
每個冒險者在啟程時,都需要一張地圖和一艘堅固的船。對我來說,今天的任務就是打造這艘「探險船」——讓它能在浩瀚的學術大海裡,找到正確的島嶼(論文 metadata),並在登島後把寶藏(PDF)安全帶回營地。聽起來很帥,但實際上更像是一個程序員邊 Debug 邊划破船補洞的冒險。
今天要介紹 Arxiv Pipeline 的前半段:
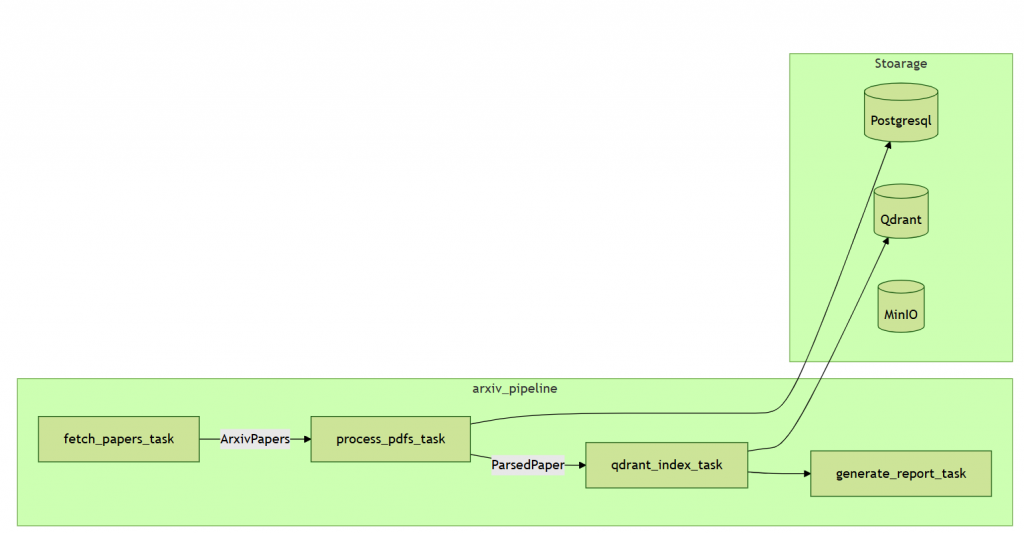
fetch_papers_task:派出探險船,找到正確的小島 —— 抓取論文的 metadata。process_pdfs_task:登上島嶼,收集寶藏 —— 下載並解析 PDF。把這兩個任務拆開的好處:
fetch_papers_task:專注於 論文資訊,流程單純、維護容易。process_pdfs_task:專門處理 PDF 下載、快取與解析,方便重試,且能用非同步並行加速處理。arxiv_pipeline
├─ fetch_papers_task → 抓取 metadata
├─ process_pdfs_task
│ ├─ process_pdfs_batch → 下載與解析 PDF
│ └─ store_to_db → 存入資料庫
├─ qdrant_index_task → 向量化並上傳 Qdrant
└─ generate_report_task → 生成日報告
全貌
def arxiv_pipeline(
date_from: str, date_to: str, max_results: int = 10, store_to_db: bool = True
):
results = {
"papers_fetched": 0,
"pdfs_downloaded": 0,
"pdfs_parsed": 0,
"papers_stored": 0,
"papers_indexed": 0,
"errors": [],
"processing_time": 0,
}
logger.info("results")
start_time = datetime.now()
# Step 1: Fetch paper metadata from arXiv
papers = asyncio.run(fetch_papers_task(date_from, date_to, max_results))
results["papers_fetched"] = len(papers)
# Step 2: Process PDFs if requested
pdf_results = {}
if papers:
pdf_results = asyncio.run(process_pdfs_task(papers, store_to_db=True))
results["pdfs_downloaded"] = pdf_results["downloaded"]
results["pdfs_parsed"] = pdf_results["parsed"]
results["errors"].extend(pdf_results["errors"])
results["papers_stored"] = pdf_results["papers_stored"]
print(f"Stored {pdf_results['papers_stored']} papers in DB")
# Step 3: Qdrant Index
indexed_count, _ = qdrant_index_task(papers, pdf_results.get("parsed_papers", {}))
results["papers_indexed"] = indexed_count
result_summary = {
"papers_fetched": len(papers),
"pdfs_downloaded": pdf_results.get("downloaded", 0),
"pdfs_parsed": pdf_results.get("parsed", 0),
"papers_indexed": indexed_count,
"papers_stored": pdf_results["papers_stored"],
"errors": pdf_results.get("errors", []),
}
# 呼叫日報告 task
report = generate_report_task(result_summary)
在此之前 先來看看 arXiv API 的使用限制、抓取方式及 PDF 處理建議。
Rate limit 控制
if self._last_request_time:
delta = time.time() - self._last_request_time
if delta < self.rate_limit_delay:
await asyncio.sleep(self.rate_limit_delay - delta)
self._last_request_time = time.time()
提供程式化存取 arXiv 電子印刷品(e-print)資料
功能:
特性:
發送 HTTP 請求
async with httpx.AsyncClient(timeout=self.timeout_seconds) as client:
resp = await client.get(url)
resp.raise_for_status()
xml_data = resp.text
http://export.arxiv.org/api/query?search_query=all:electron&start=0&max_results=10
參數:
search_query → 搜尋關鍵字start → 從第幾筆開始max_results → 回傳筆數上限回傳資料:每篇論文包含:
<title>
<summary>
<author>
<link>
<arxiv:primary_category>
base_url = "https://export.arxiv.org/api/query"
params = {"search_query": "cat:cs.AI", "max_results": 10}
# => https://export.arxiv.org/api/query?search_query=cat:cs.AI&max_results=10
抓 metadata(標題、摘要、作者) ✅
抓 PDF ⚠️
程式語言支援:
urllib / httpx / feedparser
XML::Atom
feedtools
SimplePie
arxiv_pipeline
├─ fetch_papers_task → 抓取 metadata
├─ process_pdfs_task
│ ├─ process_pdfs_batch → 下載與解析 PDF
│ └─ store_to_db → 存入資料庫
├─ qdrant_index_task → 向量化並上傳 Qdrant
└─ generate_report_task → 生成日報告
fetch_papers_task抓取 metadata 就像派出探險船,先找到海上的小島位置。我使用 非同步 HTTP 請求,可以同時抓取多筆資料,提高效率。基本流程如下:
async def fetch_papers_task(
date_from: str, date_to: str, max_results: int = 5
) -> List[ArxivPaper]:
client = get_cached_services()
papers = await client.fetch_papers(
from_date=date_from, to_date=date_to, max_results=max_results
)
print(f"Fetched {len(papers)} papers from {date_from} to {date_to}")
return papers
⚡ 內部 fetch_papers 會處理:
- Rate limit 控制
- API URL 組裝與參數處理
- XML 解析、封裝成 ArxivPaper 物件
process_pdfs_task抓到 metadata 只是第一步,PDF 才是真正的寶藏。這個模組負責:
async def process_pdfs_task(papers: PDFParserService, store_to_db: bool):
pdf_parser = PDFParserService(max_pages=20, max_file_size_mb=10)
metadata_fetcher = MetadataFetcher(client, pdf_parser)
pdf_results = await metadata_fetcher.process_pdfs_batch(papers)
print(f"Processed PDFs: {pdf_results.get('parsed', 0)} parsed ")
if store_to_db:
stored_count = metadata_fetcher.store_to_db(
papers, pdf_results.get("parsed_papers", {})
)
return pdf_results
⚡ 注意:
- process_pdfs_batch 可重試與並行下載
- 解析後的文字可存入資料庫或用於後續向量化
