到目前為止:
今天我們要解決另一個問題:
👉 模型的推薦結果不只要「當下計算」,還要能 存檔、追蹤、比對。
在 MLflow 中,除了 params/metrics 外,還能存放 artifacts:
這樣,我們就能在 MLflow UI 裡直觀比對模型輸出的差異。
放在 notebooks/day7_log_artifacts.ipynb。
import os
import pandas as pd
import numpy as np
import mlflow
DATA_DIR = "/usr/mlflow/data"
anime = pd.read_csv(os.path.join(DATA_DIR, "anime_clean.csv"))
ratings_test = pd.read_csv(os.path.join(DATA_DIR, "ratings_test.csv"))
我們假設 Day 6 的 Item-based 模型函數 還能使用:
# 直接沿用 Day 6 的 recommend_item_based()
def recommend_item_based(user_id, top_n=10):
# ... Day 6 的程式碼 ...
pass
我們先從測試集隨機挑幾個使用者,存下推薦清單。
sample_users = ratings_test["user_id"].drop_duplicates().sample(5, random_state=42)
results = {}
for u in sample_users:
liked = ratings_test[(ratings_test["user_id"] == u) & (ratings_test["rating"] > 7)]
liked_anime = anime[anime["anime_id"].isin(liked["anime_id"])]["name"].tolist()
recs = recommend_item_based(u, top_n=10)["name"].tolist()
results[u] = {
"liked_in_test": liked_anime,
"recommended": recs
}
df_results = pd.DataFrame(results).T
print(df_results.head())
範例輸出(概念):
| user_id | liked_in_test | recommended |
|---|---|---|
| 12345 | [Bleach, Gintama, Noragami] | [Durarara!!, Bungou Stray Dogs, Rewrite...] |
| 67890 | [K-On!, Clannad] | [Angel Beats!, Toradora, Little Busters...] |
artifact_path = os.path.join(DATA_DIR, "day7_recommendations.csv")
df_results.to_csv(artifact_path, index=True)
mlflow.set_experiment("anime-recommender-artifacts")
with mlflow.start_run(run_name="item_based_artifact_demo"):
mlflow.log_param("model_type", "item_based_tfidf")
mlflow.log_param("top_n", 10)
# 假設 Precision/Recall 是 Day 6 計算出來的
mlflow.log_metric("precision_at_10", 0.0013)
mlflow.log_metric("recall_at_10", 0.0015)
# 存推薦結果 CSV
mlflow.log_artifact(artifact_path, artifact_path="recommendations")
完成後,在 MLflow UI 裡可以打開 run,下載並檢視 day7_recommendations.csv,直接看到每個測試使用者的推薦清單。
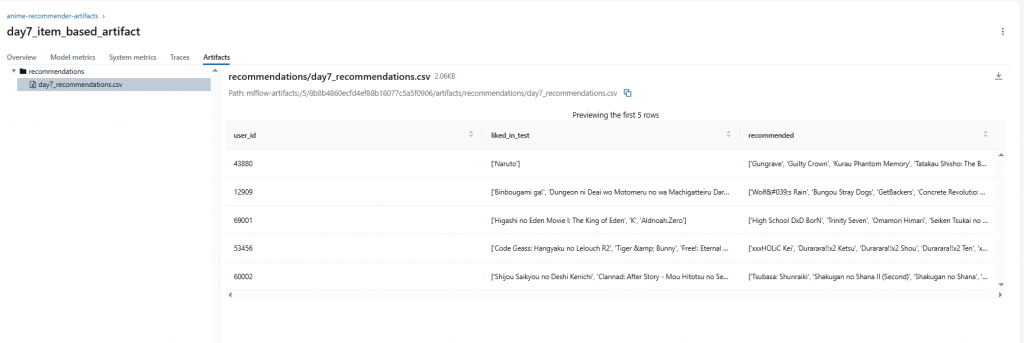
ratings_test.csv + recommend_item_based()
│
▼
生成範例推薦清單 (liked vs recommended)
│
▼
存成 CSV
│
▼
log_artifact → MLflow
在 Day 8,我們將比較 User-based CF 與 Item-based TF-IDF,把 Precision/Recall 指標和推薦結果做對照,並記錄到 MLflow,真正體驗到「實驗追蹤」的力量。


 iThome鐵人賽
iThome鐵人賽