▋前言
在完成語音轉文字後,下一個問題是「誰在說話?」。如果系統無法區分老師與學生的發言,逐字稿與互動分析的價值就會大打折扣。因此,我們在系統中設計了「語者分離 (Speaker Diarization)」模組。
▋內容
語者分離的目標,是將同一段錄音中的不同說話者切分出來,並在文字逐字稿上正確標註「Speaker 0」「Speaker 1」。
在實務上,語者分離會面臨以下幾個挑戰:
短句切換:老師與學生快速輪流說話,模型容易誤判成同一人。
聲音重疊 (overlap speech):兩個人同時開口時,分離準確率下降。
背景噪音干擾:環境聲音可能影響 VAD 的準確性。
語者人數不確定:若錄音中多於兩人,分群的複雜度會增加。
相似聲紋:音色接近的說話者容易被混淆。
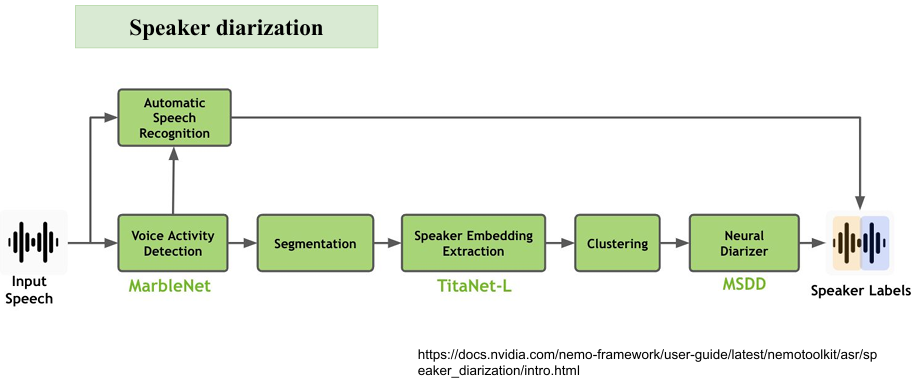
為了改善這些問題,我們在前處理階段做了 音訊切分與降噪,同時結合 embedding 模型,來提升說話者分離的精準度。主要步驟如下(請參考下圖 NVIDIA NeMo 提供的語者分離流程):
語音活性檢測(Voice Activity Detection, VAD)
負責偵測音訊中「什麼時候有人在說話」,並去除靜音片段。
分割(Segmentation)
將連續語音切成片段,方便後續辨識。
提取講者聲音的嵌入向量(Speaker Embedding)
使用TitaNet-L模型將語音轉換為向量,代表該說話者的聲紋特徵。
分群(Clustering)
根據向量相似度,把同一個人的語音片段歸類在一起。
多尺度分類解碼器(Multi-scale decoder, MSDD)
使用深度學習方法整合前面資訊,輸出更穩定的講者標註。
▋下回預告
下一篇將介紹「語者識別 (Speaker Recognition)」,解釋系統如何在分離後進一步確認「誰是老師、誰是學生」。
▋參考資料
NVIDIA NeMo
A review on speaker diarization systems and approaches
圖片源自競賽成果簡報

