《DAY 16》
生成式 AI 的安全挑戰:對抗性攻擊、模型中毒與 Deepfake ⚠️
⚡ 快速掌握本文精華
- 對抗性攻擊 (Adversarial Attack):微小擾動 → 造成 AI 誤判
- 模型中毒 (Model Poisoning):惡意數據 → 污染模型 → 輸出偏差
- Deepfake 假資訊:真假難辨 → 衝擊社會信任
- 核心價值:AI 安全 = 技術防護 + 法規監管 + 使用者媒體素養
生成式 AI 與機器學習在帶來便利的同時,也可能被惡意利用。
今天我們聚焦三大 AI 安全挑戰:
📸 插圖:
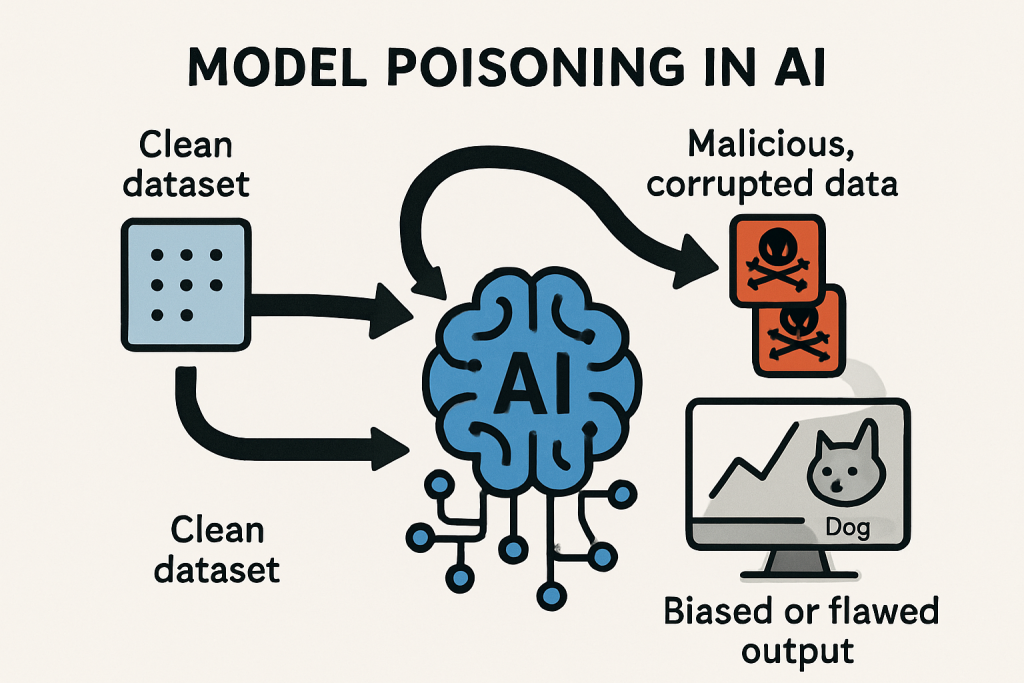
圖 1:模型中毒(Model Poisoning)示意圖
AI 模型可能被設計好的「對抗樣本」欺騙。
🔧 案例:交通標誌誤判
📸 插圖:
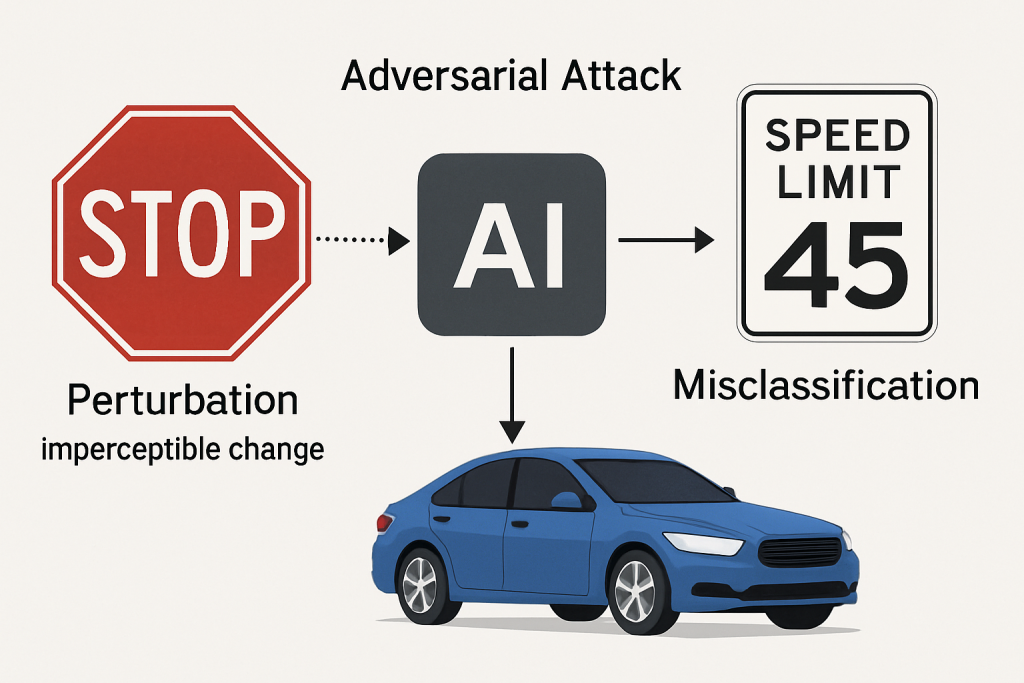
圖 2:對抗性攻擊示意圖
如果惡意數據被混入訓練集 → 模型就會學壞。
🔧 案例:假評論數據
參考上方 圖 1(模型中毒示意圖)——此機制會使模型學到錯誤分佈,導致整體輸出偏差。
生成式 AI 可製作超逼真的影像與語音 → 假新聞、詐騙、政治操弄風險升高。
🔧 案例:Deepfake 影片
📸 插圖:

圖 3:Deepfake 假資訊與真實影像對比
唯有多方合作,才能讓 AI 既安全又可靠。
#AI安全 #對抗性攻擊 #模型中毒 #Deepfake #AI風險 #AI治理 #生成式AI

