透過深度學習模型,自動判斷餐盤中的食物種類,並進一步估算營養成分,對於飲食管理、健康照護、餐飲業數位化轉型等場景具有極高的價值。然而,AI 模型的效能極大程度依賴於資料來源的品質與多樣性。因此,如何收集、整理並有效運用食物圖片資料,成為此領域的核心課題。
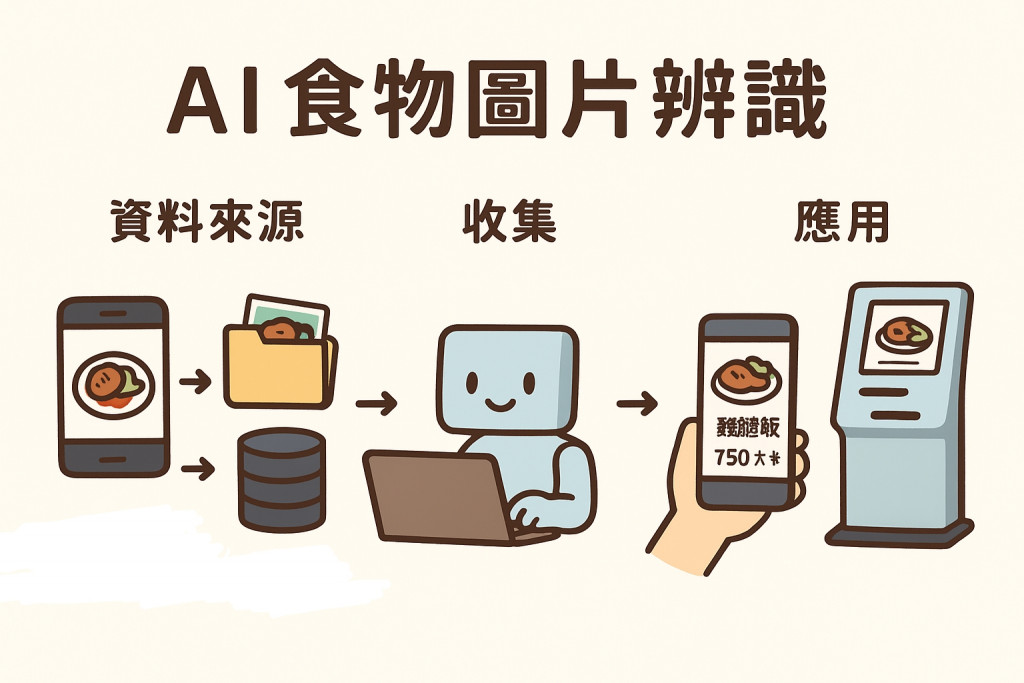
做 AI 食物辨識,最大的挑戰就是「有沒有好用的資料集」。
目前已有數個專門針對食物影像辨識的公開資料集,常見的包含:
這些資料集的優勢在於標準化,能用於模型的 baseline 訓練與比較。然而其侷限是:
多數資料來自歐美或日式飲食,缺乏在地化的食物,例如:台灣小吃。
圖片通常由美食平台或料理網站取得,與真實「生活拍攝」場景差異較大。
若要針對特定需求(例如:台灣便當、夜市美食、手搖飲料)建立精準模型,往往需要自建資料集。常見的收集方式包括:
由於部分食物(例如:湯品、剉冰)拍攝難度高,且拍攝環境光線不一,使用生成式 AI (GAN, Diffusion Models) 來建立合成影像資料。其優點在於能控制角度、光源、容器,增加模型對「 domain shift 」的耐受性。

即便資料來源多樣,仍需經過一系列資料處理流程,才能真正用於模型訓練。

為提升模型對不同環境的泛化能力,可使用:
單純辨識「這是蚵仔煎」不足以支持實務應用,必須結合知識庫:


 iThome鐵人賽
iThome鐵人賽