今天我們來介紹幾個Turtle Island提供的函數。
本日大綱如下:
ti.make_index()
ti.case_when()
ti.bucketize()
ti.is_every_nth_row()
import polars as pl
import turtle_island as ti
from great_tables import GT, style, loc
ti.make_index()def make_index(offset: int = 0, *, name: str = "index") -> pl.Expr:
ti.make_index()參考自pl.DataFrame.with_row_index(),可以產生一列連續整數作為索引之用。
舉例來說,現有df1 dataframe如下:
df1 = pl.DataFrame({"a": [1, 3, 5], "b": [2, 4, 6]})
shape: (3, 2)
┌─────┬─────┐
│ a ┆ b │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═════╪═════╡
│ 1 ┆ 2 │
│ 3 ┆ 4 │
│ 5 ┆ 6 │
└─────┴─────┘
使用ti.make_index()可以生成「"index"」列,為由0開始之連續整數:
df1.select(ti.make_index(), pl.all())
shape: (3, 3)
┌───────┬─────┬─────┐
│ index ┆ a ┆ b │
│ --- ┆ --- ┆ --- │
│ u32 ┆ i64 ┆ i64 │
╞═══════╪═════╪═════╡
│ 0 ┆ 1 ┆ 2 │
│ 1 ┆ 3 ┆ 4 │
│ 2 ┆ 5 ┆ 6 │
└───────┴─────┴─────┘
相當於呼叫df1.with_row_index()。
ti.case_when()def case_when(
case_list: Sequence[tuple[pl.Expr | tuple[pl.Expr], pl.Expr]],
otherwise: pl.Expr | None = None,
) -> pl.Expr:
ti.case_when()的靈感來自於pd.Series.case_when(),相比於Polars的when-then-otherwise寫法,我覺得會更加容易閱讀。
舉例來說,現有df2 dataframe如下:
df2 = pl.DataFrame({"x": [1, 2, 3]})
shape: (3, 1)
┌─────┐
│ x │
│ --- │
│ i64 │
╞═════╡
│ 1 │
│ 2 │
│ 3 │
└─────┘
請依照下列條件,新生成「"y"」列:
如果使用when-then-otherwise的話,可以這麼寫:
(
df2.with_columns(
pl.when(pl.col("x").le(1))
.then(pl.lit("small"))
.when(pl.col("x").ge(3))
.then(pl.lit("large"))
.otherwise(pl.lit("medium"))
.alias("y")
)
)
如果使用ti.case_when()的話,則是:
(
df2.with_columns(
ti.case_when(
case_list=[
(pl.col("x").le(1), pl.lit("small")),
(pl.col("x").ge(3), pl.lit("large")),
],
otherwise=pl.lit("medium"),
).alias("y")
)
)
兩者皆會得到相同的結果:
shape: (3, 2)
┌─────┬────────┐
│ x ┆ y │
│ --- ┆ --- │
│ i64 ┆ str │
╞═════╪════════╡
│ 1 ┆ small │
│ 2 ┆ medium │
│ 3 ┆ large │
└─────┴────────┘
ti.bucketize()def bucketize(
*exprs: pl.Expr | Iterable[pl.Expr],
return_dtype: pl.DataType | pl.DataTypeExpr | None = None,
) -> pl.Expr:
ti.bucketize()可以讓我們根據行所在的位置,來進行循環分組計算。
舉例來說,現有df3 dataframe如下:
df3 = pl.DataFrame({"x": [1, 2, 3, 4, 5]})
shape: (5, 1)
┌─────┐
│ x │
│ --- │
│ i64 │
╞═════╡
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
└─────┘
請依照下列條件,新生成「"bucketized"」列:
如果您嘗試使用Polars來解這個題目,應該會發現寫出來的程式碼冗長且難以閱讀。更糟糕的是,當循環的組數不是定值時,還需使用when-then-otherwise不斷添加分支並修改邏輯。
使用ti.bucketize(),可以優雅地解決這個問題:
(
df3.with_columns(
ti.bucketize(pl.col("x").add(10), pl.lit(100)).alias("bucketized")
)
)
shape: (5, 2)
┌─────┬────────────┐
│ x ┆ bucketized │
│ --- ┆ --- │
│ i64 ┆ i64 │
╞═════╪════════════╡
│ 1 ┆ 11 │
│ 2 ┆ 100 │
│ 3 ┆ 13 │
│ 4 ┆ 100 │
│ 5 ┆ 15 │
└─────┴────────────┘
ti.bucketize()是廣義的循環分組計算函數(可以使用如pl.col("x").add(10)的expr),如果只是想根據行的位置進行循環分組,可以參考ti.bucketize_lit()。
ti.is_every_nth_row()def is_every_nth_row(
n: int, offset: int = 0, *, name: str = "bool_nth_row"
) -> pl.Expr:
ti.is_every_nth_row()可以快速標記各行是否為第n行的倍數。
舉例來說,現有df4 dataframe如下:
df4 = pl.DataFrame({"x": [1, 2, 3, 4, 5, 6, 7]})
shape: (7, 1)
┌─────┐
│ x │
│ --- │
│ i64 │
╞═════╡
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
└─────┘
請依照下列條件,新生成「"bool_nth_row "」列:
True。False。使用ti.is_every_nth_row(2)可以這麼寫:
df4.with_columns(ti.is_every_nth_row(2))
shape: (7, 2)
┌─────┬──────────────┐
│ x ┆ bool_nth_row │
│ --- ┆ --- │
│ i64 ┆ bool │
╞═════╪══════════════╡
│ 1 ┆ true │
│ 2 ┆ false │
│ 3 ┆ true │
│ 4 ┆ false │
│ 5 ┆ true │
│ 6 ┆ false │
│ 7 ┆ true │
└─────┴──────────────┘
其中n=2代表每兩行一組,各組第一個元素為True,另一個元素為False。
ti.is_every_nth_row()可以說是Turtle Island中小弟最喜歡的函數,尤其是作為Great Tables的行選擇器更是好用,以下舉例說明。
我們使用教學文件中的寶可夢為例:
# https://docs.pola.rs/user-guide/expressions/window-functions/
types = (
"Grass Water Fire Normal Ground Electric Psychic Fighting Bug Steel "
"Flying Dragon Dark Ghost Poison Rock Ice Fairy".split()
)
url = (
"https://gist.githubusercontent.com/ritchie46/"
"cac6b337ea52281aa23c049250a4ff03/"
"raw/89a957ff3919d90e6ef2d34235e6bf22304f3366/"
"pokemon.csv"
)
type_enum = pl.Enum(types)
pokemon = (
pl.read_csv(url)
.cast({"Type 1": type_enum})
.sort("Type 1")
.select(
pl.col("Type 1")
.head(3)
.over("Type 1", mapping_strategy="explode"),
pl.col("Name")
.sort_by(pl.col("Speed"), descending=True)
.head(3)
.over("Type 1", mapping_strategy="explode")
.alias("fastest/group"),
pl.col("Name")
.sort_by(pl.col("Attack"), descending=True)
.head(3)
.over("Type 1", mapping_strategy="explode")
.alias("strongest/group"),
)
.head(9)
)
shape: (9, 3)
┌────────┬───────────────────────────┬───────────────────────────┐
│ Type 1 ┆ fastest/group ┆ strongest/group │
│ --- ┆ --- ┆ --- │
│ enum ┆ str ┆ str │
╞════════╪═══════════════════════════╪═══════════════════════════╡
│ Grass ┆ Venusaur ┆ Victreebel │
│ Grass ┆ VenusaurMega Venusaur ┆ VenusaurMega Venusaur │
│ Grass ┆ Victreebel ┆ Exeggutor │
│ Water ┆ Starmie ┆ GyaradosMega Gyarados │
│ Water ┆ Tentacruel ┆ Kingler │
│ Water ┆ Poliwag ┆ Gyarados │
│ Fire ┆ Rapidash ┆ CharizardMega Charizard X │
│ Fire ┆ Charizard ┆ Flareon │
│ Fire ┆ CharizardMega Charizard X ┆ Arcanine │
└────────┴───────────────────────────┴───────────────────────────┘
從「"Type 1"」來看是每三行為一組,我們可以巧妙使用ti.is_every_nth_row()將每組的第一行設為「"lightblue"」顏色,其它行則設為「"papayawhip"」顏色:
row_expr = ti.is_every_nth_row(3)
(
GT(pokemon)
.tab_style(
style=style.fill("lightblue"), locations=loc.body(rows=row_expr)
)
.tab_style(
style=style.fill("papayawhip"), locations=loc.body(rows=~row_expr)
)
.opt_stylize(style=3, color="pink")
)
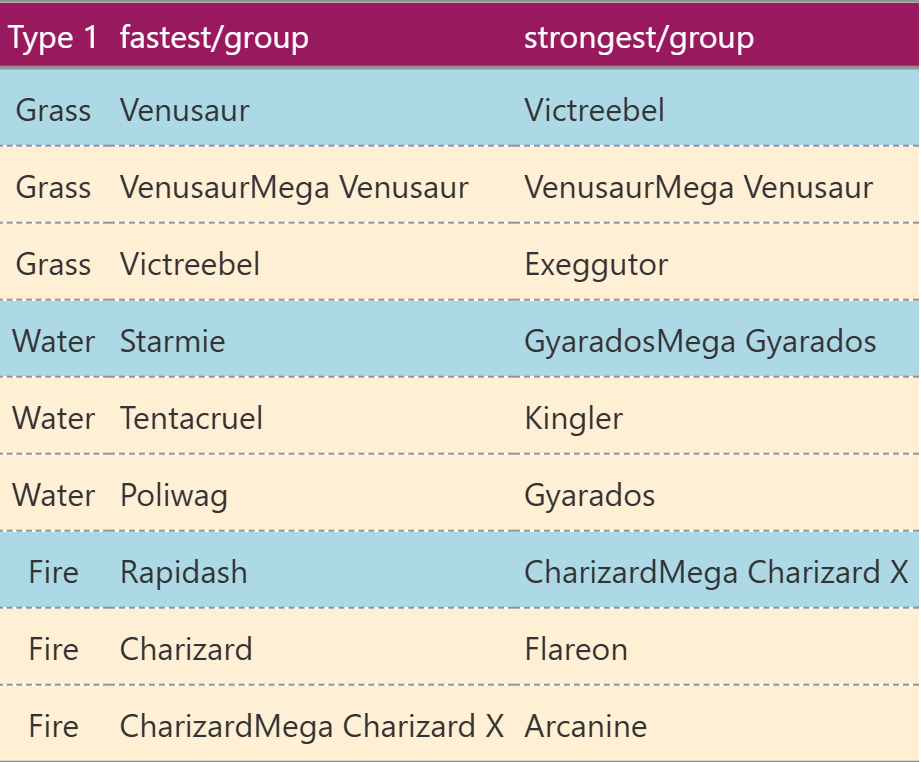
請留意,此處使用了~符號來反轉ti.is_every_nth_row()的布林結果。
針對更為複雜的選擇情況,可以串接多個ti.is_every_nth_row()來達成,屬於進階用法,有興趣的朋友可以自行參考範例.
個人部落格文章:Turtle Island: A Utility Kit for Polars Expressions。

