昨天(Day 4),我們完成了資料清理並存成 anime_clean.csv 與 ratings_clean.csv。
今天,我們要建立第一個推薦模型:User-based Collaborative Filtering (使用者協同過濾)。
這是一個 Baseline 模型,不一定效果好,但能當作比較基準。
⚠️ 為了避免計算量過大導致 kernel 掛掉,我們先做一個 快速示範:
將 ratings_clean.csv 拆分為:
ratings_train.csv
ratings_test.csv
ratings_back_up.csv(不使用,保留給後續擴充)本篇只用 15% 的資料,後續讀者可自行更換比例(例如 80/20)。
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import NearestNeighbors
import mlflow
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings = pd.read_csv(os.path.join(DATA_DIR, "ratings_clean.csv"))
# 抽 15% 出來用,剩下 85% 備份
ratings_sample, ratings_back_up = train_test_split(ratings, test_size=0.85, random_state=42)
# 再拆成 10% train + 5% test
ratings_train, ratings_test = train_test_split(ratings_sample, test_size=0.3333, random_state=42)
print("Train:", ratings_train.shape)
print("Test:", ratings_test.shape)
print("Back-up:", ratings_back_up.shape)
ratings_train.to_csv(os.path.join(DATA_DIR, "ratings_train.csv"), index=False)
ratings_test.to_csv(os.path.join(DATA_DIR, "ratings_test.csv"), index=False)
ratings_back_up.to_csv(os.path.join(DATA_DIR, "ratings_back_up.csv"), index=False)
user_item_matrix = ratings_train.pivot_table(
index="user_id",
columns="anime_id",
values="rating"
).fillna(0)
print("User-Item shape:", user_item_matrix.shape)
from scipy.sparse import csr_matrix
# 稀疏矩陣表示
sparse_matrix = csr_matrix(user_item_matrix.values)
# 找 Top-6 鄰居 (包含自己)
knn = NearestNeighbors(metric="cosine", algorithm="brute", n_neighbors=6, n_jobs=-1)
knn.fit(sparse_matrix)
# 先計算所有鄰居,避免每次都重新 kneighbors
distances, indices = knn.kneighbors(sparse_matrix, n_neighbors=6)
user_neighbors = {
user_item_matrix.index[i]: user_item_matrix.index[indices[i][1:]] # 排除自己
for i in range(len(user_item_matrix))
}
def recommend(user_id, top_n=10):
if user_id not in user_neighbors:
return pd.DataFrame(columns=["name", "genre"])
neighbor_ids = user_neighbors[user_id]
neighbor_ratings = user_item_matrix.loc[neighbor_ids]
# 平均分數作為推薦依據
mean_scores = neighbor_ratings.mean().sort_values(ascending=False)
# 排除使用者已看過的動畫
seen = user_item_matrix.loc[user_id]
seen = seen[seen > 0].index
recommendations = mean_scores.drop(seen).head(top_n)
return anime[anime["anime_id"].isin(recommendations.index)][["name", "genre"]]
def precision_recall_at_k(user_id, k=10):
recs = recommend(user_id, top_n=k)
if recs.empty:
return np.nan, np.nan
# 測試集中的喜好動畫
user_test = ratings_test[ratings_test["user_id"] == user_id]
liked = set(user_test[user_test["rating"] > 7]["anime_id"])
if len(liked) == 0:
return np.nan, np.nan
# 命中數
hit = len(set(recs.index) & liked)
precision = hit / k
recall = hit / len(liked)
return precision, recall
# 抽樣部分使用者做評估
sample_users = np.random.choice(user_item_matrix.index, 100, replace=False)
precisions, recalls = [], []
for u in sample_users:
p, r = precision_recall_at_k(u, 10)
if not np.isnan(p):
precisions.append(p)
if not np.isnan(r):
recalls.append(r)
mean_precision = np.mean(precisions)
mean_recall = np.mean(recalls)
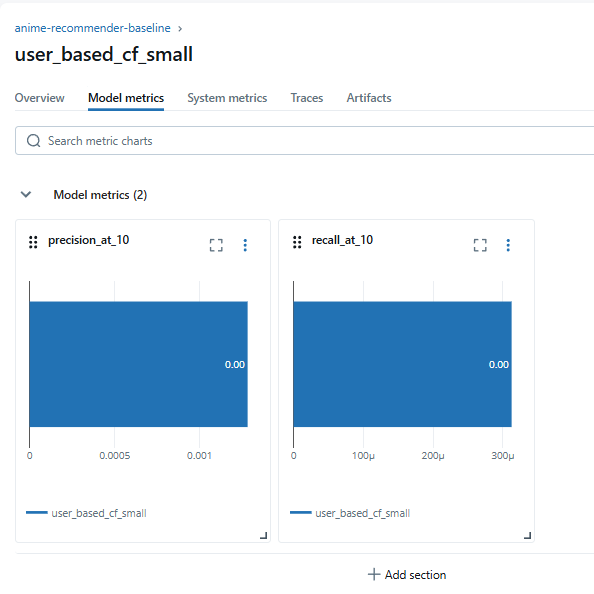
print("Baseline Precision@10:", mean_precision)
print("Baseline Recall@10:", mean_recall)
import os, mlflow
mlflow.set_tracking_uri(os.getenv("MLFLOW_TRACKING_URI", "http://mlflow:5000"))
mlflow.set_experiment("anime-recommender-baseline")
with mlflow.start_run(run_name="user_based_cf_small"):
mlflow.log_param("train_pct", 10)
mlflow.log_param("test_pct", 5)
mlflow.log_param("neighbors", 5)
mlflow.log_param("top_n", 10)
mlflow.log_metric("precision_at_10", mean_precision)
mlflow.log_metric("recall_at_10", mean_recall)
ratings_clean.csv
│
▼
拆分成三份
├─ 10% → ratings_train.csv (建模)
├─ 5% → ratings_test.csv (驗證)
└─ 85% → ratings_back_up.csv (備用)
│
▼
建立 user-item 矩陣 → 找鄰居 (KNN) → 推薦
│
└── Precision@10 / Recall@10 → MLflow log
本篇示範用 10% train + 5% test,其餘 85% 資料備份,避免運算爆掉。
建立 User-based CF baseline,使用 KNN 找鄰居來計算推薦。
評估使用 Precision@10 與 Recall@10:
由於資料高度稀疏,Precision/Recall 可能都偏低,但這正是 baseline 的意義:提供比較基準。
在 Day 6,我們將嘗試 Item-based 模型 (TF-IDF),利用動畫描述文字來計算相似度,並觀察 Precision/Recall 是否能提升。


 iThome鐵人賽
iThome鐵人賽