LLaVA(Large Language and Vision Assistant,大型語言與視覺助理)是第一個將「指令微調」Instruction-tuning應用於圖像資料,因而催生出能夠理解並遵循複雜視覺-語言指令的多模態模型,被視為是代表多模態基礎模型發展的一個重要里程碑,且因為完全開源、可自行訓練,在學術界與開源社群被廣泛使用。
LLaVA的核心概念是參考NLP的成功經驗,近年大型語言模型(LLM)的指令微調,例如GPT-4,證明了語言可以作為通用介面,透過指令微調引導模型完成各種任務。LLaVA 將此概念擴展到「語言-圖像多模態」,以建立一個通用視覺助理。
LLaVA模型架構
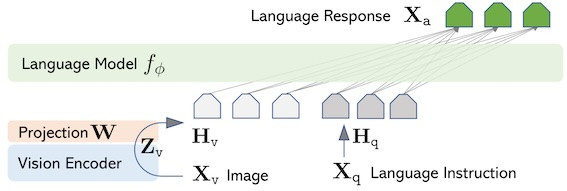
LLaVA 模型主要包括三部分架構:視覺編碼器、投影層、大型語言模型,這種架構是VLM領域中的常見架構模式。
- 視覺編碼器:使用預訓練的CLIP做為視覺骨幹 (Pre-trained Visual Backbone),用於提取視覺特徵及編碼。(例如:初始LLaVA使用 CLIP-ViT-L/14)
- 投影層 (Projection Layer):為視覺-語言跨模態連接器 (Vision-Language Cross-modal Connector),用於將視覺編碼器的輸出與語言模型的詞嵌入空間對齊。初始LLaVA (v1)使用一個簡單的線性層 (simple linear layer),LLaVA 1.5改用 MLP (多層感知器) 投影層,提高了表示能力和數據效率。
- 大型語言模型:使用預訓練的大型語言模型型(Pre-trained LLM) ,用於理解用戶指令並產生回應,指令可以是文字指令和視覺資訊。
初始LLaVA 使用Vicuna-7B 模型。使用Vicuna 是因為它是基於LLaMA模型的開源聊天模型,在公開可用的檢查點中,具備最佳的指令遵循能力(instruction following capabilities)。在後續的 LLaVA-1.5 版本中,研究人員使用了 Vicuna v1.5 (13B) 作為基礎 LLM,並發現基於 LLaMA-2 的模型(如 Vicuna-v1.5)通常比 LLaMA-1 為基礎的模型表現更好,這突顯了基礎 LLM 能力的重要性。後續版本使用了更多其他模型。
圖片來源:LLaVA page
LLaVA訓練策略
LLaVA 為兩階段訓練程序:
Stage 1:特徵對齊預訓練 (Pre-training for Feature Alignment): 這個階段的目標是將視覺編碼器(CLIP)輸出的視覺特徵與大型語言模型(LLM)的詞嵌入空間對齊,模型在訓練時,視覺編碼器和語言模型的權重都被固定 (frozen),只有投影層的權重被更新。
Stage 2:端對端微調 (Fine-tuning End-to-End): 這個階段的目的是讓模型具備遵循複雜人類指令的能力,模型在訓練時,投影層和語言模型的權重都會被更新,而視覺編碼器的權重仍然保持凍結。
LLaVA使用的訓練資料
- 研究人員在階段一使用的訓練資料是CC3M (Conceptual Captions 3 Million) 資料集的子集,為了平衡概念覆蓋範圍和訓練效率,他們篩選資料集最終得到 595K 個圖像-文本對(image-text pairs),稱為 CC-595K 子集。這些圖像-文本對被轉換成單輪對話的指令遵循資料格式,也就是,輸入是一個隨機採樣的簡短圖像描述指令,而真實的答案則是該圖像的原始標題(caption)。
- 在階段二,研究人員使用GPT-4生成微調所需要的訓練資料(圖文指令),將現有的圖像-文本對,轉換為指令遵循格式的資料。圖像被編碼為兩種形式作為提示的上下文:
Context Type 1: 圖像標註(Captions):多個描述圖像場景的句子。
Context Type 2: 邊界框(Bounding Boxes):標註場景中的物件及其空間位置。
總共生成了三種不同類型的指令遵循數據:
- 對話 (Conversation/Conversational-style QA): 涵蓋多輪問答,包括關於圖像中物體類型、計數、動作、位置和相對位置等。
- 詳細描述 (Detailed description): 旨在生成圖像豐富而全面的圖像描述。
- 複雜推理 (Complex reasoning): 提出深入的推理問題,例如分析人物行為或情境,答案通常需要遵循嚴格的邏輯進行逐步推理。
LLaVA系列演進
LLaVA持續的演進許多版本,支援更廣泛的任務,在視覺-語言之多模態理解與推理上都有顯著提昇。
- LLaVA-1.5:擴充指令數據集進行訓練,更強的視覺推理能力,及更穩定的多輪對話。
- LLaVA-1.6:支援多圖輸入,可以對比圖片、跨圖推理,有更佳的泛化能力,支援高解析度圖像輸入,這讓模型能夠捕捉更多的視覺細節。
- LLaVA-NeXT:社群合作的版本,能力接近GPT-4V,使用更大規模可視覺指令進行微調,支援的圖像解析度又更提昇,且支援動態高解析度輸入(多種解析度及長寬比),支援更細粒度的grounding,例如回答坐標或位置區域。也有更強的模型推理及光學字元辨識(OCR)能力以及「世界知識」。
- LLaVA-Med:使用在醫療場景的資料進行微調,應用在醫學影像輔助診斷(X-ray、CT、MRI)的版本,展示了LLaVA遷移訓練的能力。
LLaVA的優點
LLaVA 的把「CLIP 的圖文對齊能力」與「LLM 的推理能力」結合,並透過 GPT-4 生成的指令調教資料,開啟了開源 VLM 的快速演進之路。模型的優點包括:
- 完全開源,LLaVA 程式碼、模型權重、數據生成流程都公開,學術界與產業社群能自由二次開發
- 模型架構為模組化設計,三個部分均容易替換與擴展
- 模型簡潔的連接器與兩階段訓練,使得模型訓練成本低
- 多模態推理能力
- 社群驅動,演進快速
做為一個VLM初學者,從LLaVA入門是個不錯的開始。明天,我們就來動手實作LLaVA。
補充:
前面提到的CLIP,已經可以看懂圖像,它的核心架構是兩個編碼器,模型用影像編碼器及文字編碼器分別將圖片與文字轉換成影像及文字向量,並映射到同一個嵌入空間進行「對齊」,讓正確的影像與文字向量靠近、錯誤的遠離,它可比對圖片與文字的相似度,並回答與圖片最接近的文字,但不能進行自然語言對話。
因為CLIP是使用了給網際網路上4億個圖像與文字對資料所訓練的模型,為了不要重新訓練,LLaVA及後續的許多VLM均將CLIP做為視覺編碼器的backbone。


 iThome鐵人賽
iThome鐵人賽