▋前言
為了達成前一篇(Day 3)提到的目標,我們設計了一個整合式架構,包含四大核心模組,每一個模組都解決了一個關鍵問題。
▋內容
系統由以下模組組成:
語音識別 (Speech-to-Text, STT)
使用 Whisper 提升逐字稿準確率。
語者分離 (Speaker Diarization)
採用 NeMo 框架解決「誰在說話」的問題,將多人對話切分。
語者識別 (Speaker Recognition, SR)
結合 pyannote (X-vector base) 確認發言者身份,區分老師與學生。
語音情緒辨識 (Speech Emotion Recognition, SER)
由 Speechbrain 搭配 wav2vec 模型來判斷學生情緒狀態,提供互動氛圍分析。
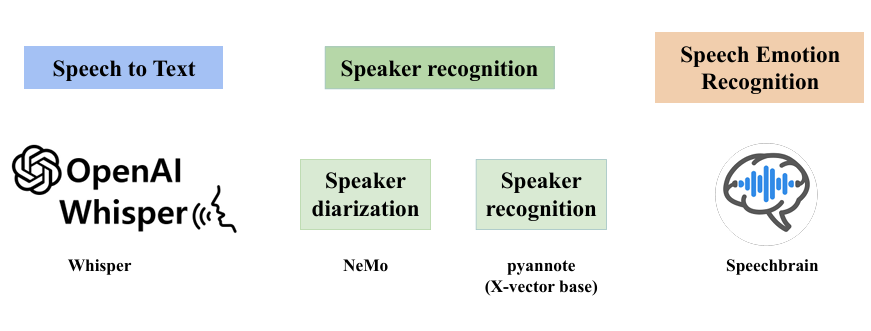
這四大模組透過 Pipeline 串接,形成一個完整的系統,從原始錄音到結構化數據,一條龍處理。
▋下回預告
下一篇將深入介紹第一個模組:語音轉文字 (STT)。
▋參考資料
Whisper 語音模型
NVIDIA NeMo
圖片源自競賽成果簡報

