流程 :
實作 :
!pip install -q sentence-transformers
import os
import json
import pandas as pd
import numpy as np
from sentence_transformers import SentenceTransformer
from difflib import SequenceMatcher
from typing import List, Dict
# -----------------------------
# 參數
# -----------------------------
EMBED_MODEL = "paraphrase-multilingual-MiniLM-L12-v2"
EMB_PATH = "faq_question_embeddings.npy"
FAQ_CSV = "faqs.csv"
RESULT_CSV = "day27_test_results.csv"
MANUAL_CSV = "day27_test_for_manual.csv"
K_LIST = [1,3,5]
FUZZY_THRESHOLD = 0.60
# 1) 載入 FAQ
df = pd.read_csv(FAQ_CSV, encoding="utf-8-sig")
print("Loaded FAQ count:", len(df))
# 2) 準備 20 筆中文測試 query(每題對應到正確的 FAQ id)
test_queries = [
{"query":"我要退貨要怎麼做?", "expected_id":"q1"},
{"query":"如何申請退貨?需要準備什麼?", "expected_id":"q1"},
{"query":"運費要怎麼計算?", "expected_id":"q2"},
{"query":"滿多少可以免運?", "expected_id":"q2"},
{"query":"可以更改收件地址嗎?", "expected_id":"q3"},
{"query":"訂單還沒出貨能改地址嗎?", "expected_id":"q3"},
{"query":"我可以用什麼付款方式?", "expected_id":"q4"},
{"query":"有支援 LINE Pay 嗎?", "expected_id":"q4"},
{"query":"商品多久會到?", "expected_id":"q5"},
{"query":"偏遠地區大約幾天到貨?", "expected_id":"q5"},
{"query":"我要查訂單狀態怎麼查?", "expected_id":"q6"},
{"query":"去哪裡看我的訂單?", "expected_id":"q6"},
{"query":"發票會寄到哪裡?", "expected_id":"q7"},
{"query":"電子發票會寄 Email 嗎?", "expected_id":"q7"},
{"query":"商品有瑕疵我該怎麼辦?", "expected_id":"q8"},
{"query":"東西壞掉要怎麼退換?", "expected_id":"q8"},
{"query":"客服電話是多少?", "expected_id":"q9"},
{"query":"如何聯絡客服?", "expected_id":"q9"},
{"query":"我要如何使用優惠券?", "expected_id":"q10"},
{"query":"結帳時要怎麼輸入折扣碼?", "expected_id":"q10"},
]
df_test = pd.DataFrame(test_queries)
print("測試題數:", len(df_test))
# 3) 載入 embedding 模型
print("載入 embedder:", EMBED_MODEL)
embedder = SentenceTransformer(EMBED_MODEL)
# 使用 question 作為被檢索的文本
texts = df["question"].astype(str).tolist()
# 若有先前儲存的 embeddings 就讀取,否則產生並儲存
if os.path.exists(EMB_PATH):
faq_embeddings = np.load(EMB_PATH)
print("Loaded existing embeddings:", faq_embeddings.shape)
else:
faq_embeddings = embedder.encode(texts, convert_to_numpy=True, show_progress_bar=True).astype("float32")
np.save(EMB_PATH, faq_embeddings)
print("Saved embeddings:", faq_embeddings.shape)
# normalize embeddings for cosine similarity
def normalize(x: np.ndarray):
norms = np.linalg.norm(x, axis=1, keepdims=True)
norms[norms==0] = 1e-9
return x / norms
faq_emb_norm = normalize(faq_embeddings)
# helper: cosine similarity search (pure numpy, suitable for small dataset)
def retrieve_topk(query: str, k: int = 3):
q_emb = embedder.encode([query], convert_to_numpy=True).astype("float32")
q_emb_norm = q_emb / (np.linalg.norm(q_emb) + 1e-9)
sims = (q_emb_norm @ faq_emb_norm.T)[0] # shape (N,)
idxs = np.argsort(-sims) # descending
topk_idxs = idxs[:k]
topk_scores = sims[topk_idxs].tolist()
topk_ids = df.iloc[topk_idxs]["id"].tolist()
topk_questions = df.iloc[topk_idxs]["question"].tolist()
topk_answers = df.iloc[topk_idxs]["answer"].tolist()
return [{"id":tid, "question":tq, "answer":ta, "score":float(sc)} for tid,tq,ta,sc in zip(topk_ids, topk_questions, topk_answers, topk_scores)]
# fuzzy ratio
def fuzzy_ratio(a: str, b: str) -> float:
return SequenceMatcher(None, a, b).ratio()
# 4) 執行測試(取得 top-5 以便之後分析)
rows = []
for i, r in df_test.iterrows():
q = r["query"]
expected_id = r["expected_id"]
expected_answer = df.loc[df["id"]==expected_id, "answer"].values[0]
# retrieve top-5 for safety
retrieved = retrieve_topk(q, k=max(K_LIST))
top1 = retrieved[0] if len(retrieved)>0 else None
topk_ids = [d["id"] for d in retrieved]
topk_answers = [d["answer"] for d in retrieved]
topk_scores = [d["score"] for d in retrieved]
top1_id = top1["id"] if top1 else None
top1_answer = top1["answer"] if top1 else ""
top1_score = top1["score"] if top1 else None
# 自動判斷:top1 是否為 expected_id; expected_id 是否在 top-k
is_top1_correct = (top1_id == expected_id)
is_in_topk = (expected_id in topk_ids)
# 文字相似度(top1 answer 與 expected answer)
fuzzy = fuzzy_ratio(top1_answer, expected_answer)
rows.append({
"query": q,
"expected_id": expected_id,
"expected_answer": expected_answer,
"top1_id": top1_id,
"top1_answer": top1_answer,
"top1_score": top1_score,
"topk_ids": ",".join(topk_ids),
"topk_scores": ",".join([f"{s:.4f}" for s in topk_scores]),
"is_top1_correct": is_top1_correct,
"is_in_topk": is_in_topk,
"fuzzy_score_top1_expected": round(fuzzy, 4)
})
df_results = pd.DataFrame(rows)
# 5) 計算不同 k 的 summary(accuracy@1, recall@k)
summary_rows = []
for k in K_LIST:
# accuracy@1 is always same (top1 correct)
acc1 = df_results["is_top1_correct"].mean()
# recall@k: expected_id in top-k
# recompute for k (we stored topk up to max k; check membership)
def in_topk_k(topk_ids_str, expected_id, k=k):
ids = topk_ids_str.split(",")[:k]
return expected_id in ids
df_results[f"is_in_top{1}"] = df_results["is_top1_correct"] # convenience
df_results[f"is_in_top{k}"] = df_results.apply(lambda row: in_topk_k(row["topk_ids"], row["expected_id"], k), axis=1)
recall_k = df_results[f"is_in_top{k}"].mean()
summary_rows.append({"k":k, "accuracy_top1": acc1, "recall_at_k": recall_k})
summary_df = pd.DataFrame(summary_rows)
# 6) 自動化的「包含或模糊」判定(可作為另一種自動正確率)
# 判定規則:若 top1_answer 與 expected_answer substring 或 fuzzy >= FUZZY_THRESHOLD -> 視為 match
def auto_match_text(predicted: str, expected: str, fuzzy_th=FUZZY_THRESHOLD):
if not predicted or not expected:
return False, 0.0, "empty"
if expected in predicted or predicted in expected:
return True, 1.0, "substring"
fr = fuzzy_ratio(predicted, expected)
if fr >= fuzzy_th:
return True, fr, "fuzzy"
return False, fr, "no_match"
df_results[["auto_match_top1","auto_match_score","auto_match_method"]] = df_results.apply(
lambda row: pd.Series(auto_match_text(row["top1_answer"], row["expected_answer"])),
axis=1
)
auto_accuracy = df_results["auto_match_top1"].mean()
# 7) 匯出結果(給人工打分的 CSV)
df_results.to_csv(RESULT_CSV, index=False, encoding="utf-8-sig")
# 匯出給人工打分的檔案(加入 manual_score 欄位,可用 0/1/2)
df_manual = df_results.copy()
df_manual["manual_score"] = "" # 空白欄位,下載後手動填 0/1/2
df_manual.to_csv(MANUAL_CSV, index=False, encoding="utf-8-sig")
print("=== Summary: k vs recall / accuracy ===")
display(summary_df)
print(f"\n自動模糊比對 (threshold={FUZZY_THRESHOLD}): auto_accuracy = {auto_accuracy:.3f}")
print(f"已輸出:{RESULT_CSV}")
print(f"已輸出:{MANUAL_CSV}")
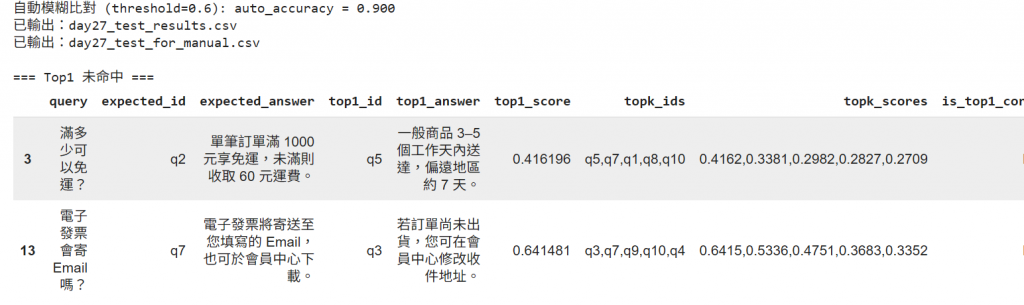
# 顯示錯誤案例(top1 未命中)
print("\n=== Top1 未命中 ===")
mistakes = df_results[df_results["is_top1_correct"]==False]
display(mistakes.head(20))
結果 :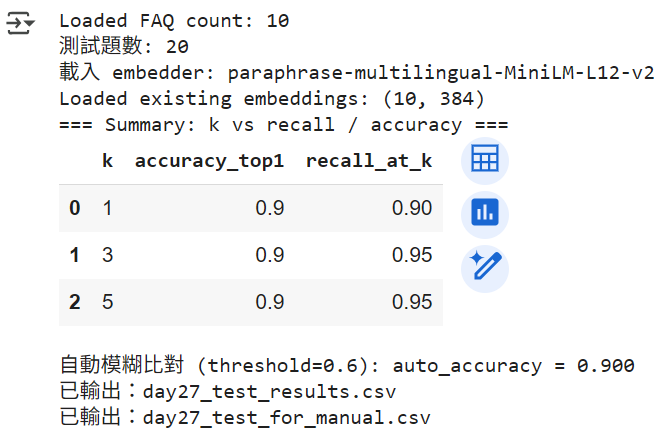


 iThome鐵人賽
iThome鐵人賽