i> 安裝 PyTorch!pip install transformers datasets torch
ii> 匯入 pipelinefrom transformers import pipeline
iii> 建立情感分析器classifier = pipeline("sentiment-analysis")
** sentiment-analysis 是情感分析器
iv> 測試單句result = classifier("I love learning LLMs with Hugging Face!") print(result)
v> 測試多句texts = [ "I love this movie!", "This is the worst day of my life." ] results = classifier(texts) for t, r in zip(texts, results): print(t, "->", r)
#中文情感分析
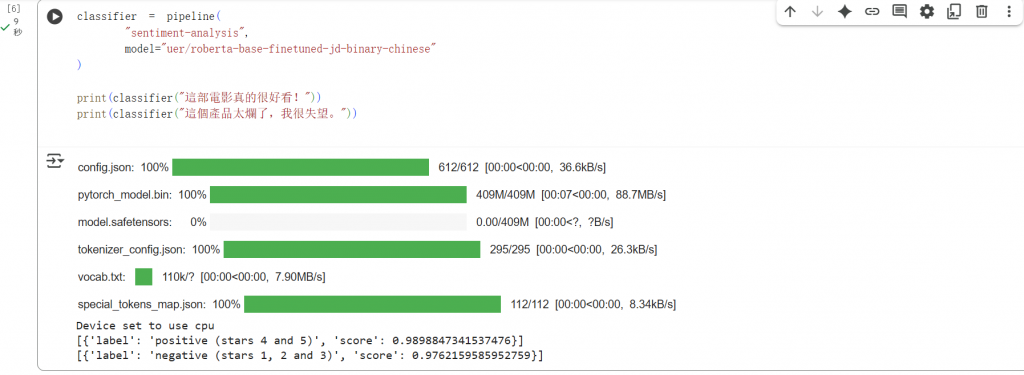
classifier = pipeline(
"sentiment-analysis",
model="uer/roberta-base-finetuned-jd-binary-chinese"
)
print(classifier("這部電影真的很好看!"))
print(classifier("這個產品太爛了,我很失望。"))


 iThome鐵人賽
iThome鐵人賽