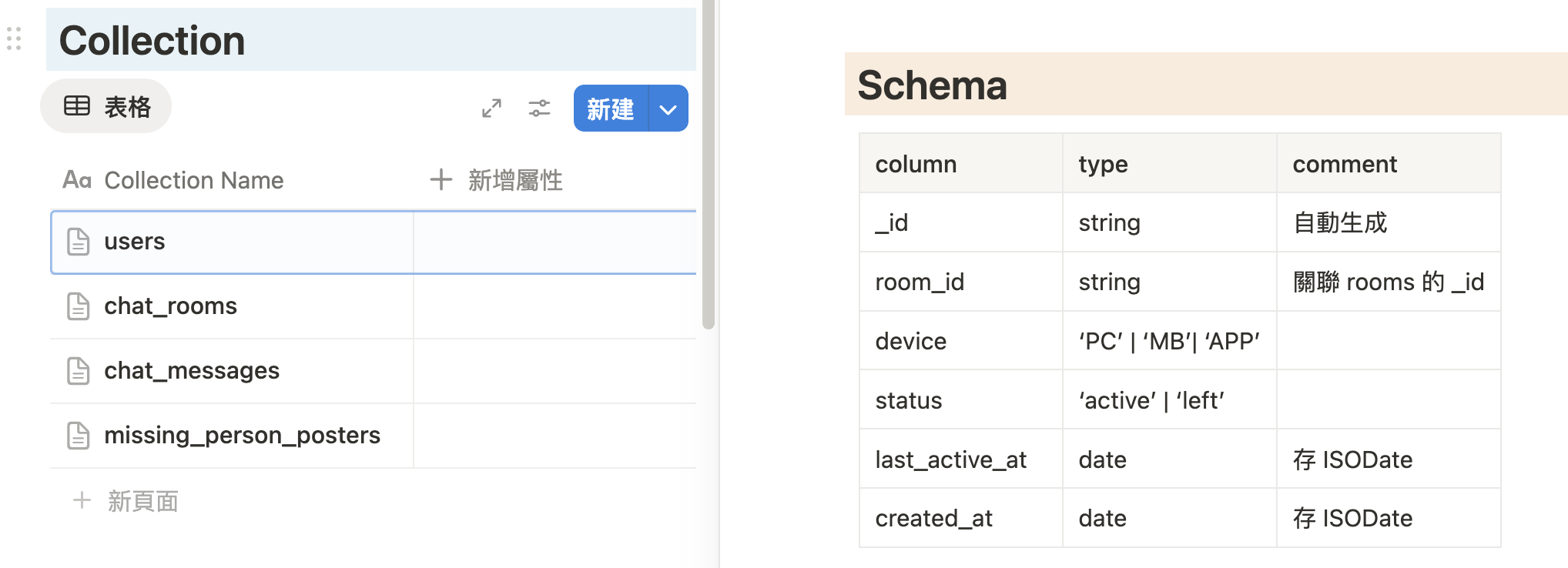
儲存連線中的使用者資料:
| column | type | comment |
|---|---|---|
| _id | string | 自動生成 |
| room_id | string | 關聯 rooms 的 _id |
| device | ‘PC’ | ‘MB’ |
| status | ‘active’ | ‘left’ |
| last_active_at | date | 存 ISODate |
| created_at | date | 存 ISODate |
儲存配對成功的房間資料:
| column | type | comment |
|---|---|---|
| _id | string | 自動生成 |
| users | string[] | 關聯 users 的 _id |
| created_at | date | 存 ISODate |
儲存房間內的訊息:
| column | type | comment |
|---|---|---|
| _id | string | 自動生成 |
| content | string | |
| room_id | string | 關聯 rooms 的 _id |
| user_id | string | 關聯 users 的 _id |
| created_at | date | 存 ISODate |
儲存尋人啟事的內容:
| column | type | comment |
|---|---|---|
| _id | string | 自動生成 |
| title | string | |
| content | string | |
| views | number | 瀏覽數 |
| post_serial | number | 依照貼文新增當下的數量編號 |
| created_at | date | 存 ISODate |
我做了一點反正規化讓部分的 collection 互相關聯,因為大部分的欄位在寫入之後就不會變動,這樣查詢資料的邏輯才不會太長。
但在正式專案裡需要考量 RDBMS 和 NoSQL 的差異,特別是循環參照(circular reference)、資料一致性的問題,資料建立的順序和驗證也必須做得更嚴謹!
聊天訊息是會持續增長的,加上之後可能會有分段讀取的需求,所以也不太適合跟房間的資料嵌在同一個 collection。
:::info
資料模擬出來後,通常不會一次就完全命中,在對照流程圖、線稿圖或到開發階段都還有可能要補欄位,所以現有的圖表是很重要的概念依據,絕對不會白白畫一堆用不到的圖。
:::
一般的 RESTful API 就註記 HTTP 方法、URL 等屬性,WebSocket 的部分另外拉出來整理成事件表:

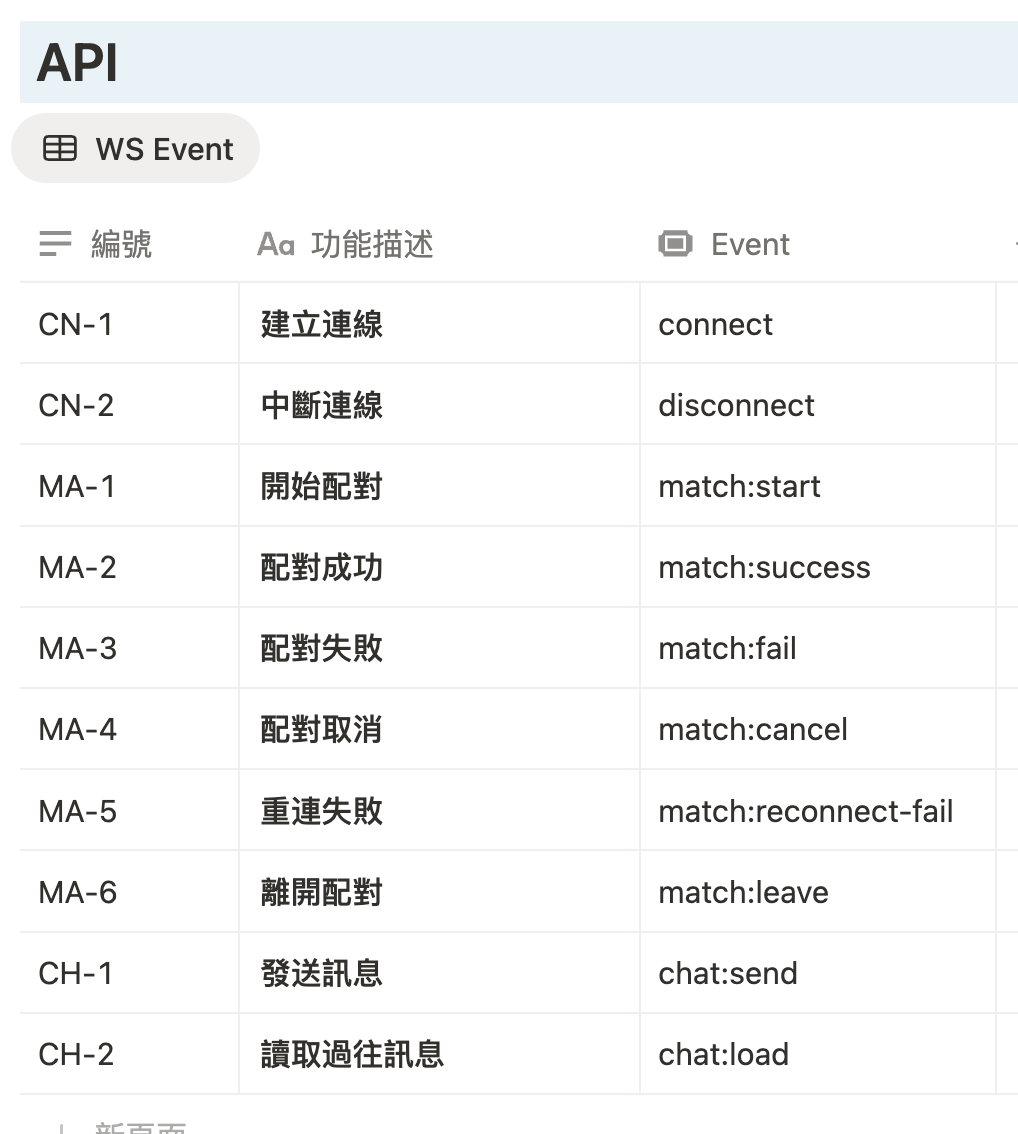
文件內文通常會再補上請求與回應的格式,但這邊我先偷懶不寫(欸
:::info
這裡有幾個事件是後續真的開始實作之後,發現需要再補一些狀態轉移的過程才新增上來的。一開始可能不會想得太多 XD
:::
如同規劃使用者故事時有提到,可行性的評估與執行是有優先順序的!所以目前列出的項目差不多是 MVP 的範圍了~~例外處理、偵測正在輸入訊息等等的機制,就可以安排在 MVP 實作完後進行。
現階段最重要的是確認整個專案的核心功能是可以被開發出來的。
啊怎麼沒有線稿圖?WooTalk 本體已經非常簡單了,我想這個階段就不用折磨自己(只是想偷懶)。
要先梳理流程圖或是模擬資料,我認為順序沒有很絕對,但我還沒有待過有 PM 跟 SA 的開發團隊,因此前期規劃的部份是依照我過去輔導學生做專題時的流程內容為基準,不一定和大家的實務開發完全符合,這點還請見諒 QQ

