
大型語言模型(LLM)核心是Transformer架構,理解Transformer架構如何運作,是理解LLM關鍵
Embedding層:將輸入的文字轉換成電腦可以理解向量表示 (Word Embedding)Encoder(編碼器):負責理解輸入序列的語義Decoder(解碼器):負責生成目標序列Self-Attention 機制(自注意力機制):讓模型關注輸入序列中不同位置的詞語之間的關係Multi-Head Attention(多頭注意力):使用多個注意力機制,讓模型可以關注不同方面的關係Feed-Forward Network(前饋神經網路):對每個詞語的向量表示進行非線性轉換Normalization(正規化):幫助模型更快更好地收斂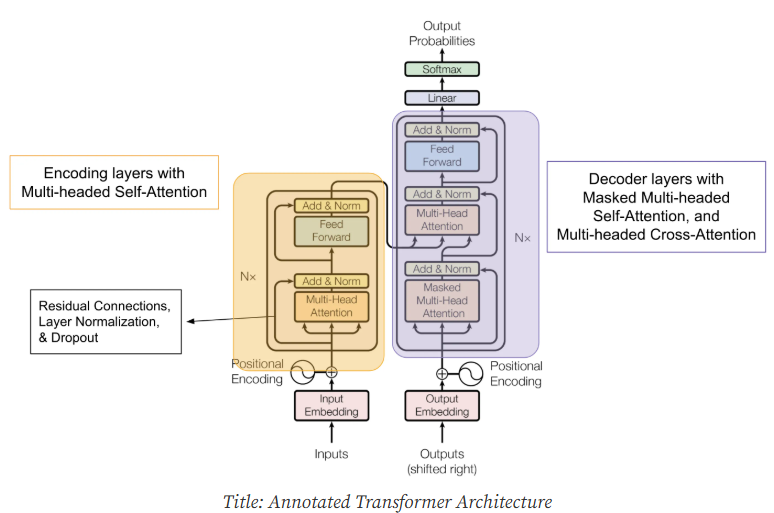
圖片來源:https://aiml.com/explain-the-transformer-architecture/
是
Transformer架構核心,它允許模型在處理一個詞語時,考慮到序列中所有其他詞語的影響
Query (Q)、Key (K)、Value (V):輸入序列中每個詞語,模型會計算出三個向量Query、Key、Value計算注意力分數:每個Query模型會與所有Key計算相似度(通常使用點積),得到注意力分數加權求和:將注意力分數應用到Value上,得到每個詞語加權表示是Self-Attention擴展,它使用多個獨立的注意力機制(不同Query、Key、Value矩陣),讓模型可以關注輸入序列中不同方面的關係,將多個頭的輸出合併。
Encoder:負責處理輸入序列,將轉換成一個包含語義信息的向量表示。通常由多個相同的層堆疊而成,每一層包含 Multi-Head Attention 和 Feed-Forward Network
Decoder:負責生成目標序列,由多個相同層堆疊而成,每一層包含 Masked Multi-Head Attention(防止模型在生成時看到未來的詞語)、Encoder-Decoder Attention(讓 Decoder 關注 Encoder 輸出)和 Feed-Forward Network
import tensorflow as tf
from tensorflow.keras.layers import Layer, Dense, Embedding
class SelfAttention(Layer):
def __init__(self, embed_dim, num_heads=8):
super(SelfAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
if embed_dim % num_heads != 0:
raise ValueError(
f"embedding dimension = {embed_dim} should be divisible by number of heads = {num_heads}"
)
self.projection_dim = embed_dim // num_heads
self.query_dense = Dense(embed_dim)
self.key_dense = Dense(embed_dim)
self.value_dense = Dense(embed_dim)
self.combine_heads = Dense(embed_dim)
def attention(self, query, key, value):
score = tf.matmul(query, key, transpose_b=True)
dim_key = tf.cast(tf.shape(key)[-1], tf.float32)
scaled_score = score / tf.math.sqrt(dim_key)
weights = tf.nn.softmax(scaled_score, axis=-1)
output = tf.matmul(weights, value)
return output
def separate_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.projection_dim))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, inputs):
batch_size = tf.shape(inputs)[0]
query = self.query_dense(inputs)
key = self.key_dense(inputs)
value = self.value_dense(inputs)
query = self.separate_heads(query, batch_size)
key = self.separate_heads(key, batch_size)
value = self.separate_heads(value, batch_size)
attention = self.attention(query, key, value)
attention = tf.transpose(attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(attention, (batch_size, -1, self.embed_dim))
output = self.combine_heads(concat_attention)
return output
# 簡單Transformer Encoder層
class TransformerBlock(Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = SelfAttention(embed_dim, num_heads)
self.ffn = tf.keras.Sequential(
[Dense(ff_dim, activation="relu"), Dense(embed_dim),]
)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
# 簡單Transformer 模型
class TransformerModel(tf.keras.Model):
def __init__(self, num_layers, embed_dim, num_heads, ff_dim, vocab_size, maxlen, rate=0.1):
super(TransformerModel, self).__init__()
self.embedding = Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_embedding = Embedding(input_dim=maxlen, output_dim=embed_dim)
self.transformer_blocks = [
TransformerBlock(embed_dim, num_heads, ff_dim, rate) for _ in range(num_layers)
]
self.dense = Dense(vocab_size)
def call(self, inputs, training):
x = self.embedding(inputs)
positions = tf.range(start=0, limit=tf.shape(inputs)[1], delta=1)
x = x + self.pos_embedding(positions)
for block in self.transformer_blocks:
x = block(x, training)
x = self.dense(x)
return x
# 範例使用
vocab_size = 10000
maxlen = 100
embed_dim = 32
num_heads = 2
ff_dim = 32
num_layers = 2
model = TransformerModel(num_layers, embed_dim, num_heads, ff_dim, vocab_size, maxlen)
inputs = tf.random.uniform((1, maxlen), minval=0, maxval=vocab_size, dtype=tf.int32)
output = model(inputs, training=False)
print(output.shape)

