今天來看論文中的接下來的 components
想解決什麼?
昨天提到的 decomposition 與 multi-Plan Selection 都適合用在相對 general 的環境上,例如 summary / planning / coding 等等
但是 如果當今天是一個已經定義好的環境,像是算數學 / 下圍棋 / 機器人走迷宮的任務,我們勢必不需要讓 LLM 直接輸出什麼公式 或者 棋盤位置啦 之類的。因為有可能生成錯誤 (雖然機率很低)。
這種已經 pre-defined 好的環境,可能都有 最佳演算法 or 透過 reinforcement learning 專門訓練一個 model 來解決,甚至都有自己的評分系統,那 LLM 能從中扮演怎樣的角色呢?
這部分論文提出了兩種 planner: Symbolic Planner / Neural Planner
翻譯成中文就是 符號規劃器,這類方法主要依賴 PDDL [1] (其實這東西存在超久 since 1998) 透過符號推理從初始狀態找到通往目標狀態的最優路徑。
介紹一下 PDDL?
在 PDDL 中,會定義兩大東西

這是一個 problem 的例子,PDDL 將整個任務流程 (上面是要推 ball 到對應的房間),用特定格式表達,並且產生這種 template 後,可以用 (Fast Downward / VAL) 等求解模型,來解決問題。
但可看到,上面這雖然看起來蠻簡單,但是定義起來卻很繁瑣 -> 剛好請 LLM 來幫忙做這件事情。
做完後套用求解模型直接找到最佳解。讚
講到 Neural 就是利用到了神經網絡來解決問題啦 像是:強化學習(RL)、模仿學習(IL)或離線資料訓練一個小參數模型(policy/value/Transformer),在特定域內做到又快又準。
但由於是已經特殊訓練過的緣故,其實如果今天執行看到的 observation 與訓練時看到的非常相像,那其實小參數模型就可以表現得超好的。
但其實很多時候,常常會遇到訓練資料沒有涵蓋的情況,像是開車,你訓練的時候可能不會有人把車停在高速公路上,但真實情況發生了。小參數模型可能就不知道該如何反應。
因此,能透過將 LLM 與小參數模型結合以強化規劃能力。(因為 LLM 有更多的 prior knowledge,他可能不知道怎麼轉彎最快,但她知道開車別撞到東西最重要)
論文中有舉例 Decision Transformer (DT), DT 他是完全的 imitation learning,像這種情況底下就很有可能實際在 inference 時,遇到沒看過的場景。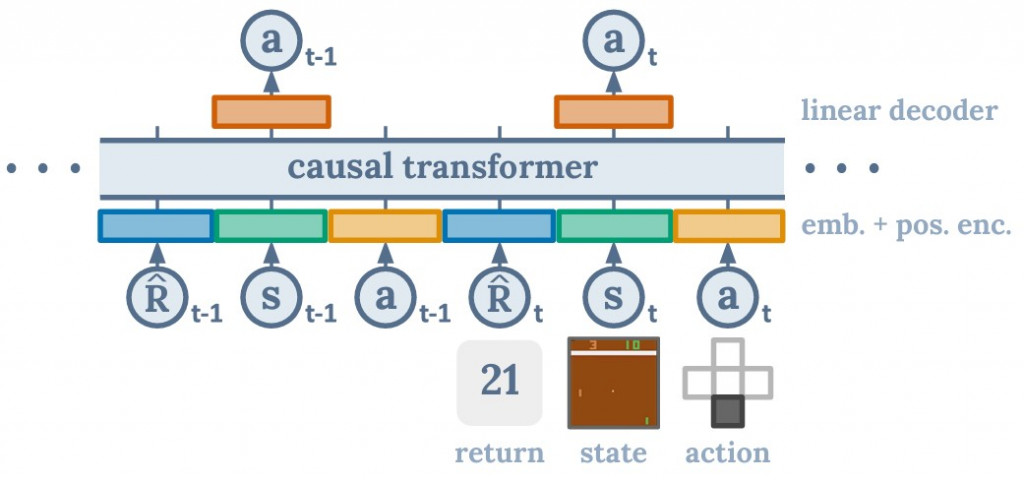 ]
]
後續討論
可以知道 LLM 在這個 component 扮演的比較像是一個輔助的角色。
LLM 在程式碼生成方面的增強,使其能更快地為 Sybolic AI 建立一般化的任務模型。傳統符號式 AI 的主要缺點在於建模複雜且高度依賴人類專家;LLM 可加速此過程,更快更好地建立符號模型。符號系統的優勢在於理論完備性、穩定性、可解釋性。與統計式 AI(神經方法)結合 LLM,預期會成為未來 AI 發展的一大趨勢 (論文說的)。
原來還有這種用 LLM 的方法阿,感覺扮演的角色又不一樣了
剩下的 Reflection and Refinement / memory 感覺都是更獨立且重要的章節,留到明天講
ref:
[1] Planning Domain Definition Language
[2] Decision Transformer: Reinforcement Learning via Sequence Modeling

