昨天我們聊了模型能「看懂」什麼,但更重要的是如何「指揮」它。如果沒有好的指揮,模型再強大,但方向有可能不符合你的需求,看似頭頭是道,實際上很多時候會是毫無章法。而這關鍵點就是「提示詞」。
你想像一下,把 LLM 當成一位超強助理。你對他說「幫我安排旅行」,他會天馬行空推薦你全世界可以旅遊的地點;但你改成「本週六 9 點從高雄出發,兩天一夜、預算 6,000、想看海、不走購物行程,請用表格列出三案並標註來源」,結果立刻變精準。差別不是模型換了,而是提示詞把任務、限制、資料與輸出說清楚。這篇就講:提示詞為什麼這麼關鍵,會影響到行為邏輯、用到的知識,以及你拿到的成品可不可以直接用。
什麼是提示詞?
提示詞(Prompt)就是你給大型語言模型(LLM)的「指令」或「工作說明」。它可以是一句話:「幫我介紹AI」,也可以是一整段規格:「請用500字,針對高中生,語氣要輕鬆,列出三個AI在日常生活的應用,最後給一個延伸閱讀的參考來源。」
為什麼提示詞會影響 LLM?
LLM 本身就像一個讀過海量資料的「超級助理」,它能回答很多問題、寫文章、寫程式,但重點是它沒有主動意圖。
所以:
-
模糊的提示 → 它會「亂猜」你要什麼,輸出可能很雜亂或不中用。
-
精準的提示 → 它就能聚焦,給出符合需求、格式正確的內容。
舉個例子
- 提示詞 A:「幫我寫一篇 AI 的介紹」 → 輸出:一大段泛泛而談的文章。
- 提示詞 B:「請用表格整理三個 AI 在醫療領域的應用,每一列包含『應用名稱』『解決問題』『真實案例來源』」 → 輸出:清楚可直接用的表格。
提示詞如何影響 LLM
LLM(大型語言模型)其實就是在每一步「預測下一個最可能的字詞」。步驟是
- 模型讀進去提示詞 → 轉成向量(Embedding)。
- Transformer 架構計算這些向量,建立詞與詞之間的關聯。
- 最後在巨大的機率分佈裡挑一個最可能的詞,接著繼續下去。
提示詞不只是一句話,而是模型的輸入上下文。它會直接影響這個「機率分佈」的形狀,進而決定 模型往哪個方向生成。
影響面向主要有三個面向,分別為 Behavior Aspect、Knowledge Aspect與Output Aspect
- Behavior Aspect : 模型要「以什麼角色、任務、風格」來回應?決定回覆的口吻、專業度、解釋角度。輸出的專業度、語氣、角度,就會完全跟著提示詞走。範例如下
- 角色設定
- 你是一位資深 Java 工程師,請解釋 Optional 類別
- 你是一位專業的營養師,請幫我設計一份低碳飲食菜單。
- 任務限制
- 請用 200 字以內解釋
- 請用高中生可以理解的方式說明
- 風格
- Knowledge Aspect : 控制模型「取材範圍」與「知識邊界」。讓答案更可靠、可驗證,幻覺率下降。範例如下
- 限制來源
- 僅根據以下文件回答,若沒有相關內容請回答『無資料』。
- 請只使用台灣教育部的公開資料來解釋。
- 引用強化
- 拒絕幻覺
- 如果你不確定,請直接說『不知道』
- 不要編造內容,沒有就回答『無資料』
- Output Aspect : 決定生成結果的「結構」與「格式」。讓輸出更穩定、結構化,可直接應用在程式、文件或簡報。
- 格式要求
- 請輸出為 JSON 並符合 RFC 7807
- 結果請用 Markdown 表格顯示
- 結構化輸出
- 請分為三個欄位:方案 / 優缺點 / 適用場景
- 請條列至少五點,每點不超過 15 字
- 風格控制
簡單來說,因為提示詞在潛移默化地改變了 token 機率分佈。例如當你要求「請輸出 JSON」,模型在生成過程裡,像 {、}、冒號、引號這些 token 的機率會被拉高。等於幫模型「加了一層格式偏好」,壓制掉亂寫自然語言的傾向。
結構化寫法與技巧,明天會提。不過我想技術性的瞭解一下提示詞怎麼改變模型的輸出路徑
提示詞怎麼改變模型的輸出路徑
- 從數學角度:提示詞在改變 logits → 機率分佈
LLM 的每一步產生下一個 token,靠的是對詞彙表的**原始分數(logits)**套上 softmax 得到機率:
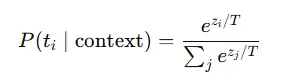
-
context 就是你丟進去的提示詞 + 已生成的 token。
-
*T(temperature)**控制平滑度;T 越低越貪婪,越高越發散。
-
你的提示詞改變了注意力分佈與中間隱狀態 ⇒ 改變 logits ⇒ 改變每個 token 的機率。
簡單的說:你叫它「輸出 JSON」,大括號、冒號、引號這些 token 的 logits 會被往上推;你叫它「當資安審核員」,風險、合規、風險控管這類詞的 logits 也會被推高。
- 從架構角度:注意力是「軟檢索」,提示詞就是檢索庫
Transformer 的注意力是內容導向位址(content-based addressing):
- Query(當前生成位置)去跟 Prompt 裡的 Key 做相似度點積,取得一組權重,再從 Value 聚合出上下文訊息。
- 因為提示詞把角色、任務、限制、資料片段塞進 prompt,模型在每步都會「回頭看」這堆文字,按語意相似度把重要片段拉出來用。
-
KV Cache 讓前面步驟的 Key/Value 被快取住(每步只算新的 Query),所以早期的結構化指示能持續影響後面的生成。
實務上有「位置衰減與干擾」(超長上下文尾端權重變弱),所以把規格放前面 + 在輸出前重申一次會更穩。
- 從學習現象:In-Context Learning(ICL)
沒有微調也能靠「示範樣本」讓模型**在上下文內學會一個模式,**分成:
-
零樣本(Zero-shot):只給任務說明。
-
少樣本(Few-shot):給 2–5 組輸入→輸出範例,模型學你的格式與邏輯(出名的「induction heads」就是在抓範例樣式)。
-
風格模仿:你給一段你要的口吻、術語,之後輸出就會被牽引。
關鍵:示範要短、穩、貼任務;錯誤示範會放大成錯誤模式。
基本上穩定輸出這會是一個超級關鍵點
那三個面向怎麼「作用到模型內部」? 上文的三軸(Behavior / Knowledge / Output)對應到內部機制如下:
A. Behavior Aspect(行為面)
-
系統/角色指令會在注意力裡變成「穩定的先驗偏好」,長程牽引語氣、責任邏輯(例:安全官 vs. 業務)。
-
限制條件(字數、對象、口吻)會讓對應 token(口語詞彙、術語密度、標記符號)在 logits 上被持續偏重。
-
衝突處理:指令層級(System > Developer > User)衝突時,高層指令會贏;同層矛盾,最新的會影響較大(注意力+位置效應)。
B. Knowledge Aspect(知識面)
- *檢索增強(RAG)**把文件嵌入檢索進來,等於把「可驗證知識」塞成 prompt 的一部分;模型就會對這些片段給高注意力。
-
負面指示(不確定就說不知道)會提高像「未知、無資料」這種 token 的 prior,降低編造詞彙的機率。
-
引用要求(加章節/標註來源)= 在輸出端插入結構化模板,把「出處語彙」拉進高機率區。
C. Output Aspect(輸出面)
-
JSON / 表格 / RFC 7807 這類格式契約,等於在 logits 空間裡對特定符號序列施加偏好;
-
停止符號(stop sequences)與長度懲罰(length penalty)進一步在解碼階段做硬/軟約束;
-
結構誘導(先印 schema、再填值)會把「結構 token」放到 beam 的前幾名,讓後續值自然長在對的位置。
明天應該會偏向介紹提示詞的技巧,然後簡單寫個AI Chat互動範例

