昨天(Day 5),我們建立了 User-based Collaborative Filtering (協同過濾),並用 Precision@10 與 Recall@10 驗證。
結果顯示:由於資料稀疏與切分比例的限制,baseline 效果偏低。
今天我們要嘗試另一個常見的 baseline:Item-based Collaborative Filtering,這次不用「使用者的相似度」,而是利用 動畫描述文字 建立動畫之間的相似度。
技術重點:
genre 與 type 描述。建議放在 notebooks/day6_item_based.ipynb。
import os
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
import mlflow
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_train = pd.read_csv(os.path.join(DATA_DIR, "ratings_train.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
print("Anime:", anime.shape)
print("Train:", ratings_train.shape)
print("Test:", ratings_test.shape)
我們將 genre 與 type 結合,當作動畫的「文字描述」。
anime["text"] = anime["genre"].fillna("") + " " + anime["type"].fillna("")
anime[["name", "text"]].head()
tfidf = TfidfVectorizer(stop_words="english")
tfidf_matrix = tfidf.fit_transform(anime["text"])
print("TF-IDF shape:", tfidf_matrix.shape)
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
print("Cosine matrix shape:", cosine_sim.shape)
根據使用者在 train 裡評分過的動畫,找出最相似的動畫推薦。
indices = pd.Series(anime.index, index=anime["anime_id"]).drop_duplicates()
def recommend_item_based(user_id, top_n=10):
# 找出 user 在 train 裡喜歡的動畫
user_ratings = ratings_train[ratings_train["user_id"] == user_id]
liked = user_ratings[user_ratings["rating"] > 7]["anime_id"].tolist()
if len(liked) == 0:
return pd.DataFrame(columns=["name", "genre"])
sim_scores = np.zeros(cosine_sim.shape[0])
for anime_id in liked:
if anime_id in indices:
idx = indices[anime_id]
sim_scores += cosine_sim[idx]
sim_scores = sim_scores / len(liked)
sim_indices = sim_scores.argsort()[::-1]
# 排除已看過的動畫
seen = set(user_ratings["anime_id"])
rec_ids = [anime.loc[i, "anime_id"] for i in sim_indices if anime.loc[i, "anime_id"] not in seen]
rec_ids = rec_ids[:top_n]
return anime[anime["anime_id"].isin(rec_ids)][["name", "genre"]]
與 Day 5 相同的評估方式,但改用 item-based 推薦函數。
def precision_recall_at_k_item(user_id, k=10):
recs = recommend_item_based(user_id, top_n=k)
if recs.empty:
return np.nan, np.nan
user_test = ratings_test[ratings_test["user_id"] == user_id]
liked = set(user_test[user_test["rating"] > 7]["anime_id"])
if len(liked) == 0:
return np.nan, np.nan
hit = len(set(recs.index) & liked)
precision = hit / k
recall = hit / len(liked)
return precision, recall
# 抽樣部分使用者
sample_users = np.random.choice(ratings_train["user_id"].unique(), 100, replace=False)
precisions, recalls = [], []
for u in sample_users:
p, r = precision_recall_at_k_item(u, 10)
if not np.isnan(p):
precisions.append(p)
if not np.isnan(r):
recalls.append(r)
mean_precision = np.mean(precisions)
mean_recall = np.mean(recalls)
print("Item-based Precision@10:", mean_precision)
print("Item-based Recall@10:", mean_recall)
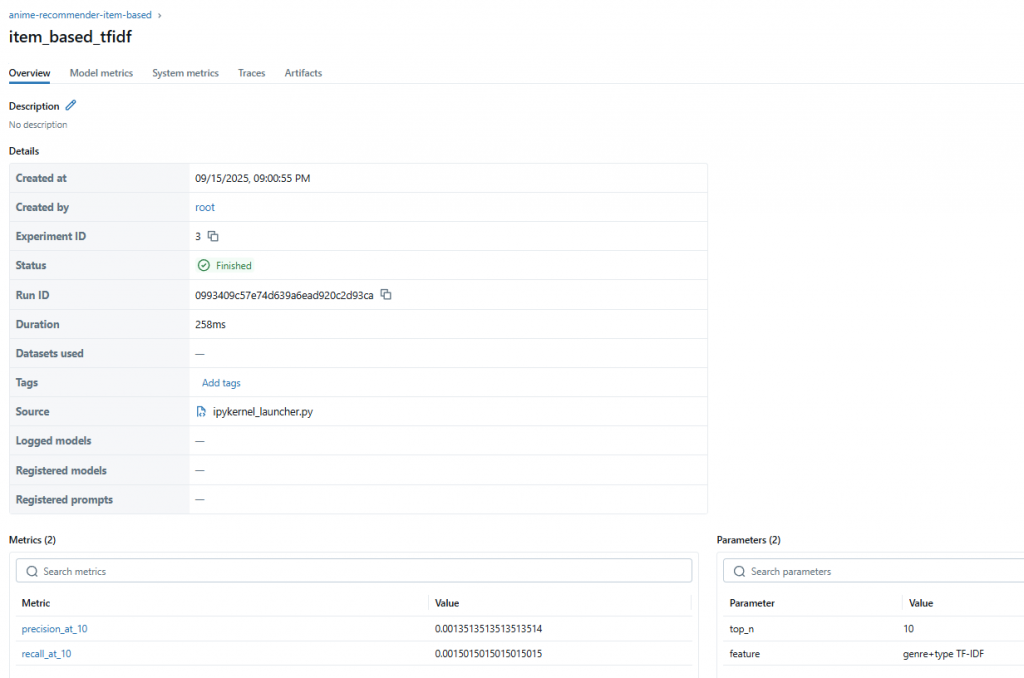
mlflow.set_experiment("anime-recommender-item-based")
with mlflow.start_run(run_name="item_based_tfidf"):
mlflow.log_param("top_n", 10)
mlflow.log_param("feature", "genre+type TF-IDF")
mlflow.log_metric("precision_at_10", mean_precision)
mlflow.log_metric("recall_at_10", mean_recall)
# 隨機挑一個 test user
test_user = ratings_test["user_id"].sample(1, random_state=42).iloc[0]
print("測試使用者 ID:", test_user)
# 該使用者在 test set 裡喜歡的動畫
user_test = ratings_test[(ratings_test["user_id"] == test_user) & (ratings_test["rating"] > 7)]
liked_anime = anime[anime["anime_id"].isin(user_test["anime_id"])][["name", "genre"]]
print("\n🎯 Test set 裡這位使用者喜歡的動畫:")
print(liked_anime.head(10)) # 最多列 10 部
# 模型推薦的動畫
recommended = recommend_item_based(test_user, top_n=10)
print("\n🤖 模型推薦的前 10 部動畫:")
print(recommended)

看起來模型可能有學習到使用者喜歡Action類型的作品,但整體效果非常的差,目前兩個模型都還有非常大的進步空間,但我們後續先使用這兩個模型進行比較與註冊流程,相信未來還有很多機會把模型效能提升,這次的分享先以MLFLOW流程的打通為核心,流程打通了,要執行多次實驗就會很方便。
anime_clean.csv + ratings_train.csv + ratings_test.csv
│
▼
建立文字描述欄位 (genre + type)
│
▼
TF-IDF 向量化 → 動畫相似度矩陣
│
▼
Item-based 推薦函數
│
└── Precision@10 / Recall@10 (test set) → MLflow log
genre + type 作為文字描述,透過 TF-IDF + Cosine Similarity 建立相似度矩陣。在 Day 7,我們將把推薦結果(例如:Top-10 清單、範例輸入/輸出)存成 MLflow artifacts,讓之後的 API 與 UI 可以直接使用模型輸出。


 iThome鐵人賽
iThome鐵人賽