!pip install -q transformers sentencepiece
from transformers import AutoTokenizer
sentence = "從前從前,有一位勇敢的少年,他夢想環遊世界。"
models = {
"GPT-2 (byte-level BPE)": "gpt2",
"BERT Chinese (WordPiece)": "bert-base-chinese",
"XLM-RoBERTa (SentencePiece)": "xlm-roberta-base"
}
for name, model_name in models.items():
print("======================================")
print(f"Model / Tokenizer: {name} (repo: {model_name})")
print("--------------------------------------")
# use_fast=True 以便使用 offset mapping(若某些 tokenizer 沒有 fast 版本會退回)
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
# 1) tokens(可讀的 subword)
tokens = tokenizer.tokenize(sentence)
print("tokens:", tokens)
# 2) token ids(模型輸入要的整數 id)
ids = tokenizer.encode(sentence, add_special_tokens=False)
print("token ids:", ids)
print("token count:", len(ids))
# 3) 把 token ids decode 回文字(看看 decode 與原句是否一致)
decoded = tokenizer.decode(ids, skip_special_tokens=True)
print("decoded back:", decoded)
# 4) offsets:每個 token 在原始字串的 (start, end) byte/char index(需 use_fast=True)
enc = tokenizer(sentence, return_offsets_mapping=True, add_special_tokens=False)
offsets = enc["offset_mapping"]
print("\nToken -> substring mapping (token, (start,end), original substring):")
for tok, (s, e) in zip(tokens, offsets):
# 注意:s,e 是字元/byte index(fast tokenizer 回傳的是字符索引),我們用 slice 取原句
subs = sentence[s:e]
print(f"{tok:20} -> ({s},{e}) '{subs}'")
print("\n")
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese") 不用記哪個是最適合的 tokenizer,輸入模型名稱會自動下載並回傳
"GPT-2 (byte-level BPE)": "gpt2" 是 key : value 的寫法
for name, model_name in models.items():
print(f"Model / Tokenizer: {name} (repo: {model_name})") 是 f-string : 在字串前面加 f ,可以在字串內使用{}來插入變數或運算結果
use_fast=True : 想載入 fast tokenizer 用 Rust(通用、編譯型的系統程式語言) 實作
tokenizer.tokenize(sentence) : 把 sentence 轉成可讀的 subword,回傳的是一個 list,每個值都是 token 字串形式
tokenizer.encode(sentence, add_special_tokens=False) :
add_special_tokens=False : 不要自動加特殊 token
ids 是 list
len(ids) 是 token 的數量
okenizer.decode(ids, skip_special_tokens=True) : 把整數 id 再轉回字串
enc = tokenizer(sentence, return_offsets_mapping=True, add_special_tokens=False)
offsets = enc["offset_mapping"]
for tok, (s, e) in zip(tokens, offsets):
subs = sentence[s:e] : 取得雲劇中從 index s 到 e-1的子字串,可以驗證 tok 與原句的對應段落是否一致
結果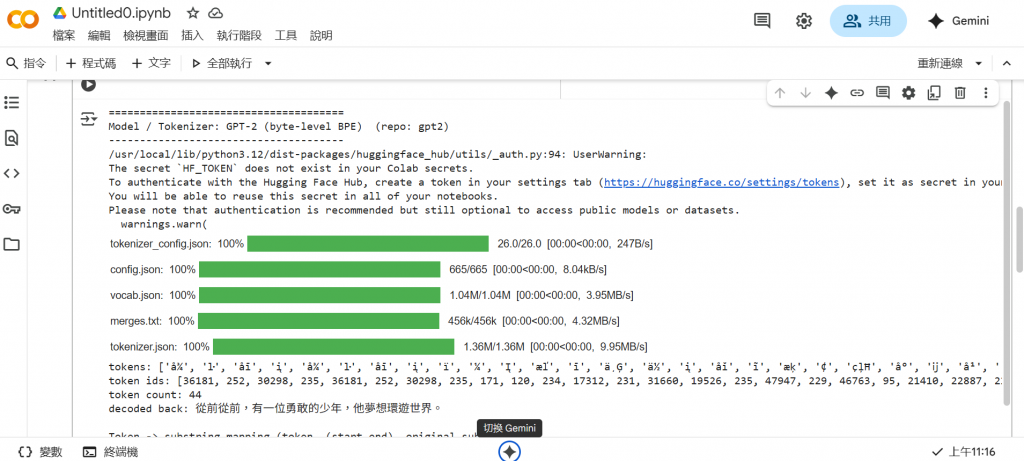



 iThome鐵人賽
iThome鐵人賽