上一講提到,如果在靜態網站內想要即時的記錄和顯示文章的瀏覽數,跑不掉的還是需要一個「儲存」數量的地方。例如第三方的服務如 Google Analytics、Matomo、不蒜子等等,我們可以將儲存的工作轉嫁到這些服務中,就不用管資料庫,也不需要考慮怎麼實作這個計數器。
但既然要手刻一個部落格,我們也可以自己實作記錄瀏覽數的功能,這樣既能將資料保留在我們這裡,也能客製化計數器的邏輯。
這一講就來聊聊,如果要自己設計頁面計數功能,有哪些細節需要重點考量。
我們先從最基礎的邏輯開始討論起,那就是怎麼定義「瀏覽數 + 1」?
最簡單的方式就是當頁面被讀取,瀏覽數就增加一筆。但是,我如果在同一頁面重新整理數次呢?瀏覽數就會不停的往上增加,如此一來就容易失去這個指標的公正性。
複雜一些的做法,以 Google Analytics 為例,定義了所謂的 Session:也就是讀者進入頁面後,無論怎麼重新整理、跳進去再跳出來,都只算 1 個 Session、1 個瀏覽數。一直到讀者在這個網站或頁面沒有任何互動(例如點擊、滑動頁面)的 30 分鐘後,此 Session 才算結束。

*Session 產生邏輯
更進階一些,像是 Medium 則會額外判斷這次瀏覽是否是「有意義讀閱讀」,因為判斷的越好,越能更精準的將收益給更優良創作者,所以 Medium 會計算會員閱讀時間大於 30 秒,來當作「有意義」的基礎。
簡單小結一下,Session + 有效閱讀時間是瀏覽數 + 1 較為常見的定義,而要算出 Session 和閱讀時間,我們就得先知道每次的瀏覽請求是否是同一個人,以及怎麼知道這個人有在互動。
同一篇文章在同一時間可能有多個不同的人瀏覽,我們該怎麼判斷這段時間有哪些人呢?
由於網站的資訊是透過 HTTP 這個協定來交換,每一次的瀏覽可以視為一個獨立的 HTTP Request,現在瀏覽頁面,和 10 秒鐘之後瀏覽頁面,以伺服器的角度來說,我其實沒辦法知道是誰在瀏覽,這稱作 HTTP 的 Stateless(無法保留使用者的狀態)。
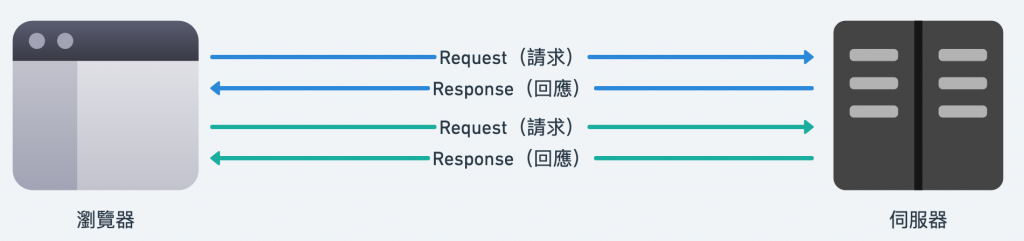
*Stateless 的 HTTP
與 Stateless 相對的是 Stateful,例如 SSH 這種協定,我在與伺服器建立連線之後,每次傳輸資料時都可以明確知道是誰傳的,像是打電話一樣,在掛掉電話之前我都能明確知道在和誰聊天。
既然 HTTP 是 Stateless 的,伺服器只能透過其他方式來辨認請求方的身份,例如最簡單的方式就是透過 IP Address 來判斷,將一段時間內同樣的 IP Address 視為同一個讀者。
然而,使用這種方式可能會有準確性的問題,因為同一個 IP Address 並不意味一定是同一個人。如果一個家庭中的不同成員,都連上同一台路由器,被伺服器所辨識到的 IP Address 就很有可能是同一個(可以透過 What Is My IP Address 來查看伺服器所看到的)。
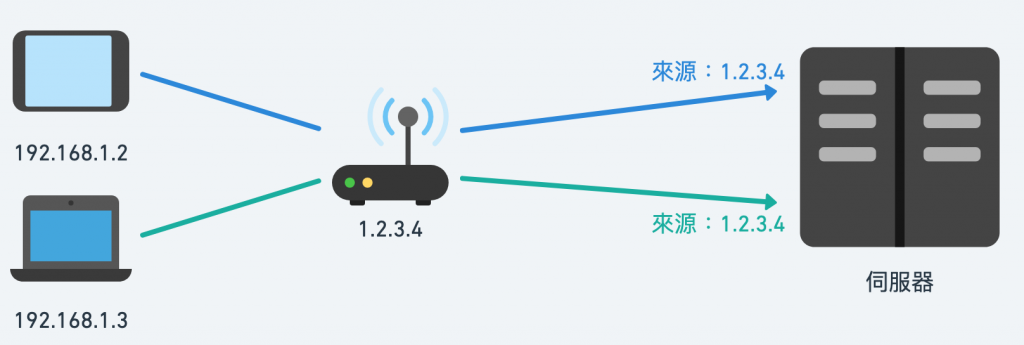
*使用路由器的 IP Address
因此,更精準一點的做法就是取得使用者裝置的資訊,可以透過解析 HTTP 的 User-Agent Header,得到包含瀏覽器型號(如 Firefox 47、 Chrome 120)、作業系統等訊息,長得樣子大致如 Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0。
只要是同樣的使用者裝置,就基本上可以視為同一個讀者,在整合 IP Address 後,就算有同樣作業系統和瀏覽器甚至是版本的讀者,都能區分的出來,足以處理絕大部分的情況了!
除了 User-Agents,有的時候也會透過 Cookies 的方式來判斷使用者,當他們第一次瀏覽頁面的時候塞入一個隨機的數值在瀏覽器的 Cookies 中,由於每次 HTTP Request 都會攜帶這組 Cookies,伺服器就能知道有這組隨機數值的人已經做過幾次請求了。
但,使用 IP Address + User-Agent 或是 Cookies 的做法其實還是防君子不防小人。
因為 HTTP 的 Header 完全可以自己填寫,只要不透過一般的瀏覽器,寫個簡單的小程式就能做 HTTP Request 並客製化 User-Agent。所以有些機器爬蟲程式,會在每次瀏覽時自己填入不同的裝置訊息,來模擬不同瀏覽器,這幾乎是零成本的。
更進一步,可以租用多個 IP Address 當成請求代理,如此一來在伺服器就能看到是不同 IP Address 及不同裝置的請求,幾乎難以分辨;Cookies 的道理也相和 Header 相同,能在爬蟲程式中自行設定,自然就不能當作絕對的標準來使用。
簡單來說,我們無法完全區分出機器人或是非正常的瀏覽行為
這算是一個進行中的爬蟲與反爬蟲之戰,一些社群、電商、新聞網站都會避免被爬蟲來批次讀取內容,所以會花很多功夫來辨識是否為真實的使用者,亦或是爬蟲程式。
不過我們在實作瀏覽量的計數倒是不需過多擔心這些爬蟲的行為,因為幫我們的文章灌水,除非是惡意如 DDNS 的攻擊行為,不然對這些爬蟲的使用者其實沒什麼好處。
因此若我們決定要自行開發計數器的話,可以使用上述討論的 IP Address + User-Agent 方式,基本上就能夠得到具有參考價值的瀏覽數了!

