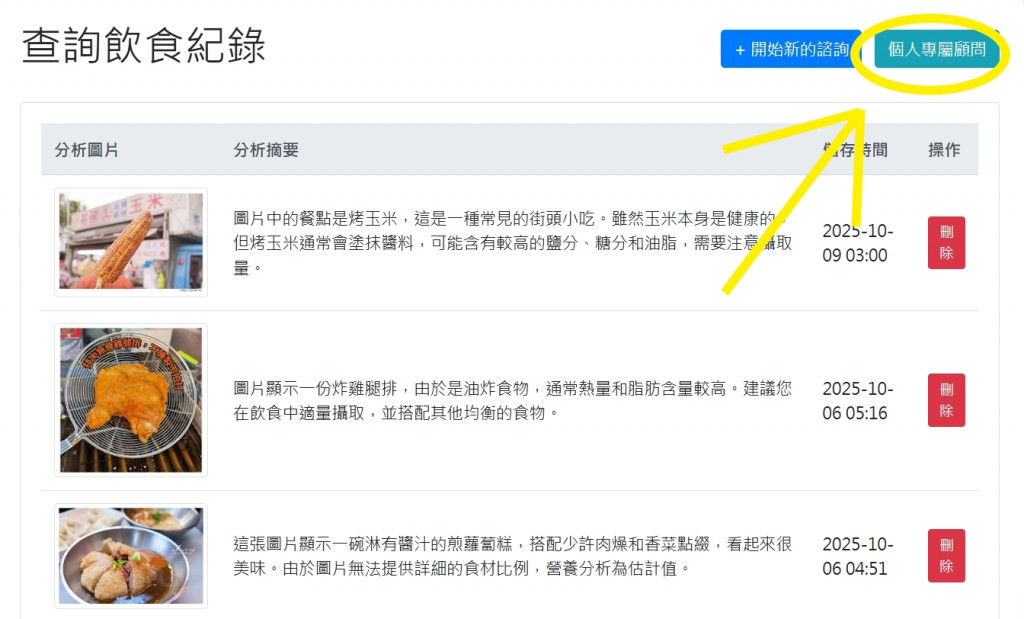
當個人飲食紀錄累積到一定數量時,就可以當成使用者個人的飲食參考資料,進一步讓 AI 做出更符合使用者的個人情況分析
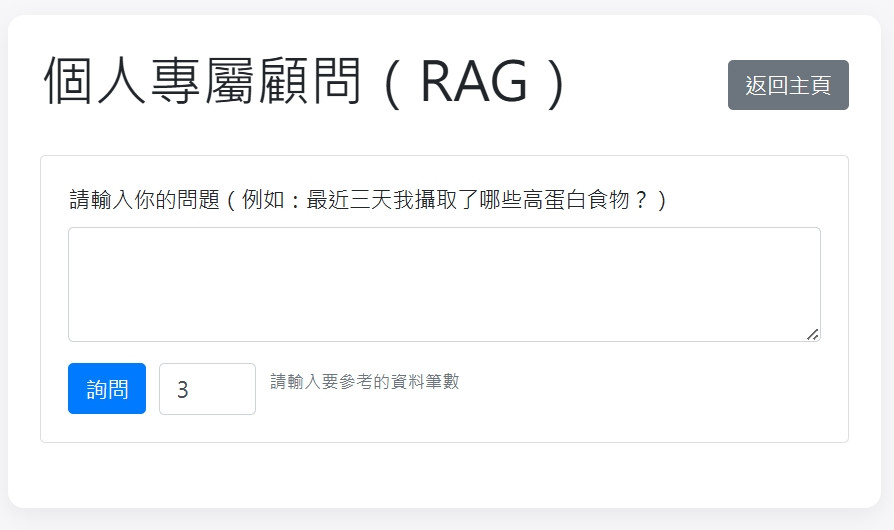
RAG (Retrieval-Augmented Generation) 是一種結合了「檢索」與「生成」的人工智慧技術架構。傳統的大型語言模型(LLM)像是一個知識淵博但記憶停留在過去某個時間點的「通才」,無法得知內部、私有或最新的資訊。
RAG 徹底改變了這一點。它的核心思想是:當使用者提出問題時,系統首先去一個特定的資料庫(例如:個人筆記、公司的內部文件、專案的歷史紀錄)中「檢索」最相關的資訊片段,然後將這些資訊片段連同原始問題一起「餵」給 LLM,讓它基於這些具體的、即時的資料來「生成」一個精確、有根據的回答。
簡單的說:
以專案中的 tests/test_rag_service.py 檔案為例:
期望 RAG 系統能做到兩件事:
所以,可以先寫下一個像 test_index_and_query 這樣的測試函式,由於此時專案的 rag_service.py 的 rebuild_index 和 query_records 函式都還沒寫,因此這個測試絕對是無法通過的(紅燈)。
def test_index_and_query(app):
"""測試 index_record 與 query_records 的基本行為。"""
with app.app_context():
# 1. 準備 (Arrange): 建立兩筆測試資料
db.create_all()
r1 = create_dummy_record(app, {
'summary': '羊肉爐,高蛋白,熱量高',
# ... 其他欄位
})
r2 = create_dummy_record(app, {
'summary': '沙拉,低卡路里,富含纖維',
# ... 其他欄位
})
# 2. 執行 (Act): 呼叫將要開發的函式
rebuild_index()
# 3. 斷言 (Assert): 驗證結果是否符合預期
# 斷言 1: 索引應該被建立了
assert len(INVERTED_INDEX) > 0
# 斷言 2: 查詢「羊肉」時,應該要能找到 r1 這筆紀錄
res = query_records('羊肉', top_k=2)
assert any(r['id'] == r1.id for r in res)
接著,請在 rag_service.py 中,加入 rebuild_index 和 query_records 兩個函式,目的就是讓上面這個測試從失敗變為成功。
rebuild_index 的程式碼需要遍歷資料庫中的 AnalysisRecord,並將 summary 等欄位後,填入 INVERTED_INDEX 這個全域變數中。query_records 的程式碼需要接收一個查詢詞(如 '羊肉'),去 INVERTED_INDEX 中找到對應的文件 ID,然後回傳文件的資訊。只要這兩個函式能滿足測試中的 assert 條件,測試就會通過(綠燈)。
測試通過後,就可以安心地進行優化 rebuild_index 和 query_records 的程式碼。例如:
tokenize 的準確度。query_records 加入更複雜的評分機制或 fallback 策略。每做一次修改,就要重新執行一次測試。只要測試依然是綠燈,就代表重構是OK的(沒有破壞原有的功能)。
OpenAI 官方說明,介紹 GPT 如何透過檢索增強生成,並減少幻覺風險。
Retrieval-Augmented Generation (RAG) and Semantic Search for GPTs — OpenAI Help
維基百科條目,提供 RAG 的歷史背景、學術來源與技術變體。
Retrieval-Augmented Generation (RAG) — Wikipedia
聚焦於 RAG 的安全與合規議題,解釋如何在企業環境中安全部署 RAG 模型。
Nightfall AI Security 101: What is Retrieval-Augmented Generation (RAG)?


 iThome鐵人賽
iThome鐵人賽