昨天我們完成了完成文本向量化之後,現在我們需要一個高效的資料庫來儲存這些向量、並提供語義相似度比對功能。而微軟的 Azure AI Search 就是向量資料庫的佼佼者之一。
這裡我們先學會幾個 Azure AI Search 的專有名詞。
Index:類似資料表的概念,就是儲存向量與文本的地方,千萬不要把當他成傳統關聯式資料庫的索引。
Indexer:理解成排程會更正確。可以排程去抓 Blob / SQL / Cosmos 等資料放到 Index。
Skillset:把他理解成 AI 增益管線會比較好,就是可以掛載OCR、視覺、翻譯等 Azure AI 服務到資料 pipeline。
Vector Search:有 HNSW 和暴力掃的 Exhaustive。HNSW 需要把向量索引常駐記憶體、Exhaustive 則查詢時分批載入。單次回傳數量上限受查詢分頁限制,預設 50、可調到最多 1000(可用 top/skip 分頁),實務上「k」通常 ≤ 1000。
Semantic Ranker:它是從 Bing 調校而來的多語言深度模型,會對初步結果做二階重排並產生 caption/answer;需在服務層級啟用(Basic 以上)
Replica × Partition = Scale(容量與計費)。容量用 Replicas × Partitions = Search Units(SU) 表示,按小時計費 Unit。這裡要理解好,不然收費會收很貴
接著我們來和我最愛的向量資料庫 Qdrant 來比較。
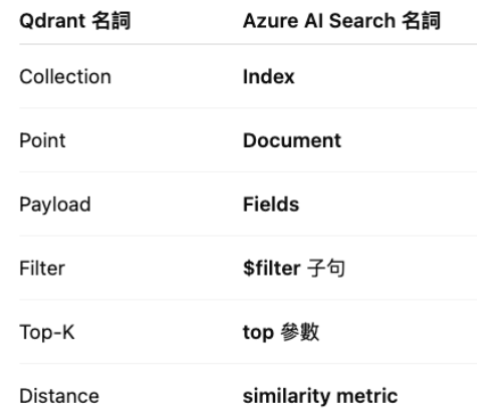
所以這裡我們就可以知道,向量資料庫的知識是可以 transferable 的,很多概念都可是可以自己對照的。先好好學好一個,要改用其他的,上手的速度很快.
Qdrant 更是「向量專門庫」,而 Azure AI Search 更像「企業搜尋平台(含向量)」。
那麼我們明天來圖解建立吧!

