前兩講我們討論了搜尋的基本原理和斷詞,帶著這些基本知識,這一講便來聊聊在我們的 Astro 專案中搜尋功能的主要流程。
現存的套件有蠻多種的,像是 Astro 官方主題用的 Pagefind、老牌的 Lunr.js、主打高性能的 Flex Search 和彈性較高的 MiniSearch 等等。
由於個人部落格的文章不會太多,各家套件的效能在這個量級比較起來其實差不多,那麼挑選的著重點就在於功能了。
剛開始有考慮過使用 Pagefind,因為套用在我們的專案中還算簡單,能夠分片(Sharding)且被 Astro 官方使用,但是在中文斷詞這塊就不太好客製。
因此最終選擇了 MiniSearch + Jieba 斷詞,基本上就能將所有流程都涵蓋在內,自己讀取文章、斷詞、Highlight 等等。
search-data.json 文件先來看看要在前端搜尋,我們需要提供怎麼樣的資訊?
這是一份叫做 search-data.json 的 JSON 檔案,包含 index 及 docs 兩個欄位,index 放的是序列化的 MiniSearch 索引字串,而 docs 則包含文章 id、 title、url 等等。
實際的 JSON 看起來像是:
{
"index": "{\"documentCount\":33,\"nextId\":33,\"documentIds\":{\"0\":\"astro-basic\",\"1\":\"astro-components-layouts\",...",
"docs": [
{
"id": "astro-basic",
"title": "Astro(一):輕又快的靜態網站產生器,淺談島嶼架構",
"url": "",
"tags": ["frontend", "javascript", "css"]
},
{
"id": "astro-components-layouts",
"title": "Astro(二):初始化專案,理解 Astro Components 及 Layouts 基礎",
"url": "",
"tags": ["frontend", "javascript"]
}
]
其中的 docs 比較好理解,就是所有文章的基本資訊;而 index 則包含 documentIds、fieldIds、storedFields 等,能讓 MiniSearch 在前端迅速復原索引和權重等重要資訊。
有了 search-data.json 後,我們可以在前端頁面載入時就順便下載這個檔案,透過 MiniSearch.loadJSON(index) 讀回所需資訊。
接著實作一個搜尋視窗,在 Input Element 中輸入任何文字時呼叫 mini.search(value) 取得每一筆資料的結果,包含 id、score、 match、terms 等等。
例如搜尋「執行」這個關鍵字,我們可以找到包含這個關鍵字的文章,不論他在標題或內文。
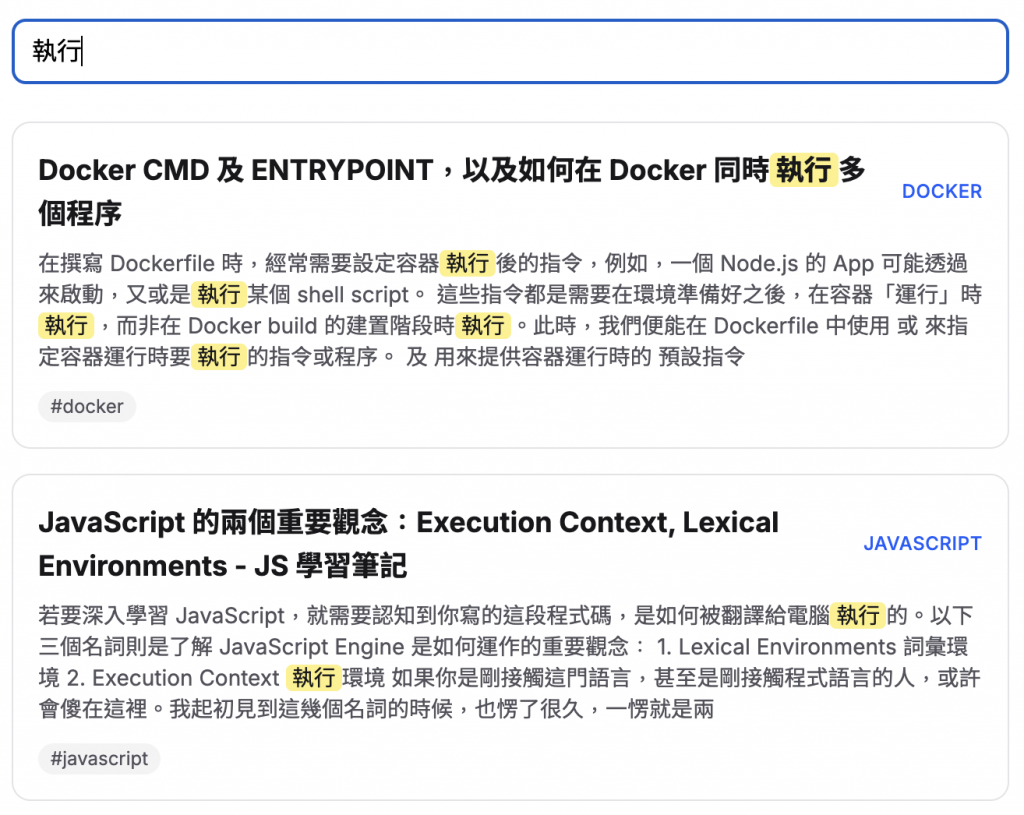
*搜尋「執行」示意圖
所謂的 terms 是實際被索引到的字詞(經過我們斷詞後的),在這個例子中就是「執行」二字; score 則是這筆文章的相關度分數,我們可以依據這個分數來排序搜尋結果。
而 match 則是一個物件,key 是被命中的詞,value 為這個詞出現在哪些欄位。以圖中第一筆文章為例,是 { '執行': ['tokenizedTitle', 'tokenizedContent'] },代表同時命中標題和內文。
完整的搜尋結果是:
{
"id": "docker-cmd-entrypoint-multiple-processes",
"score": 7.20,
"terms": ["執行"],
"queryTerms": ["執行"],
"match": { "執行": ["tokenizedTitle", "tokenizedContent"] },
"title": "Docker CMD 及 ENTRYPOINT,以及如何在 Docker 同時執行多個程序",
"tags": ["docker"]
}
值得一提的是,如果我們換一種方式來搜尋,像是剛剛這標題中有「同時執行多個程序」的字樣,我們僅僅擷取「行多」這個沒有什麼意義的組合字試試。

*搜尋失敗示意圖
就會發現找不到相關文章,這是由於我們並非全文字串完全的一一比對,而是根據常用中文的字詞作為索引,藉此提升搜尋效率。
而在實際能搜尋之前,這份 search-data.json 的文件就需要在建置的流程中產出,如此一來才能提供 MiniSearch 所需的資訊給前端使用。
我們首先可以建立一個 build-search-docs.ts 檔案,先把所有 Markdown 文章抓出來,以此專案為例,從 src/content/blog 裡面擷取內容,並抽出標題、網址、標籤等等。
再來就需要透過 nodejieba 來做中文斷詞了,將標題、內文、標籤拆成一串字詞,然後用空白串起來。例如「Docker 同時執行」拆成含有空白的「Docker 同時 執行」,這就是 MiniSearch 建立索引的基礎。
最後將每篇文章變成一個搜尋物件,包含 title、url、tags 等資訊,打包成一個 search-data.json 檔,就如同上一章節的範例所示。
這樣一來,就能在部落格中對中文做算是不錯的站內搜尋功能了!

