昨天(Day 3),我們已經成功從 Kaggle 抓下 Anime Recommendations Database 的兩個主要檔案:
anime.csv:動畫資訊(名稱、類型、描述等)rating.csv:使用者對動畫的評分今天的任務是:
我們會使用 ydata-profiling(前身 pandas-profiling)自動產生 EDA 報告,並把處理後的資料存回 data/ 目錄。這些乾淨資料將成為後續訓練推薦系統的基礎。
我們會在 notebooks/day4_eda_cleaning.ipynb 中操作。
import os
import pandas as pd
from ydata_profiling import ProfileReport
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime.csv"))
ratings = pd.read_csv(os.path.join(DATA_DIR, "rating.csv"))
print(anime.head())
print(ratings.head())
用 ydata-profiling 產生一份互動式 HTML 報告。
# Anime 資料檔 EDA
anime_report = ProfileReport(anime, title="Anime Dataset Report", explorative=True)
anime_report.to_file(os.path.join(DATA_DIR, "anime_eda_report.html"))
# Ratings 資料檔 EDA
ratings_report = ProfileReport(ratings, title="Ratings Dataset Report", explorative=True)
ratings_report.to_file(os.path.join(DATA_DIR, "ratings_eda_report.html"))
這樣會輸出兩份報告,可以直接在瀏覽器中打開:
/usr/mlflow/data/anime_eda_report.html
/usr/mlflow/data/ratings_eda_report.html
在html裡面我們可以初步看到資料的分布與相關性,
以下是我初步的觀察:
rating 平均是6.47,看起來評分會相較於5分高一些,會員們算是友善XD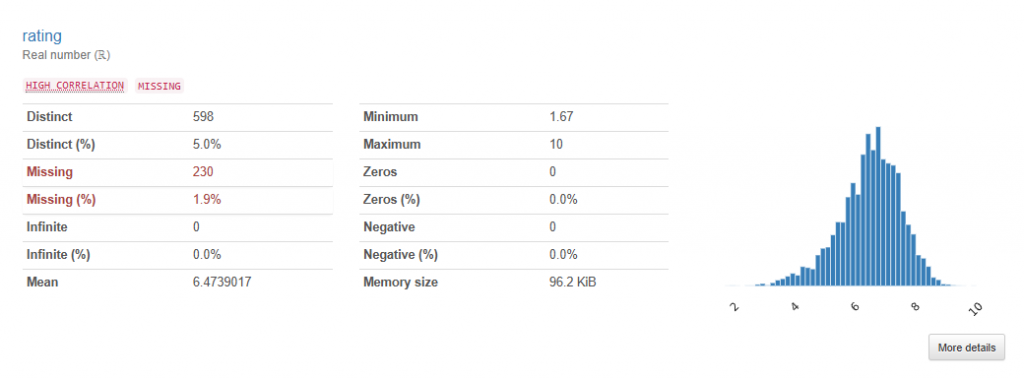
rating跟type沒有線性相關證據,看起來type並不影響動漫在會員心中的好感,是真粉呀!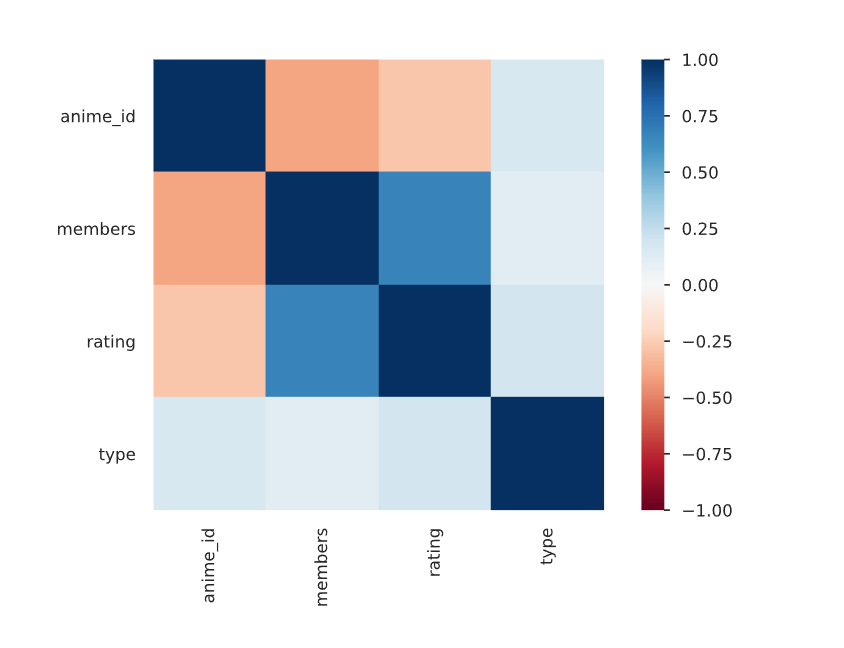
根據報告,anime.csv 與 rating.csv 會有以下問題:
rating.csv 中有部分評分是 -1(代表使用者看過但未評分)。anime.csv 內可能有缺少 genre 或 type 的動畫。我們先做最基本的清理:
-1 評分紀錄。"Unknown"。# 移除無效評分
ratings_clean = ratings[ratings["rating"] != -1]
# 填補缺失值
anime_clean = anime.fillna({
"genre": "Unknown",
"type": "Unknown"
})
# 確認結果
print(ratings.shape, "->", ratings_clean.shape)
print(anime.isnull().sum())
把清理後的資料存成新的檔案,方便後續模型使用。
anime_clean.to_csv(os.path.join(DATA_DIR, "anime_clean.csv"), index=False)
ratings_clean.to_csv(os.path.join(DATA_DIR, "ratings_clean.csv"), index=False)
原始 anime.csv / rating.csv
│
▼
自動化 EDA 報告
│
▼
檢查缺失與異常值
│
▼
清理與補值
│
▼
輸出乾淨 anime_clean.csv / ratings_clean.csv
rating = -1 的無效數據進行過濾,並補齊 anime.csv 的缺失值。anime_clean.csv 與 ratings_clean.csv 將會是 Day 5 建立 Baseline 推薦模型 的基礎。在 Day 5,我們會正式建立 第一個推薦模型(User-based Collaborative Filtering),並用 MLflow 紀錄模型參數與評估指標!


 iThome鐵人賽
iThome鐵人賽