
不論網路還是生活上的社交,難免都會有不知道要聊什麼的時候,如果不常看新聞或社群媒體,一時之間還真的會冷場......這時候就透過系統推薦的話題來亂聊一通吧!
這次的爬蟲功能主要是我在讀書會看到有伙伴這麼做,覺得超丐超實用所以試著做做看 XD
程式邏輯非常少:
其他的部分是自動化的設定:
git push 來推送最新的 JSON 檔不過這個功能我不想要跟專案本體汙染,所以會另外開一個 GitHub Repository 來管理。
我也沒有用過爬蟲,所以我就直接 Vibe Coding 了,請大家不要扁我(?)。
因為 Google Trends 的內容不是靜態的,和一般 SPA 一樣需要耗費一點時間動態載入,所以透過需要下這個參數 waitUntil: 'networkidle0' 等待表格內容長出來。
開始擷取元素之前,一定要先看過表格的 HTML 大概長怎樣,因為動態載入的內容還蠻多的,直接叫 AI 找的話,上下文的量可能會讓 AI 沒有辦法很準確地找到我們想要的文本:
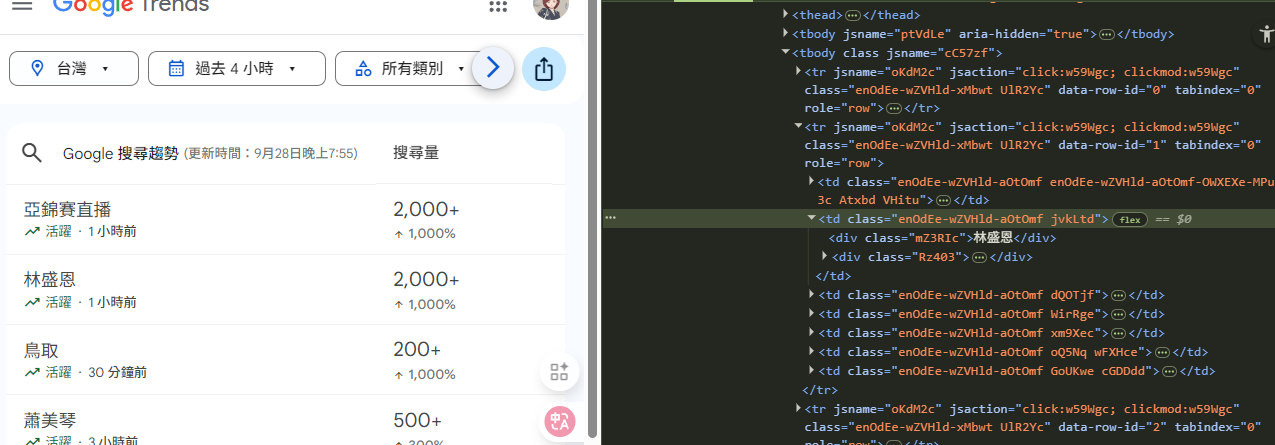
看 class 就知道都是動態生成的內容,所以沒辦法很輕鬆地找到固定的元素 QQ
如果擷取不到目標元素的話可以檢查是不是 querySelector 的選擇器下錯了:
const puppeteer = require('puppeteer');
const fs = require('fs');
async function getGoogleTrends() {
const browser = await puppeteer.launch({
headless: false,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
});
const page = await browser.newPage();
await page.goto('https://trends.google.com.tw/trending?geo=TW&hours=4', {
waitUntil: 'networkidle0',
});
try {
await page.waitForSelector('td', { timeout: 10000 });
} catch (error) {
console.log('等待元素載入超時');
await browser.close();
return;
}
const trends = await page.evaluate(() => {
const allRows = Array.from(document.querySelectorAll('tbody tr'));
return allRows
.map((row) => {
const cells = Array.from(row.querySelectorAll('td'));
if (cells.length > 1) {
const trendCell = cells[1];
if (trendCell) {
const firstDiv = trendCell.querySelector('div');
const text = firstDiv?.textContent?.trim() || '';
if (text) {
return { content: text };
}
}
}
return null;
})
.filter((item) => item !== null);
});
console.log('擷取到的趨勢:', trends);
await browser.close();
const output = {
updated: new Date().toISOString(),
trends: trends,
};
fs.writeFileSync('google-trends.json', JSON.stringify(output, null, 2));
console.log('Google Trends 資料已儲存至 google-trends.json');
}
getGoogleTrends();
接著就可以執行看看爬取的結果: ``
{
"updated": "2025-09-28T12:09:23.995Z",
"trends": [
{
"content": "亞錦賽直播"
},
]
}
不過執行成功不代表沒事,Google 可能還是會針對爬蟲機器人做一些限制,某天可能我們的腳本就突然爬不到了,所以需要加上一些瀏覽器資料的偽造,還有隨機延遲時間來模擬人類的行為:
const puppeteer = require('puppeteer');
const fs = require('fs');
// 設定隨機 User-Agent
const userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_2) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Safari/605.1.15',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edge/124.0.0.0 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 17_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Mobile/15E148 Safari/604.1',
];
const randomUserAgent =
userAgents[Math.floor(Math.random() * userAgents.length)];
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox'],
});
const page = await browser.newPage();
// 設定 User-Agent
await page.setUserAgent(randomUserAgent);
// 設定視窗大小
await page.setViewport({ width: 1920, height: 1080 });
// 加入隨機延遲 (2-5秒)
const randomDelay = Math.floor(Math.random() * 3000) + 2000;
console.log(`等待 ${randomDelay}ms...`);
await new Promise((resolve) => setTimeout(resolve, randomDelay));
// 略
}
爬蟲的邏輯就差不多完成啦!
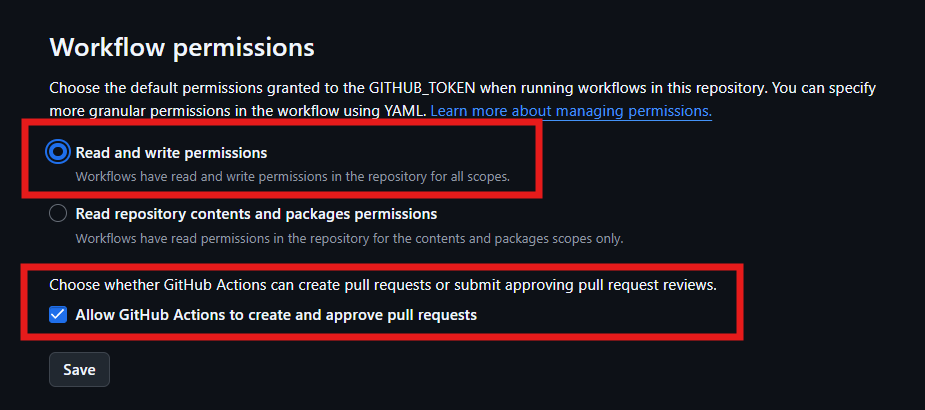
在開始設定 workflow 之前,要先去 Repository 設定自動化作業的權限,在 Settings > Actions > General,允許 GitHub Actions 讀寫整個專案:
然後在根目錄新增 .github/workflows/update-trends.yml:
name: Update Google Trends
on:
push:
branches:
- google-trends
schedule:
- cron: "5,35 * * * *" # 每小時第 5 和 35 分鐘執行
workflow_dispatch: # 保留手動觸發的選項
jobs:
update:
runs-on: ubuntu-latest
steps:
- name: Checkout Repo
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v4
with:
node-version: 18
- name: Install pnpm
run: npm install -g pnpm
- name: Install dependencies
run: pnpm install
- name: Force install Chromium for Puppeteer
run: npx puppeteer browsers install chrome
- name: Run Puppeteer Scraper
run: pnpm run start
- name: Commit and Push Results
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
git config --global user.name "github-actions[bot]"
git config --global user.email "github-actions[bot]@users.noreply.github.com"
# 保存爬蟲的新資料
cp google-trends.json /tmp/google-trends.json
# 拉取最新的程式碼
git pull origin google-trends
# 把新爬到的資料覆蓋回去
cp /tmp/google-trends.json google-trends.json
# 提交並推送
git add google-trends.json
git commit -m "update google trends [CI] $(TZ=Asia/Taipei date '+%Y-%m-%d %H:%M:%S')" || echo "Nothing to commit"
git push https://x-access-token:${GITHUB_TOKEN}@github.com/${{ github.repository }}.git HEAD:google-trends
這個 workflow 的行為就等同於我們在本機執行了爬蟲,然後再做 git push 更新資料。只是這段流程改為透過 GitHub Actions 提供的 schedule: - cron: 排程功能幫我們定時執行:
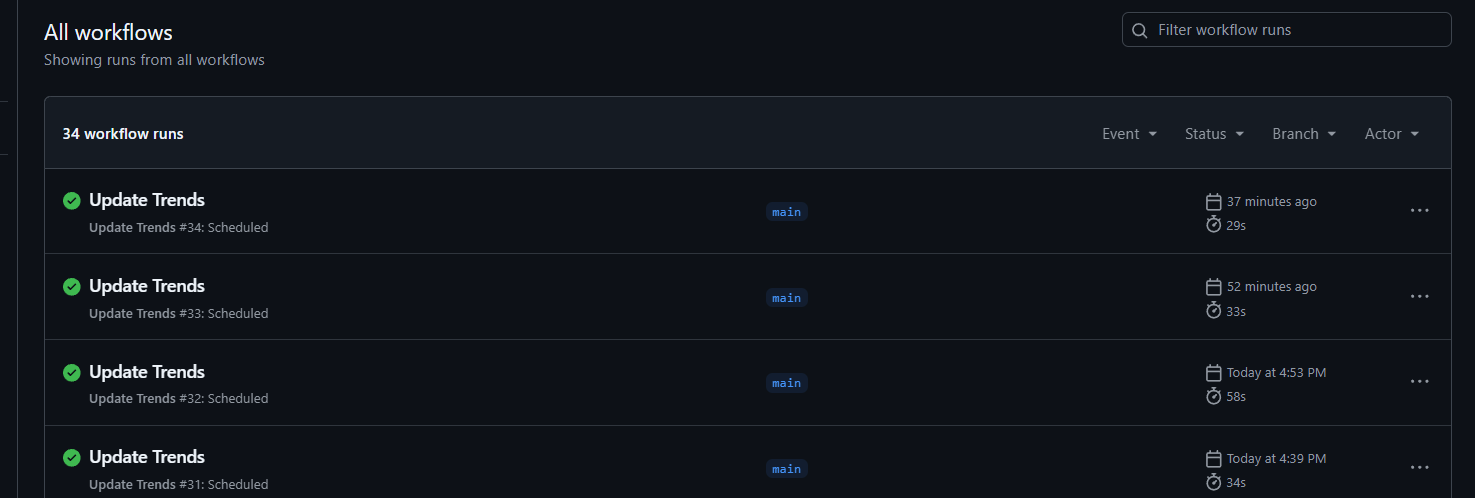
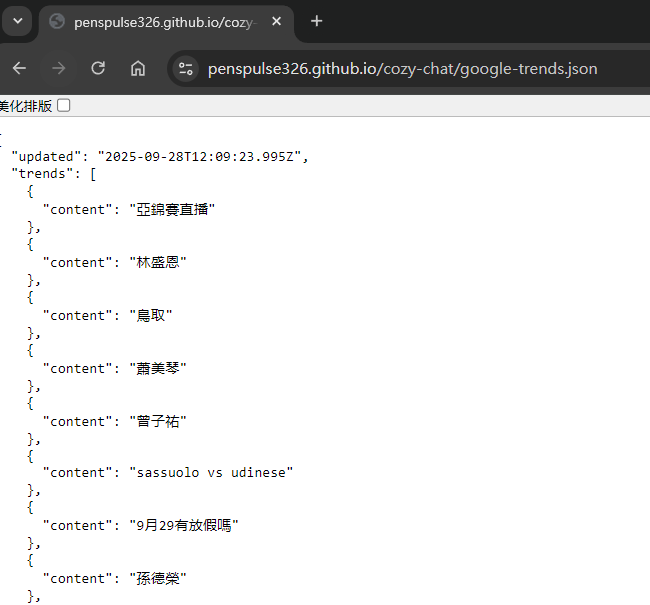
推送的時候我有先將 JSON 設為空陣列,測試看看腳本有沒有被觸發,讓 JSON 被寫入:
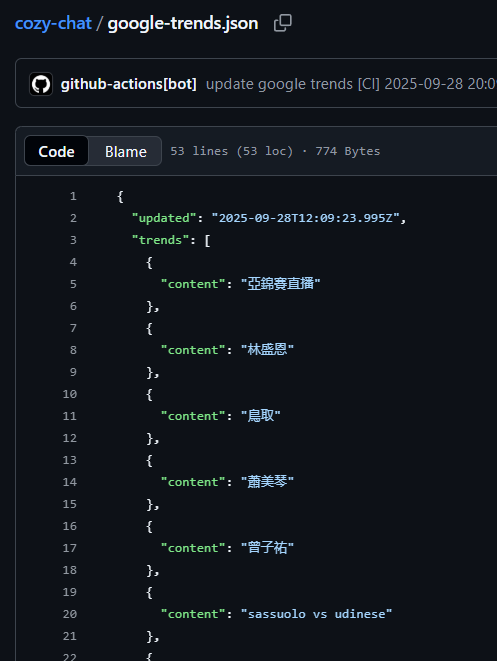
確定可以觸發之後就可以透過拿到 raw file 的 URL 拿到原始的 JSON 內容啦!
:::warning
workflow 如果有設定排程的話,預設分支(default branch)裡面一定要有這支 workflow,否則排程是不會生效的。
:::
因為我們設計了定時爬蟲,所以這份清單至少在排程的間隔內是固定不變的,那麼前端其實就不需要每次配對的時候都去打 API,這時就可以發揮 Next 的優勢!
原本首頁都是透過 use client 宣告的內容,所以先分離到其他檔案,再來就可以施展魔法,利用 Next 封裝過的 fetch 把資料快取起來並設定 revalidate 為 30 分鐘:
import ClientPage from './client-page';
async function getTrends() {
const res = await fetch(
'https://penspulse326.github.io/cozy-chat/google-trends.json',
{
next: {
revalidate: 1800, // 30 分鐘
},
}
);
if (!res.ok) {
throw new Error('Failed to fetch trends');
}
return res.json();
}
export default async function Home() {
const data = await getTrends();
return <ClientPage trends={data.trends} />;
}
指定頁面重新生成的週期,可以讓所有連上來的使用者都暫時閱讀到同一批靜態資料頁面,這種方式也稱作 ISR,是延伸自 SSG 的一種渲染方式。
拿到的資料再透過 props 一路往下傳給訊息盒!
搜尋趨勢的清單長度是不定的,但大多時候都會有十多筆,不可能在畫面上推薦話題的時候,全部列出來(先被系統洗頻一波),所以我設定隨機取出 5 筆,低於 5 筆就全部取出:
const filteredTrends = trends
.filter((trend: { content: string }) => trend.content !== '')
.sort(() => Math.random() - 0.5)
.slice(0, Math.min(5, trends.length));
推薦話題的時候會插入 Google 搜尋結果的 URL,格式是這樣:
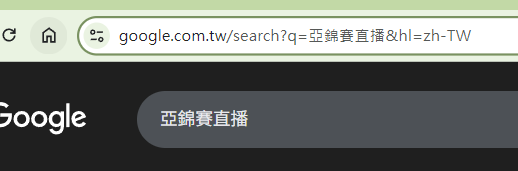
所以只要替換掉 q= 這段 query string 的內容即可:
{filteredTrends.map((trend: { content: string }) => (
<Text className={styles.chatBoxTopic}>
來聊聊
<Link
href={`https://www.google.com.tw/search?q=${trend.content}&hl=zh-TW`}
target="_blank"
rel="noopener noreferrer"
>
{trend.content}
</Link>
吧
</Text>
))}
來尬聊一波吧!

雖然大概知道爬蟲在做什麼,但實際去看程式碼運作的過程還是頭一遭!包含無頭瀏覽器、瀏覽器偽造等等,算是透過 Vibe Coding 學到了新知識!
Next App Router 也把 server side 取資料的方式變簡單了,全部都在 Page 元件呼叫 fetch 並設定好快取時間即可,如果是以前的 Page Router 就...概念也差不多,只是要呼叫 getStaticProps 或 getServerSideProps,但我在專題時期用得不多,後來再碰 Next 的時候都是寫 App Router 了,不曉得有沒有發生過什麼宗教戰爭 XD

