HI!大家好,我是 Shammi 😊
過去 12 天,我成功打造了一個能夠運作的 RAG 機器人囉!
但在實際測試中,我統整了遇到的問題:
👉 機器人說「找不到資料」:即使你的 PDF 中有相關內容,機器人仍然無法回答。
👉 回答不夠精準:機器人回覆的內容雖然來自你的知識庫,但與問題的相關性不夠高。
👉 對話缺乏連貫性:機器人只能回答單次問答,無法理解上下文。
這些問題的根源,都指向 RAG 架構中的兩大核心挑戰:檢索不精準和上下文理解不足。
今天,我將深入探討問題,並整理優化方案,試著讓機器人變得更聰明、更流暢。
👉 PDF 資料的稀疏性:如果 PDF 內容只簡短提及 SDGs 名稱,而沒有詳細的描述,檢索時就很難找到精準的資訊。
👉 文字切割(Chunking)的語義問題:當一個文字區塊太大或語義不集中時,向量化後也會變得「模糊」,導致檢索結果不準確。
👉 Embedding 模型的侷限:雖然我使用的 text-embedding-004 已經很強大,但對於某些非常專業或冷僻的術語,模型仍可能難以產生精準的向量。
要解決這些問題,需要從「檢索」和「生成」這兩大環節下手。
這一步是治本的方法。之前發現機器人無法回答「永續海洋」的問題,正是因為 PDF 內容在這方面的描述不夠豐富。
👉 提供更詳盡的資料:擴充 PDF 內容,針對每個 SDGs 目標,提供更詳細的定義、具體措施和案例。
👉 優化 PDF 排版:使用更清晰的標題、條列式清單,讓文字區塊在切割後,能保有完整的語義。
即使資料本身有優化,也可以透過調整程式碼來提升準確性。
👉 增加檢索數量 (k):目前我設定 k=3,也就是檢索最相似的三個區塊。日後優化或測試可以嘗試增加 k 值,例如設定為 k=5 或 k=10。這能增加機器人找到相關資訊的機會,但同時也會增加 LLM 處理的上下文長度。
👉 重新切割文字區塊:嘗試調整 chunk_size 和 chunk_overlap。例如,將 chunk_size 縮小到 500,讓每個區塊的語義更集中。
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,#可以縮小文字區塊
chunk_overlap=200,
length_function=len
目前機器人無法記住先前的對話,如果要解決這個問題,則需要儲存「對話歷史」也一併傳遞給 LLM。
👉 儲存對話歷史:在 app.py 中,可以使用 Streamlit 的 st.session_state 來儲存每一輪的對話。
👉 將歷史對話加入 Prompt:在 generate_response 函式中,將對話歷史作為上下文的一部分,與當前的問題和檢索結果一起傳給 LLM。
以下是一個簡單的程式碼修改範例,將展示如何讓機器人具備記憶能力。
將 Day 12 的Streamlit 介面程式碼調整如下範例:
# ========== Streamlit 介面程式碼 (新版對話介面) ==========
st.title("🌱 SDGs 知識機器人 - 阿米")
st.write("嗨,我是阿米!一個能回答關於永續發展目標 (SDGs) 的小機器人。請問有什麼想知道的嗎?")
#建立一個儲存對話歷史的狀態
if "messages" not in st.session_state:
st.session_state.messages = []
#在這裡顯示歷史對話
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
#接收使用者輸入
if prompt := st.chat_input("有什麼關於 SDGs 的問題嗎?"):
#將使用者輸入加入對話歷史
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
#產生並顯示機器人回覆
with st.chat_message("assistant"):
with st.spinner("阿米正在努力思考中..."):
full_context = "\n".join([msg["content"] for msg in st.session_state.messages])
answer = get_rag_answer(f"過去的對話:\n{full_context}\n\n新的問題:{prompt}")
st.markdown(answer)
st.session_state.messages.append({"role": "assistant", "content": answer})#將機器人回覆也加入對話歷史
參考結果: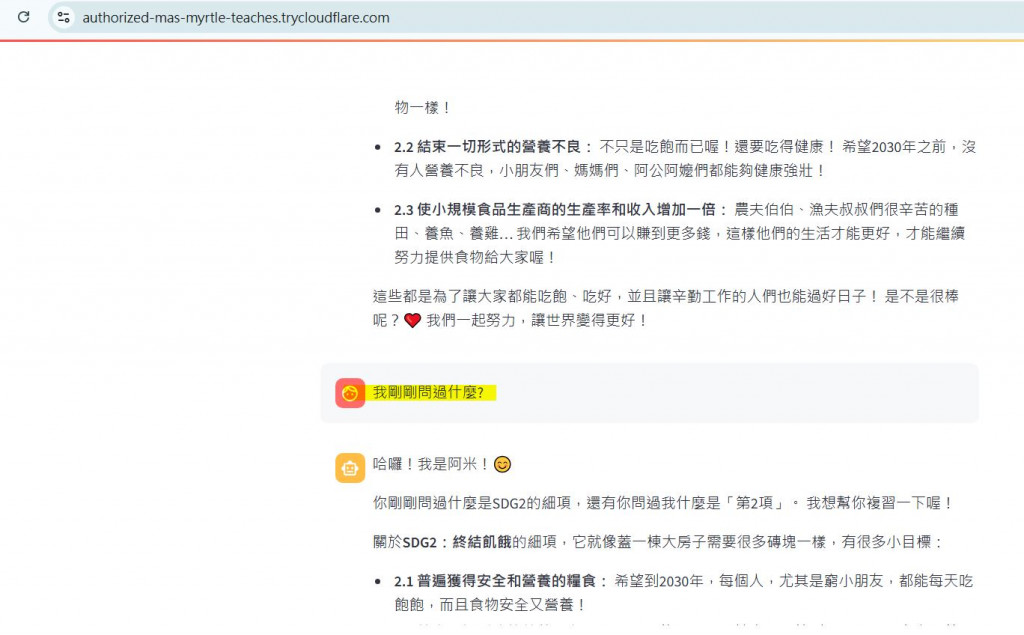
今天我深入探討了 RAG 系統的常見問題,並提供了多種優化方案,讓 AI 對話機器人回覆更精準、對話更流暢。接下來,我將進入最後的實戰環節:部署到 LINE 和 Telegram。這是將專案從原型變成真正應用程式的關鍵一步!

