昨天介紹了 single-agent system 與 multi-agent system,今天我們 focus 在 single-agent system 上,透過 2024 這篇論文 Understanding the planning of LLM agents: A survey [1] 來看一下一個 LLM Agent 通常具備哪些抽象的 components,也藉此為參考實作出我們 agent-brain 的 interfaces
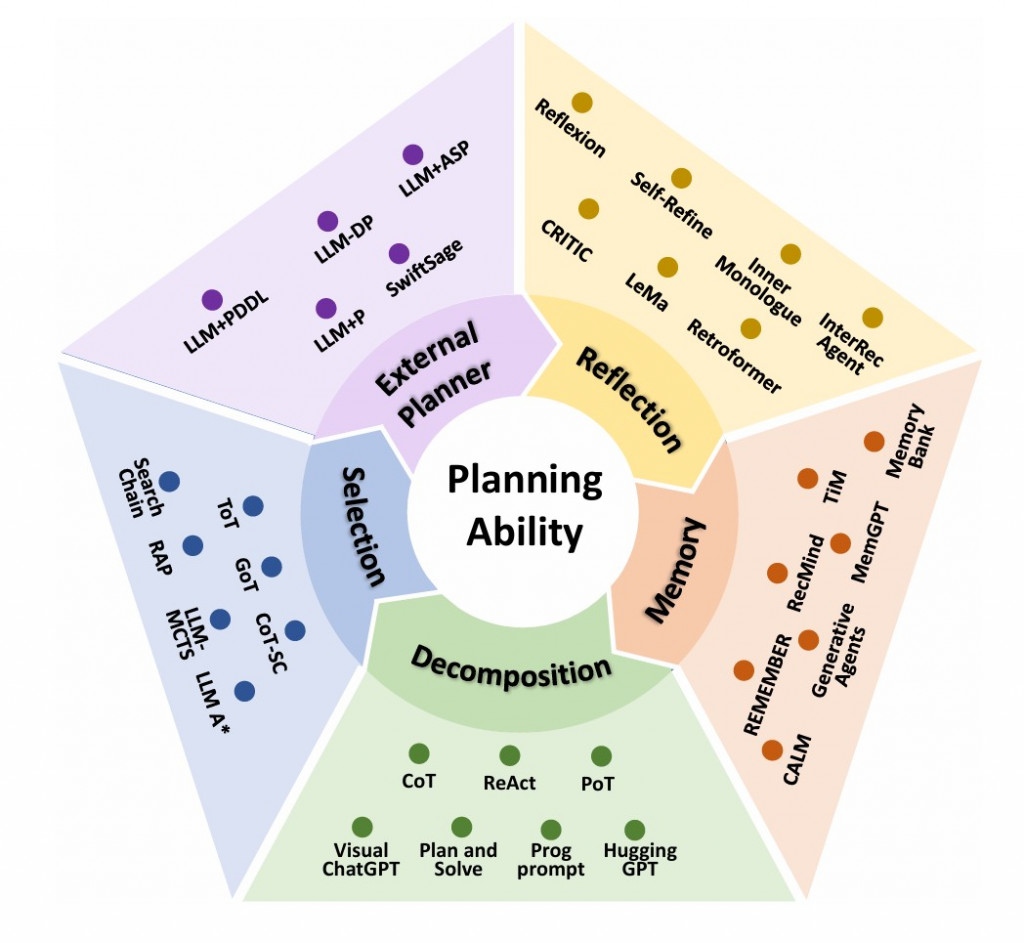
這是論文中區分的 5 大 components,雖然圖上感覺有箭頭環環相扣,但讀完後覺得每個部分不一定有所關連,都算是蠻獨立的課題
論文中區分的五個類別分別是:
那接下來介紹 component
首先當問題進來,簡單的問題還好,但遇到複雜的問題會做的一件事就是拆解問題
想解決什麼?
把複雜任務拆成可執行的子問題/子目標,降低一次性推理的難度,讓 agent 能夠「逐步可控地」前進。核心是把「長路徑推理」變成「一連串局部正確」。
常見作法 / 例子
論文提出了兩種不同的 decomposition 方法
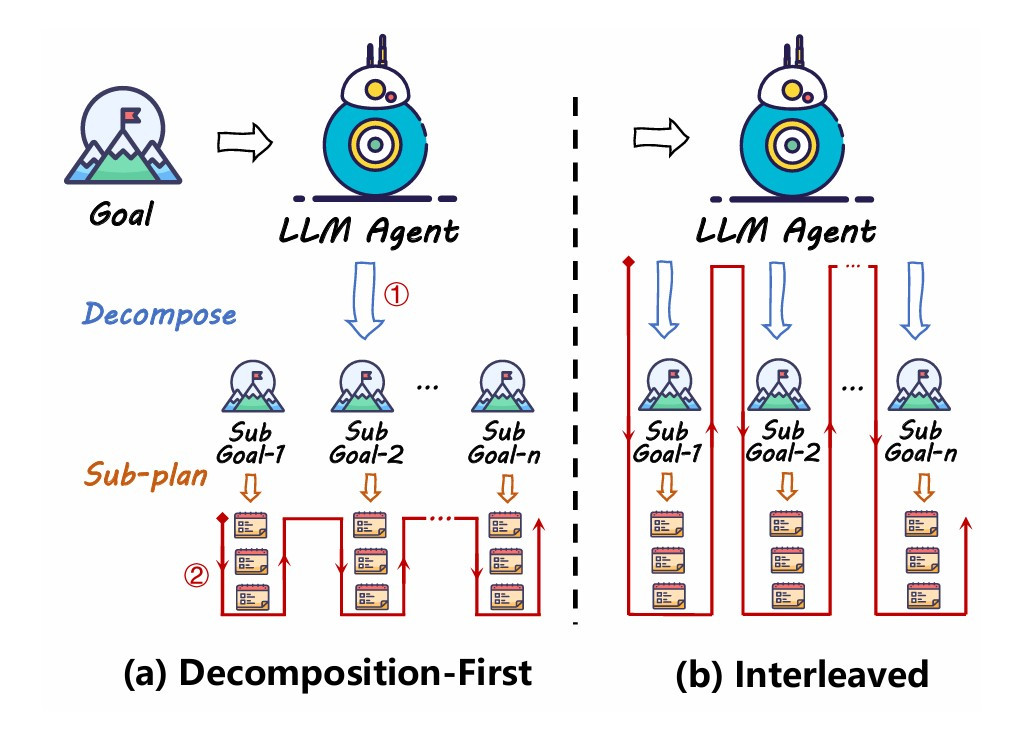
1. Decomposition-First
顧名思義,就是先拆 SubGoal, 如上圖(a),後再對每個 SubGoal 進行規劃與執行 圖(a) 下方紅線。
常見的像是 Plan and solve [2],或者是 HuggingGPT [3]
HuggingGPT 覺得蠻值得介紹的,也完全展現 Decomposition-First 想要做什麼。
就拿 HuggingGPT 介紹一下吧:
我們都知道 Hugging face 上有超多應用在在各種任務上的 model,所以把 GPT 當作是一個 派發任務者 (Controller),breakdown 多個 Sub Task 並且派發適合的任務給不同的 Hugging Face Model 如下圖所示。最後在參考專家的 response 做回答。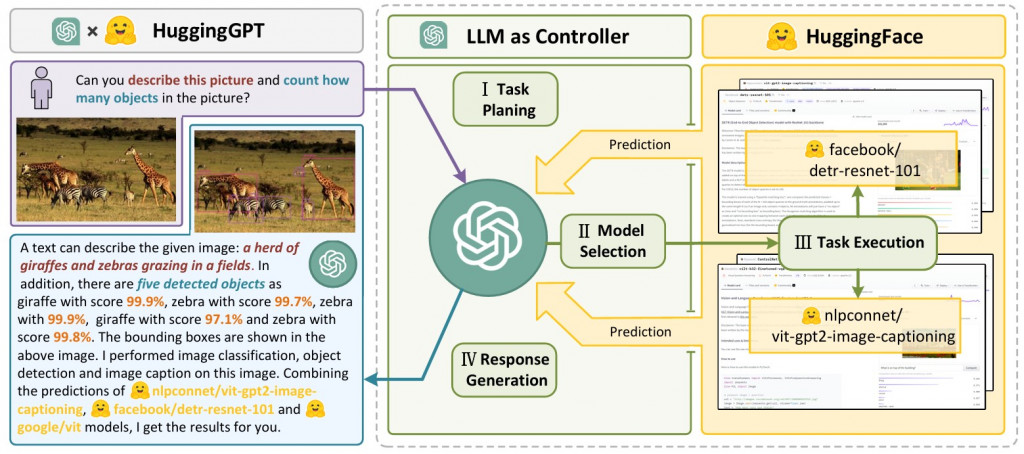
這樣能很好的達到讓專家來處理的效果XD
2. Interleaved Decomposition
接下來是 Interleaved 模式,在這個模式下最大的差別是,相比於同時拆多個 sub tasks,他是依序做事。如圖中(b) 紅線所示,依序完成所有的 sub goal,這樣能更靈活的安排下一個任務。
舉個例子: 我大可以在最一開始就 breakdown 出鐵人賽30天每天要做什麼事情 (Decomposition-First),但其實可能做到第3天就發現這篇 paper 可能要多花(水)一天,所以如果一開始就用 Interleaved 的方法的話,就不會有自打嘴巴的現象了
這部分的例子就有很經典的 ReAct [4]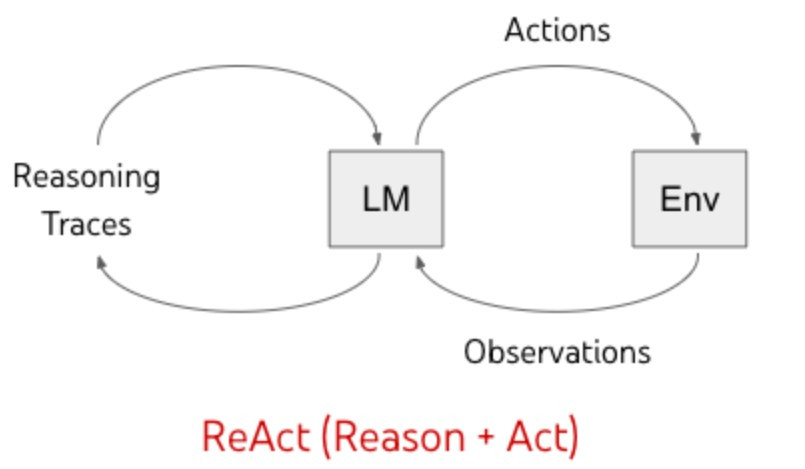
ReAct 由 Reason + Act 組成,這也是他的核心架構
如圖所示,每次都先想一下目前要幹嘛,我要做什麼 Action。是個非常 chill 的方法呢。
常見問題
不難發現,不管是 decomposition-first (BFS) or Interleaved Decomposition (DFS) 的每個 sub goal 之間都有超高的關聯度,這樣當如果在一開始 breakdown 時的方向就錯了或者理解錯誤,Interleaved Decomposition 可能還有機會調整回來,但 decomposition-first 一歪掉可能就沒救了。
*Interleaved Decomposition 在遇到更複雜的任務 (需要多輪) 由於都依序做下去,也很容易被一開始的 sub goal 所影響而救不回來
想解決什麼?
在複雜任務中,LLM 生成的單一路徑常常可能不夠穩健:
Multi-Plan Selection 的核心就是同時生成多個候選方案,然後透過選擇機制找出最可行的一條。相較於單一路徑的 decomposition,這樣能在早期錯誤時透過「多樣性 + 選擇」達到校正與收斂。
常見作法
在 Multi-Plan selection,每種不同的演算法不外乎都分成了兩大階段: Multi-Plan Generation 與 Optimal Plan Selection
目標:盡量多產生多樣化的可行方案。
目標:從候選方案中選出最穩健的一條。
這邊就只挑 最經典的 Self-Consistency 跟 Tree-of-though(?) 來舉例
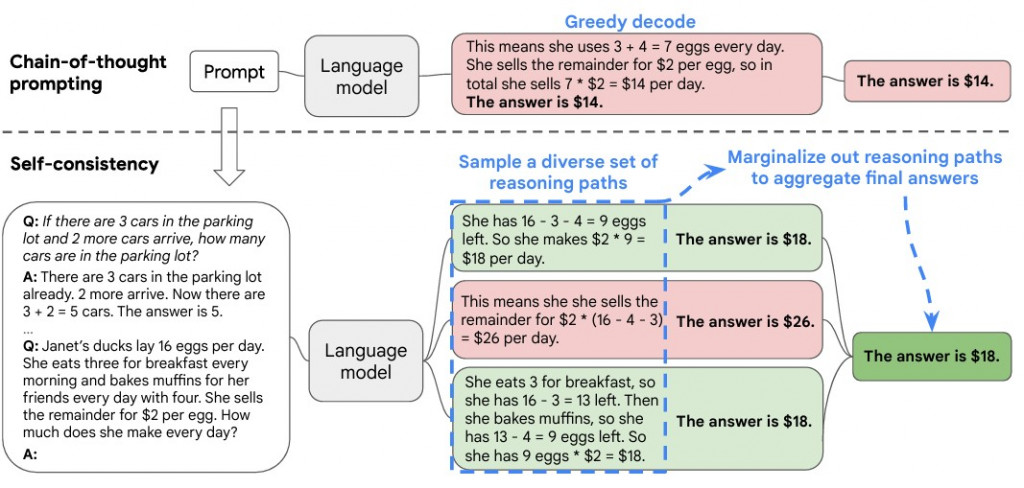
在 Self-Consistency 中,透過一直 sampling 的方法 (e.g., 調高 temperture、改 top-k) 生成多種不同的路徑。途中就是讓他回答 3 次
然後 Optimal Plan Selection 看哪個答案被回答最多次,選擇那個。
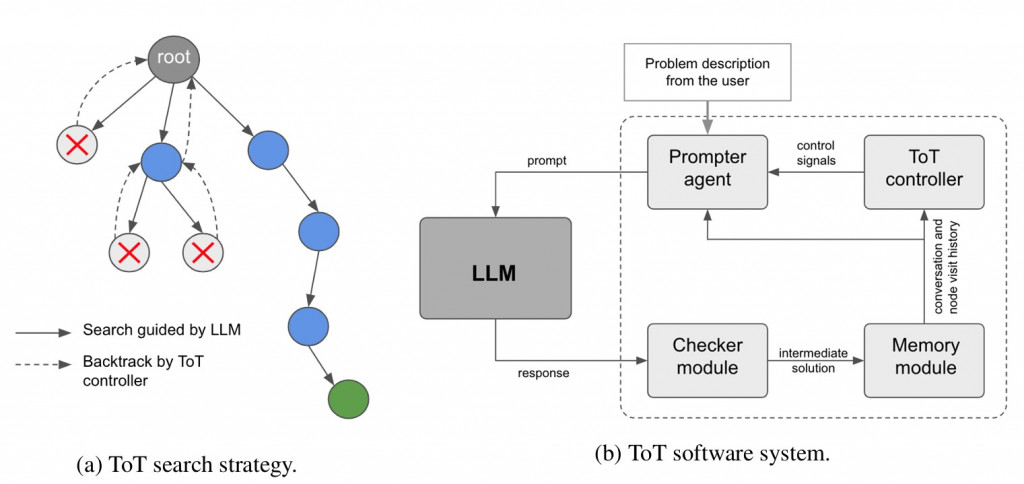
再來看看 Tree of Though search strategy
雖然是個 tree search (有點類似 ReAct 一次一個 SubGoal) 對每個 state (node) 產生可行性解 (Multi-Plan Generation)
然後當執行錯誤時,透過某種 backtracking 機制找到更好的 plan (Optimal Plan Selection),不會接下去做,而是會回到 parent (如上圖右)。
這樣做法又比 self-consistent 更細膩了一點,是真的在 multi-planning + optimal plan selection.
想當然. 要達到這樣就有非常多的 prompt engineering 在裡面啦... 看看他定義的 software system 有多少個 Module ...
然後一摸到 search tree 那就一發不可收拾了,大家有興趣可以參考...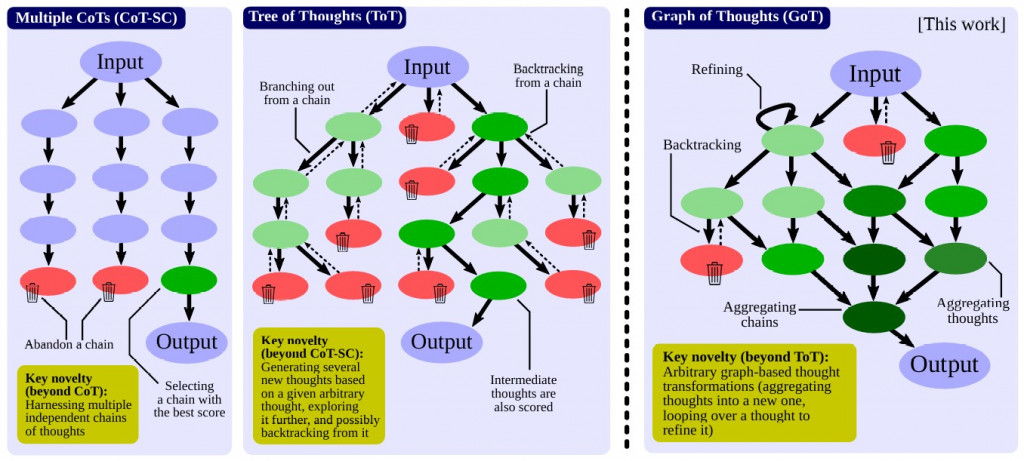
常見問題
感覺得出來,需要超多 tokens for prompt。而且會搞更複雜一些
今天主要 focus 在 Agent 任務拆解的介紹上,介紹了最基本的 decomposition 與 multi-plan selection。
但我自幾覺得沒有絕對的好壞,絕對是根據任務 case by case 來判斷我到底是否用簡單的 breakdown 就夠了。 (總不可能問llm現在幾點 產出 30 個 plan,然後 major voting)
不知不覺也寫了一堆,剩下留到明天再寫好了
ref:
[1] Understanding the planning of LLM agents: A survey
[2] Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
[3] HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
[4] REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS
[5] SELF-CONSISTENCY IMPROVES CHAIN OF THOUGHT REASONING IN LANGUAGE MODELS
[6] Large Language Model Guided Tree-of-Thought

