
昨天,我才剛把探險船派去收集論文寶藏,辛苦打撈回來一堆 metadata 與沉重的 PDF。船員們滿臉興奮,卻又困惑地看著我:「船長,這些寶物拿回來要怎麼放?就算堆滿倉庫,也找不到想要的東西啊!」
我只能苦笑。沒錯,知識的價值不在於堆放,而在於能快速找到並使用。今天的任務,就是要把這些散亂的文字寶藏,轉化為能即刻召喚的「知識坐標」,並存放到神秘的 Qdrant 大圖書館。換句話說——我要打開屬於知識的傳送門。
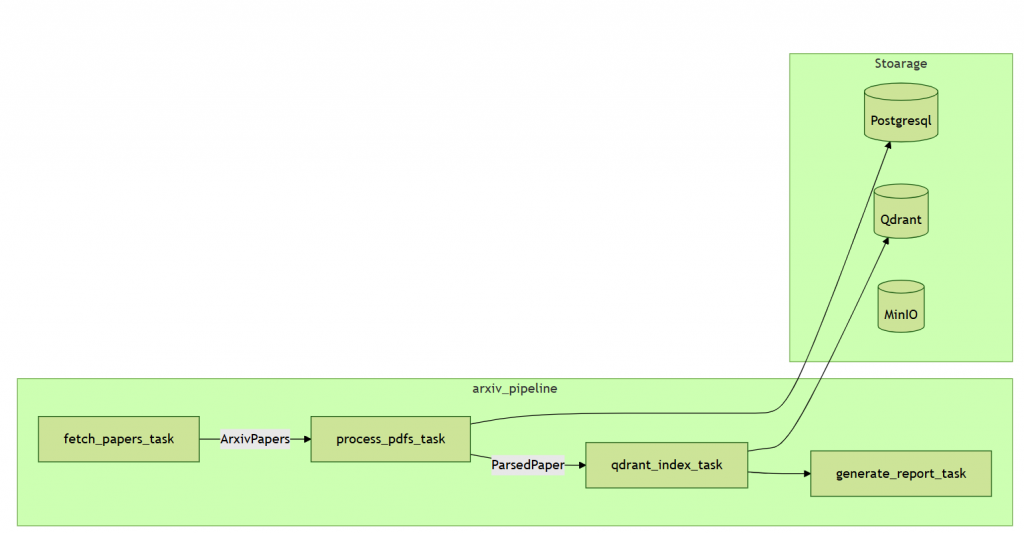
今天,我要帶著這些散落的寶藏,走完探險航線的後半段。這一段主要有兩個任務:
arxiv_pipeline
├─ qdrant_index_task → 將 PDF 內容向量化並上傳 Qdrant
└─ generate_report_task → 生成每日抓取與處理報告
在 Arxiv Pipeline 的後半段,主要包含兩個任務:
先給出 arxiv pipeline
def arxiv_pipeline(
date_from: str, date_to: str, max_results: int = 10, store_to_db: bool = True
):
results = {
"papers_fetched": 0,
"pdfs_downloaded": 0,
"pdfs_parsed": 0,
"papers_stored": 0,
"papers_indexed": 0,
"errors": [],
"processing_time": 0,
}
logger.info("results")
start_time = datetime.now()
# Step 1: Fetch paper metadata from arXiv
# Step 2: Process PDFs if requested
# Step 3: Qdrant Index
indexed_count, _ = qdrant_index_task(papers, pdf_results.get("parsed_papers", {}))
results["papers_indexed"] = indexed_count
print(f"Qdrant Index {indexed_count}")
# Calculate total processing time
processing_time = (datetime.now() - start_time).total_seconds()
results["processing_time"] = processing_time
result_summary = {
"papers_fetched": len(papers),
"pdfs_downloaded": pdf_results.get("downloaded", 0),
"pdfs_parsed": pdf_results.get("parsed", 0),
"papers_indexed": indexed_count,
"papers_stored": pdf_results["papers_stored"],
"errors": pdf_results.get("errors", []),
}
# 呼叫日報告 task
report = generate_report_task(result_summary)
print(f"\n{report}")
當我們解析完 PDF,拿到的只是純文字。如果直接存進資料庫,檢索起來就像是在翻老舊倉庫:要找到一段相關內容,就得一頁頁翻,效率極差。
為了解決這個問題,業界常用 向量化 (Embedding) 技術,將文字轉換成高維度的數學向量。這樣一來,我們可以用「語意相似度」檢索,而不是單純的關鍵字比對。
在這裡,我選用了 HuggingFace 的 all-mpnet-base-v2 模型,它會把一段文字轉換成 768 維的向量。這些向量之間的距離,代表語意上的相似程度。
流程如下:
from typing import List
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-mpnet-base-v2") # 輸出向量維度是 768
def get_embedding(text: str) -> List[float]:
vector = model.encode(text)
return vector.tolist()
使用 HuggingFace 的 all-mpnet-base-v2 預訓練模型。
這個模型輸出 768 維的向量。
適合做:語義搜尋 (semantic search)、聚類 (clustering)、文本相似度計算
💡小技巧
SentenceTransformer("all-mpnet-base-v2") 寫在函式裡,每次呼叫函式就會重新初始化模型,速度會慢很多,也浪費記憶體。不過,向量化有一個現實問題:它很慢。要把一整篇 PDF 拆成數百個片段,每個片段都要丟進模型跑一遍,然後還要上傳到 Qdrant。如果逐筆處理,速度會像烏龜爬行。
為了加快效率,我採用了「分批上傳」策略:
QDRANT_BATCH_SIZE,每累積到一定數量,就一次上傳到 Qdrant。同時,我還得準備應對失敗情況。就像探險途中,有些卷軸可能破損、有些水晶鍛造失敗。於是我在程式碼裡設計了錯誤捕捉,會把失敗的 paper ID 收集起來,方便事後補救。
def chunk_text(
text: str, chunk_size: int = CHUNK_SIZE, overlap: int = CHUNK_OVERLAP
) -> List[str]:
"""
將長文本切分成多個 chunk
"""
if not text:
return []
chunks = []
start = 0
text_length = len(text)
while start < text_length:
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap # 保留 overlap
if start < 0:
start = 0
if start >= text_length:
break
return chunks
qdrant_index_task codedef qdrant_index_task(
papers: List[ArxivPaper], parsed_papers: Dict[str, ParsedPaper]
) -> int:
"""
將 papers 轉成向量並上傳到 Qdrant
"""
points: List[models.PointStruct] = []
idx = 0
batch_points: List[models.PointStruct] = []
failed_papers = []
for paper in papers:
try:
parsed_paper = parsed_papers.get(paper.arxiv_id)
text = parsed_paper.pdf_content.raw_text
print(f"{paper.arxiv_id} 抽取文字長度: {len(text)}")
if not text:
continue
metadata = {
"arxiv_id": paper.arxiv_id,
"abstract": paper.abstract,
"title": paper.title,
"authors": paper.authors,
"categories": paper.categories,
"published_date": paper.published_date,
}
# 切分 chunk
chunks = chunk_text(text)
for chunk_idx, chunk in enumerate(chunks):
vector = get_embedding(chunk)
payload = {**metadata, "text": chunk, "chunk_idx": chunk_idx}
point = models.PointStruct(id=idx, vector=vector, payload=payload)
points.append(point)
batch_points.append(point) # ✅ 把 point 加入 batch
idx += 1
# 每到 batch_size 就上傳一次
if len(batch_points) >= QDRANT_BATCH_SIZE:
qdrant_client.upsert(
collection_name=COLLECTION_NAME, points=batch_points
)
logger.info(f"✅ 上傳 batch {len(batch_points)} points 到 Qdrant")
batch_points = []
except Exception as e:
logger.error(f"❌ paper {paper.arxiv_id} 發生錯誤: {e}")
failed_papers.append(paper.arxiv_id)
continue
# 上傳剩下的不足 batch 的 points
if batch_points:
qdrant_client.upsert(collection_name=COLLECTION_NAME, points=batch_points)
logger.info(f"✅ 上傳最後 batch {len(batch_points)} points 到 Qdrant")
else:
logger.info("⚠️ 無可上傳的 papers 到 Qdrant")
return len(points), failed_papers
💡 小技巧:向量化是耗時操作,建議分批處理與非同步,避免阻塞 pipeline。
功能:把已解析的 PDF 文字轉成向量,並上傳到 Qdrant 向量資料庫。
輸入:
papers:抓取到的論文 metadata 列表parsed_papers:已解析 PDF 文字的對應字典回傳:成功上傳的向量數量,以及處理失敗的論文 ID最後,我們會生成每日抓取與處理報告,方便追蹤 pipeline 執行情況:
def generate_report_task(result_summary: Dict):
report = f"""
Arxiv Pipeline Daily Report
---------------------------
Papers fetched: {result_summary['papers_fetched']}
PDFs downloaded: {result_summary['pdfs_downloaded']}
PDFs parsed: {result_summary['pdfs_parsed']}
Papers indexed: {result_summary['papers_indexed']}
Papers stored: {result_summary['papers_stored']}
Errors: {len(result_summary['errors'])}
"""
print(report)
# 可擴充:存入 DB 或發送 Slack 通知
return report
📄 Arxiv Ingestion Report @ 2025-09-11T00:38:42.227617
- Papers fetched: 3
- PDFs downloaded: 3
- PDFs parsed: 3
- PDFs Index: 459
- Papers stored: 3
- Errors: 0
未來還可以擴充:例如把報告存到資料庫,或自動發送到 Slack 通知團隊。
到此為止,我們的 Arxiv Pipeline 已經能 自動抓取論文、處理 PDF、生成向量索引、並提供檢索能力。
至此,我們已經打開了知識的傳送門,讓散落的文字寶藏化為可檢索的知識座標。接下來,這些寶藏要如何被妥善保存與取用?那就是下一章的冒險了。
完整 Arxiv Pipeline 前半段程式碼:GitHub 連結

 iThome鐵人賽
iThome鐵人賽