在當前人工智慧與深度學習的開發領域中,PyTorch 已逐漸成為最具影響力的主流框架之一。相較於早期由 Google 推出的 TensorFlow,PyTorch 以更貼近 Python 語言習慣的程式風格,讓研究人員與開發者能夠更直觀地進行模型構建與實驗。此外我們後續會介紹的 Hugging Face 也將 PyTorch 作為其主要架構基礎,可見其在業界的重要地位。
因此今天我們就來看看 PyTorch 的安裝方式與基本使用方法,幫助大家快速上手這個強大的深度學習工具。
在安裝 PyTorch 的時候,如果直接輸入以下指令:
pip install torch
那麼你安裝到的會是 CPU 版本 的 PyTorch,雖然CPU版本一樣能跑模型、做推論,但一旦遇到需要大量計算的大型深度學習模型或龐大的資料集,效能就會變得相當有限。為了真正發揮硬體的效能,建議改裝 支援 GPU 的版本來大幅加快訓練與推論的速度。
而安裝GPU的版本時,我們往往會因為個人設備不同驅動程式不同,因此我們需要根據以下步驟一步一步來正確的安裝Pytorch GPU版本。
首先我們需要知道你的顯示卡支援哪個版本的 CUDA。打開命令提示字元(CMD),輸入:
nvidia-smi
接著畫面上會出現一張表格,會顯示你的 GPU 狀態與驅動資訊。在右上角就可以看到「CUDA Version」,這就是你目前可以使用的最高 CUDA 版本。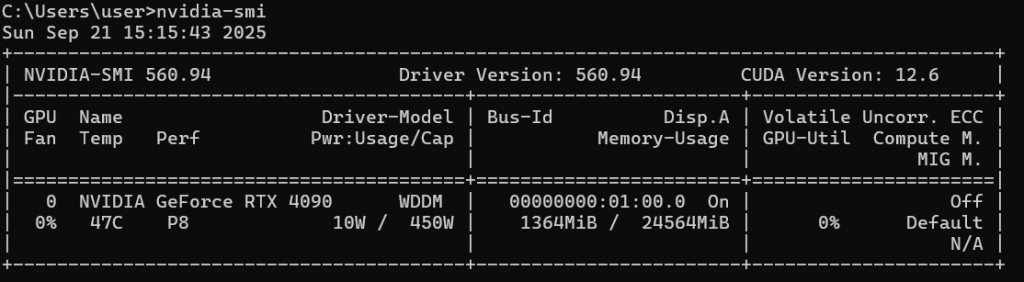
打開瀏覽器進入 PyTorch 官網。你會看到一個安裝指令產生器(可以選擇你的作業系統、Package 管理工具、Python 版本,以及 CUDA 版本。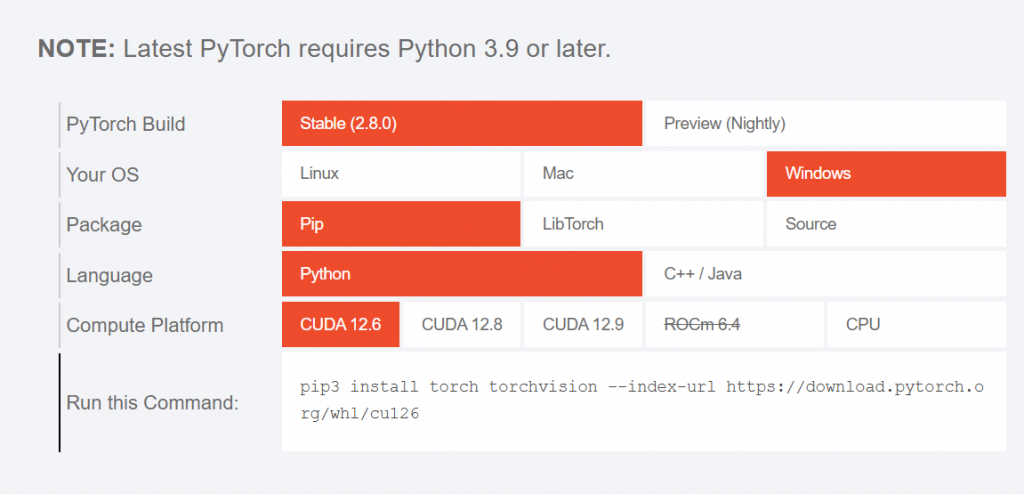
記得根據剛剛查到的 CUDA 版本來選擇對應的安裝方式,這樣才能順利使用 GPU。
假設你的 CUDA 版本是跟我一樣是12.6,則可以使用下列指令來安裝 GPU 版本的 PyTorch:
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126
如果你的 CUDA 版本不同,可以在剛剛的官網頁面中下拉選單選擇其他版本,網站會自動幫你產生對應的指令。
安裝完成後,建議測試一下是否真的安裝了 GPU 版本的 PyTorch。在命令提示字元輸入:
python
進入 Python 的互動模式後,再輸入以下兩行:
import torch
torch.cuda.is_available()
如果回傳是 True,恭喜你,代表 PyTorch 已經可以正確使用你的 GPU 了,這樣子我們就能夠繼續下一階段的動作。
現在讓我們根據Pytroch的方式修改昨天的模型訓練過程。
在 PyTorch 裡,模型的核心資料結構不是傳統的「矩陣」,而是更靈活的張量(Tensor)。這樣的設計並非隨意而為,其實藏著幾個關鍵的考量。簡單來說矩陣本質上只是一種二維資料表現形式(由行和列構成),而張量則是矩陣的延伸版本,可以自由擴展到任意維度從一維、二維,到三維,甚至更高維的資料結構都能涵蓋。
這種靈活性讓我們能夠更自然地處理像影像、語音或時間序列這類多維資料,而不必被侷限在傳統線性代數的框架之中,而在程式碼中,其實與我們先前差不多,只不過改成使用了torch.tensor。
# 製作 XOR 資料
x_data = torch.tensor([[0., 0.],
[0., 1.],
[1., 0.],
[1., 1.]], dtype=torch.float32)
y_data = torch.tensor([0., 1., 1., 0.], dtype=torch.float32).view(-1, 1)
此外PyTorch 的張量不只是一種靜態資料容器,它具備「自動微分」(autograd)功能,能即時追蹤和計算梯度。這種設計大幅簡化了從資料建構、模型運算到訓練優化的整個流程,讓使用者無需在數據結構與運算邏輯之間來回切換。
在 PyTorch 中建立模型時,其實我們只需要關注「前向傳播(forward)」的邏輯就好。你可能會注意到,forward 這個方法的名稱是不能亂改的。為什麼呢?因為當你呼叫模型本身(例如 model(x))時,PyTorch 內部其實會自動呼叫 forward() 方法。這就有點像你自訂了 __call__ 的行為一樣——如果你把 forward 改成其他名字,模型就找不到對應的前向傳播邏輯,直接報錯!
class MLP(nn.Module):
def __init__(self, input_dim=2, hidden_dim=4):
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, 1)
# He 初始化權重 + 加上一點正偏置,避免 ReLU 神經元死掉
nn.init.kaiming_normal_(self.fc1.weight, nonlinearity='relu')
nn.init.constant_(self.fc1.bias, 0.01)
nn.init.kaiming_normal_(self.fc2.weight, nonlinearity='linear')
nn.init.zeros_(self.fc2.bias)
def forward(self, x):
h = F.relu(self.fc1(x))
z = self.fc2(h)
y = torch.sigmoid(z)
return y
model = MLP(input_dim=2, hidden_dim=4)
這裡的 fc1 和 fc2 分別代表兩層線性轉換。fc1 是從輸入層到隱藏層,fc2 則是從隱藏層到輸出層。簡單來說,nn.Linear() 就是在幫你處理 Wx + b 這種線性運算,寫起來比手動計算來得簡潔許多,也讓模型架構一目了然。
所以只要搞懂 forward() 為什麼不能亂動,再加上幾層 nn.Linear() 結合你要的激勵函數,一個簡單的 MLP 模型就完成了!
在過去手動實作神經網路時,我們可能需要自己動手計算梯度,然後再更新權重。但幸好,PyTorch 幫我們省下了這些麻煩事。它有自動微分(autograd)系統,可以自動追蹤張量之間的運算過程,並在需要時自動計算梯度。
也就是說,我們只要從損失函數出發,PyTorch 就能幫我們沿著計算圖自動向後傳播誤差,計算出每個參數的梯度。接著再交給優化器去根據這些梯度來更新模型權重。首先我們得定義兩個關鍵元件:
criterion = nn.MSELoss() # 與原版相同:MSE
optimizer = torch.optim.SGD(model.parameters(), lr=0.05)
在進入訓練過程前,先快速複習一下完整流程:
# 訓練
# 訓練
epochs = 5000
for epoch in range(epochs):
y_pred = model(x_data) # Step 1: 前向傳播
loss = criterion(y_pred, y_data) # Step 2: 計算損失
optimizer.zero_grad() # Step 3a: 清空舊的梯度
loss.backward() # Step 3b: 反向傳播,計算新的梯度
optimizer.step() # Step 4: 更新模型參數
這裡有個超級關鍵但容易被忽略的小細節 optimizer.zero_grad(),為什麼我們每次都要先清掉梯度呢?
因為 PyTorch 的預設行為是會累加梯度的! 這樣的設計其實是有彈性的,方便我們做像是 mini-batch 或累積多次梯度的進階訓練策略。不過對於大多數情況來說,我們希望每次訓練時的梯度都是「全新的」,否則就會把上一次的梯度也加進來,導致權重更新錯誤,訓練結果就不準了。
與手刻神經網路相比PyTorch 真的是一大解脫,不但省去了繁瑣的數學運算與手動梯度推導,還讓整個訓練流程更直觀、易懂。這也正是為什麼我們只需要專注在「前向傳播」的設計上因為 PyTorch 會自動幫你處理後面的梯度計算與參數更新。
這樣的好處是什麼?就是當你開始接觸更複雜的模型時(像是 CNN、RNN、Transformer 等),你不會被一堆數學推導卡住,反而能夠聚焦在每一層的設計意圖與功能上。
明天我們即將進入全新的模型架構卷積神經網路(CNN)。它其實是從我們熟悉的 Wx + b 線性變換邏輯所延伸出來的,只是設計上更適合處理像是影像這類具有空間結構的資料。
在接下來的章節裡,我會繼續透過 PyTorch 的框架,帶你一步步實作整個模型訓練流程。從資料前處理、模型建構,到訓練與預測,每一步我都會細細拆解。特別是在模型結構上,我們會繼續使用 nn.Linear() 搭配其他 PyTorch 元件,來打造出屬於你的完整神經網路。
可以說這將會是我們整個 30 天深度學習系列中最核心的內容之一。 透過這個單元,你不只會學會怎麼用 CNN 解決實際問題,也會真正理解每一層模型背後的運作邏輯。
準備好了嗎?從今天開始,我們要正式進入深度學習的主戰場。


 iThome鐵人賽
iThome鐵人賽