為了訓練動畫推薦系統,我們需要可靠的資料來源。本專案選擇使用 Kaggle 上的 Anime Recommendation Database 當作參考,其中包含:
anime.csv:動畫清單(ID、標題、類型、描述…)rating.csv:使用者對動畫的評分紀錄詳細的資料介紹可以參考Kaggle內容。
類似的資料集介紹合併資料初探歡迎參考我同伴的系列文章:
動漫宅的 30 天 AWS Lakehouse 修行日誌 - DAY2 知識之章-理解資料本源
今天的目標是:
workspace/data/ 目錄。kaggle.json 放到專案裡,確保安全性。登入 Kaggle。
點選右上角頭像 → Setting。
下滑在 API 區塊點選 Create New Token。
kaggle.json,裡面有 username 與 key。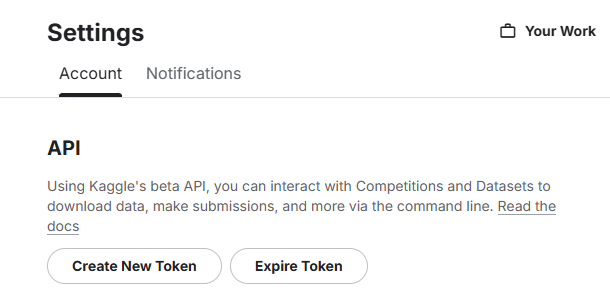
.env 管理金鑰(避免上傳到 GitHub)在專案根目錄建立 .env(與 docker-compose.yml 同層):
KAGGLE_USERNAME=你的_kaggle帳號
KAGGLE_KEY=你的API金鑰
並且把 .env 加進 .gitignore:
# .gitignore
.env
kaggle.json
.kaggle/
__pycache__/
mlruns/
(建議另外放一份 .env.example,方便團隊成員知道需要哪些變數。)
以上的新增讓你可以把機密資料只存在本機環境變數裡面讓Kaggle API直接索引,且不會傳到git上。
requirements-dev.txt在最後加上 Kaggle 套件(版本固定避免不相容):
kaggle==1.6.14
requests==2.31.0
docker-compose.yml確保 python-dev 服務有帶入環境變數:
python-dev:
build:
context: .
dockerfile: docker/Dockerfile.dev
container_name: python-dev
environment:
- KAGGLE_USERNAME=${KAGGLE_USERNAME}
- KAGGLE_KEY=${KAGGLE_KEY}
volumes:
- ./workspace:/workspace
working_dir: /workspace
建立一個新的 Notebook:
/workspace/notebooks/Day3_Download_Data.ipynb
在裡面撰寫:
import os
import kaggle
# 指定資料存放路徑
DATA_DIR = "/usr/mlflow/data"
os.makedirs(DATA_DIR, exist_ok=True)
# Kaggle 資料集名稱
dataset = "CooperUnion/anime-recommendations-database"
# 下載並解壓縮
kaggle.api.dataset_download_files(dataset, path=DATA_DIR, unzip=True)
print("✅ 動畫資料下載完成!存放於:", DATA_DIR)
在 Notebook 裡新增一格:
import pandas as pd
animes = pd.read_csv(f"{DATA_DIR}/anime.csv")
ratings = pd.read_csv(f"{DATA_DIR}/rating.csv")
print("動畫數量:", len(animes))
print("評分數量:", len(ratings))
animes.head(3)
這樣就能在 Notebook 內直接看到資料表格。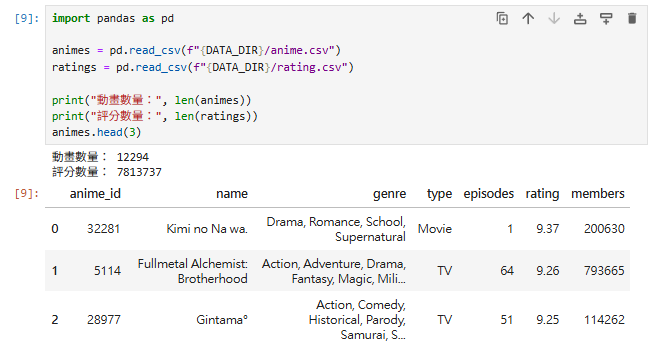
流程圖
[.env 檔 → docker-compose → 容器環境變數]
↓
[Kaggle API 認證]
↓
[Notebook: Day3_Download_Data.ipynb]
↓
[下載 dataset → /workspace/data/]
重點總結
✅ Kaggle API 金鑰用 .env 管理,不會洩漏到 GitHub。
✅ 資料下載流程移到 Notebook,方便即時檢查與探索。
✅ 所有資料集中存放於 /workspace/data/,後續分析統一存取。
延伸思考 & 預告
明天(Day 4):我們會進行 自動化 EDA 與資料清理,用 ydata-profiling 產生互動式報告,並處理缺失值與異常資料,讓資料更乾淨。


 iThome鐵人賽
iThome鐵人賽