在上篇 DAY4 知識之章-Open Data Format 中,我們聊到各種開放數據格式的特性。
本篇要介紹的是 Data Lakehouse 架構的核心技術之一:Apache Iceberg,這是一種能同時兼顧數據湖彈性與數據倉庫治理能力的表格式。

Apache Iceberg 是一個 開源表格式(Table Format),專為管理大規模數據湖中的結構化數據而設計。 它由 Netflix 在 2017 年提出,2018 年捐贈給 Apache 基金會。
👉 Takeaway:Iceberg 把「目錄管理」升級為「元數據管理」,讓數據湖能有數據倉庫級別的治理能力。
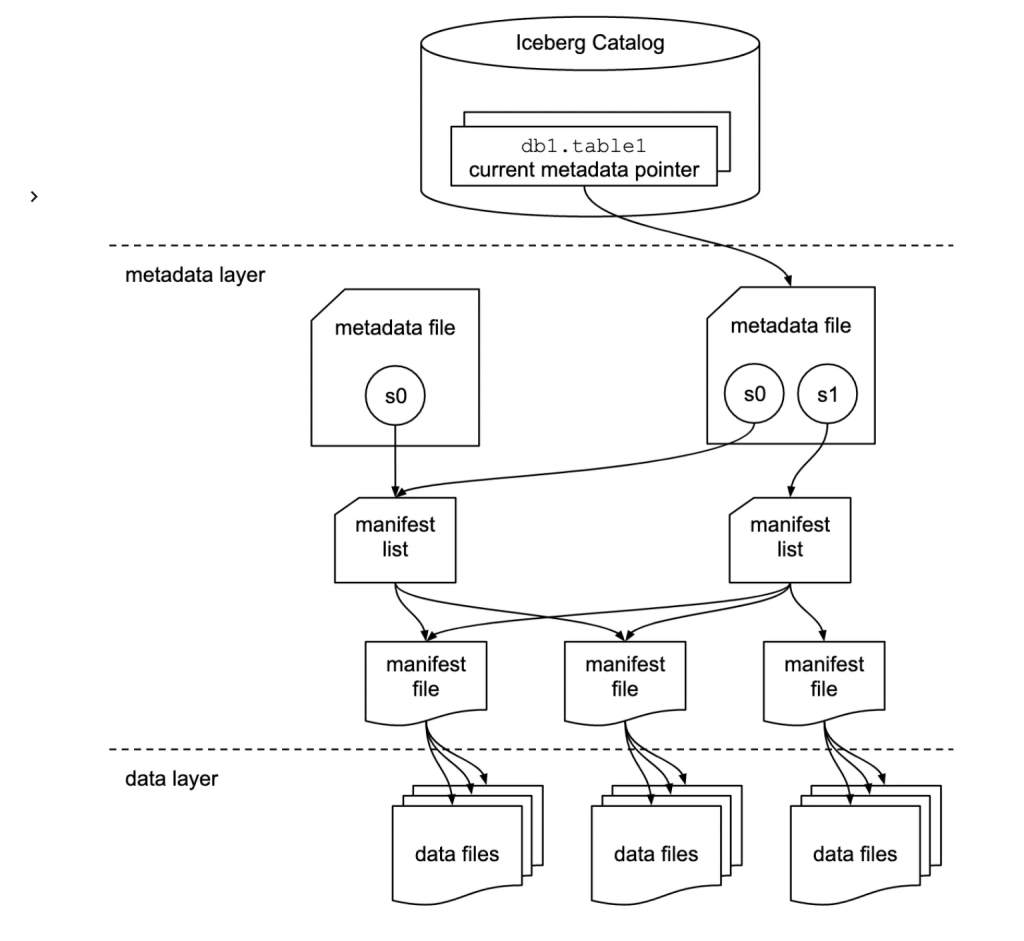
圖片來源:Iceberg 官網
Iceberg 採用三層設計:
| 層級 | 功能 | 說明 |
|---|---|---|
| 數據層(Data Layer) | 儲存數據檔案 | Parquet / ORC / Avro |
| 元數據層(Metadata Layer) | 管理 Manifest & Snapshot | 支援統計資訊、時間旅行 |
| 目錄層(Catalog) | 保存當前元數據指針 | 保證原子操作 |
👉 Takeaway:Iceberg 透過 Metadata 把數據湖抽象成「可查詢的一張表」。
👉 好處:查詢更快,無需重組數據也能演進分區。
👉 好處:大數據環境下也能安全「多人同時讀寫」。
支援動態修改,不需重寫數據:
✅ 新增欄位(可加預設值)
✅ 刪除 / 重命名欄位
✅ 類型轉換(相容範圍內)
✅ 支援嵌套結構(struct, array, map)
👉 好處:讓數據表能跟上業務需求變更。
| 技術 | 說明 | 效果 |
|---|---|---|
| Data Skipping | 利用統計資訊跳過無關檔案 | 🚀 提升掃描速度 |
| Partition Pruning | 自動過濾不相關分區 | 📉 降低 I/O |
| Projection Pushdown | 只讀取需要的欄位 | 💡 減少資料傳輸 |
| 小檔案合併 | 自動重組碎片檔案 | ⚡ 提升查詢效能 |
👉 好處:在 TB ~ PB 級數據下仍能維持高效查詢。
👉 好處:與各種計算引擎與儲存系統互通,避免廠商鎖定。
| 場景 | 使用方式 | 例子 |
|---|---|---|
| 大規模數據分析 | 儲存 PB 級資料 | 歷史數據分析 |
| 數據湖倉一體 | 同時支援批處理/串流 | ML、BI |
| 數據治理 | 權限控制、審計 | 企業合規 |
| 實時串流處理 | 與 Spark/Flink 整合 | 即時分析 |
| BI 報表 | 快速查詢支援 BI 工具 | QuickSight |
| CDC | 增量數據捕獲 | 實現變更歷史 |
👉 Takeaway:Iceberg 讓數據湖能處理傳統數據倉庫的工作負載。
| 特性 | 傳統數據倉庫 | Hive 表格式 | Apache Iceberg |
|---|---|---|---|
| ACID 支援 | ✅ | ❌ | ✅ |
| Schema 演進 | ⚠️ 有限 | ❌ 困難 | 💡 靈活 |
| 時間旅行 | ⚠️ 有限 | ❌ | ⏳ 支援 |
| 併發寫入 | ✅ | ❌ 困難 | 🤝 高效 |
| 開放格式 | ❌ | ✅ | ✅ |
| 成本效益 | 💸 低 | 💰 中 | 🚀 高 |
| 查詢性能 | ⚡ 高 | 🐢 低 | ⚡ 高 |
Apache Iceberg 讓數據湖具備了數據倉庫級的治理能力與查詢效能,並保持開放與低成本特性。在導入前,建議先在小規模數據集上測試,觀察原有「資料庫」、「資料倉儲」的效能與 Iceberg 之間的差異,逐步導入到正式數據湖倉。
下一篇將介紹 「DAY6 知識之章:儲存的基石 Amazon S3」,來了解 AWS 最核心的物件儲存服務,同時也是 AWS Lakehouse 的儲存核心。
[1] Vu Trinh - I spent 7 hours diving deep into Apache Iceberg
[2] AWS Whitepaper - Lake house architecture
[3] Iceberg 官方 - Iceberg 架構
[4] Dremio - Apache Iceberg The Definitive Guide


 iThome鐵人賽
iThome鐵人賽