在 RAG 流程中,第一步就是將文本轉換為向量。這裡我們將示範如何使用 Azure OpenAI 的 Embedding 模型結合 LangChain,將文件內容轉為向量。
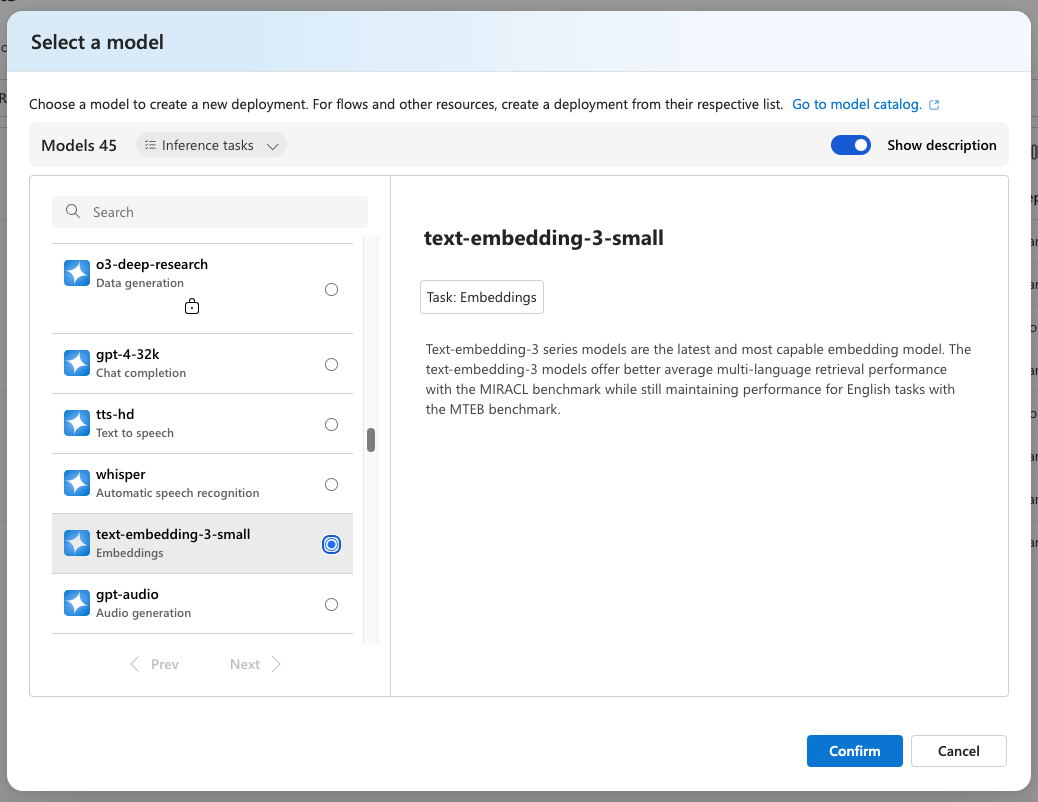
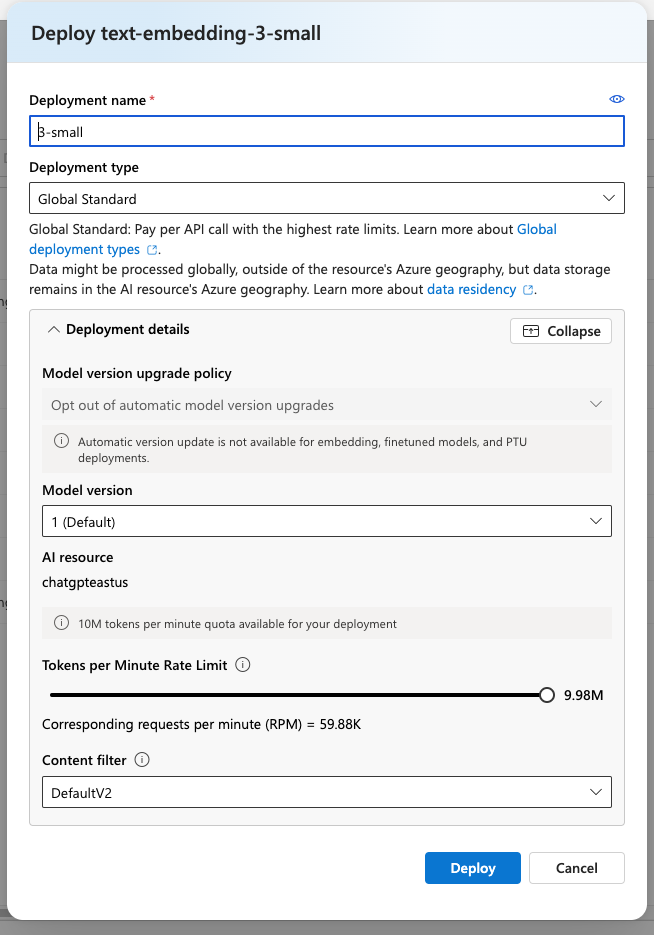
和我們在第三天時建立 GPT 模型時一樣,我們要部署起一個 Embedding 模型。我們這裡部署 text-embedding-3-small【拼音】 模型,這個模型一般稱為三小模型,是 OpenAI CP 值最高的模型,也就是語義相似度的理解高且價格便宜。如下圖所示。
from langchain_openai import AzureOpenAIEmbeddings
AZURE_OPENAI_API_KEY = "xx"
AZURE_OPENAI_ENDPOINT = "https://chatgpteastus.openai.azure.com/"
AZURE_OPENAI_EMBEDDING_DEPLOYMENT = "3-small"
text = "LangChain 是最讚的大語言模型應用開發框架,之一"
embeddings_model = AzureOpenAIEmbeddings(
api_key=AZURE_OPENAI_API_KEY,
azure_deployment=AZURE_OPENAI_EMBEDDING_DEPLOYMENT,
openai_api_version="2024-10-21",
azure_endpoint=AZURE_OPENAI_ENDPOINT,
)
vector = embeddings_model.embed_query(text)
print(f"向量維度: {len(vector)}")
print(f"向量前5維: {vector[:5]}")
uv run python day06.py,就可以看到如下圖的結果。
text 抽換成出師表或是其他很長的文章,你會發現向量維度都會是 1536 維。因為維度是模型本身決定的,和文本長度沒有相關。維度高和語義相關性的表現會有正相關,但是不是絕對的。text-embedding-3-large 的維度更高,表現更好,但是也更貴。明天我們就來建立 Azure AI search ,把向量資料整合進去吧!!

