當我們談到圖像深度學習第一個跳出來的技術名詞,往往就是 CNN(Convolutional Neural Network)卷積神經網路。這個架構幾乎成了影像識別與分類的代名詞,從自動駕駛到醫學影像分析,處處可見它的身影。
但如果我們把鏡頭拉遠一些,不難發現CNN 的核心概念其實並非誕生於深度學習時代,而是深深植根於過去的影像處理與訊號分析傳統中。
換句話說,CNN 與其說是 AI 的全新創造,不如說是「舊瓶裝新酒」:將早已有之的數學技術,如影像卷積、局部特徵提取,結合神經網路與反向傳播等深度學習的精華,再一次推向極致。
早在深度學習尚未崛起的年代卷積(convolution)就已經是影像處理界的基本功。不論是 邊緣偵測、模糊處理、銳化濾鏡 或是 紋理強化,都少不了這個數學工具的身影。
它的核心概念很簡單:使用一個小小的濾波器(kernel),在圖片上滑動,針對周圍像素做加權運算。如下圖所示:
舉例來說,當我們用 Sobel 或 Laplacian 這類經典的邊緣偵測濾波器去掃描圖片時,只要碰到像素值變化劇烈的區域(例如物體邊界),便會產生強烈響應,讓邊緣浮現出來。這種技術,即便在沒有深度學習的時代,也早就是圖像分析的核心工具。
在卷積神經網路中,卷積層(Convolution Layer) 是整個架構的基礎,與傳統影像處理不同的是,CNN 不再仰賴人為設計的濾波器,而是讓系統「自己學」,學會該使用什麼樣的卷積核來辨認特徵,這些濾波器可以理解為 AI 的視覺「眼鏡」:
而針對CNN的數學公式我們可以先看到以下寫法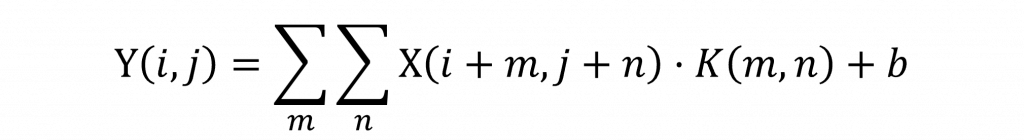
這裡的 X 是輸入的特徵圖(Feature Map),K 則是卷積核。運算方式就是簡單的滑動視窗(Sliding Windows)每次針對小區域的像素進行乘法加總,生成新的影像特徵。
雖然數學公式能精確描述卷積操作,但對多數人來說,圖像化理解往往更直觀。因此我們不談複雜的運算式,而是用一張圖來說明整個卷積的邏輯: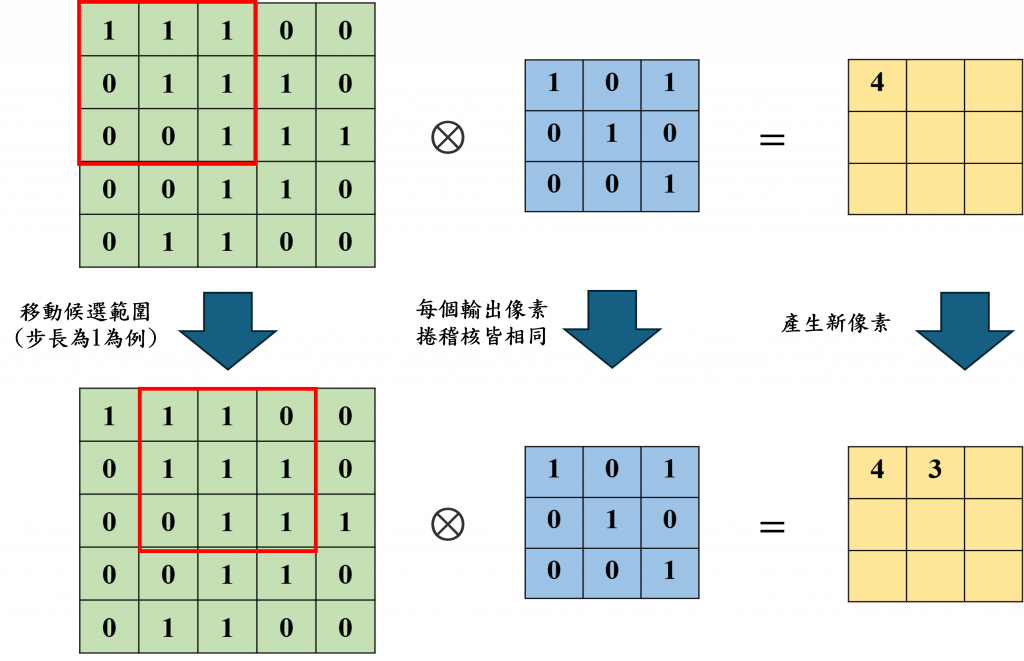
首先看圖左邊那個大格子。這代表的是原始輸入影像中的一小塊區域。你可以想像它是一張圖裡的某個「局部」,例如某隻貓咪耳朵上的一小塊畫素矩陣。這些數字代表像素的強度(通常是灰階或 RGB 數值),是電腦眼中「看見」影像的方式。這樣的格子稱為特徵圖的一部分。
接下來中間的小格子就是所謂的卷積核(也常被稱為濾波器),這個小小的矩陣裡面裝的是一組數字權重,它們的功能就像是一副特定的眼鏡——可能專門用來偵測邊緣、水平線、紋理等等。而這些權重是 CNN 自己學出來的。
現在這個濾波器會疊在原始影像的某個區塊上。它們之間會一一對應,也就是每個位置的像素值,會和濾波器對應位置的權重值相乘。完成這一輪逐元素相乘後,接下來會把所有的乘積加總起來。這個加總結果,就是這次濾波後的輸出值。
用白話說這個數字反映了原始影像在這個區塊裡,有多符合濾波器關注的特徵,你可以把它想像成一個圖像掃描器或偵測器,會專注在某一種視覺特徵上。
濾波器不會只做一次操作,它通常是往右移一格或往下移一格,然後在每一個新的位置上,重複剛才的乘法與加總步驟,這個「滑動」的動作,稱為捲積運算中的步長(stride)。透過這種方式,整張輸入圖就會被掃過一遍。
每一次滑動產生的輸出值,會被放到一個新的矩陣中。這些數值組成的結果,就是所謂的特徵圖(Feature Map)。這張特徵圖是 CNN 對原圖的一次詮釋,會強調出原圖中符合濾波器特徵的區塊。
例如這個濾波器專門抓水平邊緣,那麼在有邊緣的地方,特徵圖上會出現高值;反之則是低值或零。可以說,CNN 就是透過這一層層的特徵圖疊加,逐步抽象出圖像中的重要資訊。
在 CNN 的架構中,除了卷積層之外,另一個不可或缺的角色就是 池化層(Pooling Layer)。它的功能可以被視為一種資訊的濃縮器,用來簡化資料,同時保留最具代表性的特徵。具體來說池化可以降低特徵圖的尺寸,進而減少模型的運算負擔;它也能過濾掉多餘的細節與雜訊,讓神經網路聚焦在關鍵特徵上。
此外池化還具有強化「平移不變性」的效果,意思是即使影像中的物體稍微位移、旋轉或變形,模型仍能正確辨識出相同的特徵,其中最常見的是最大池化(Max Pooling)與平均池化(Average Pooling)。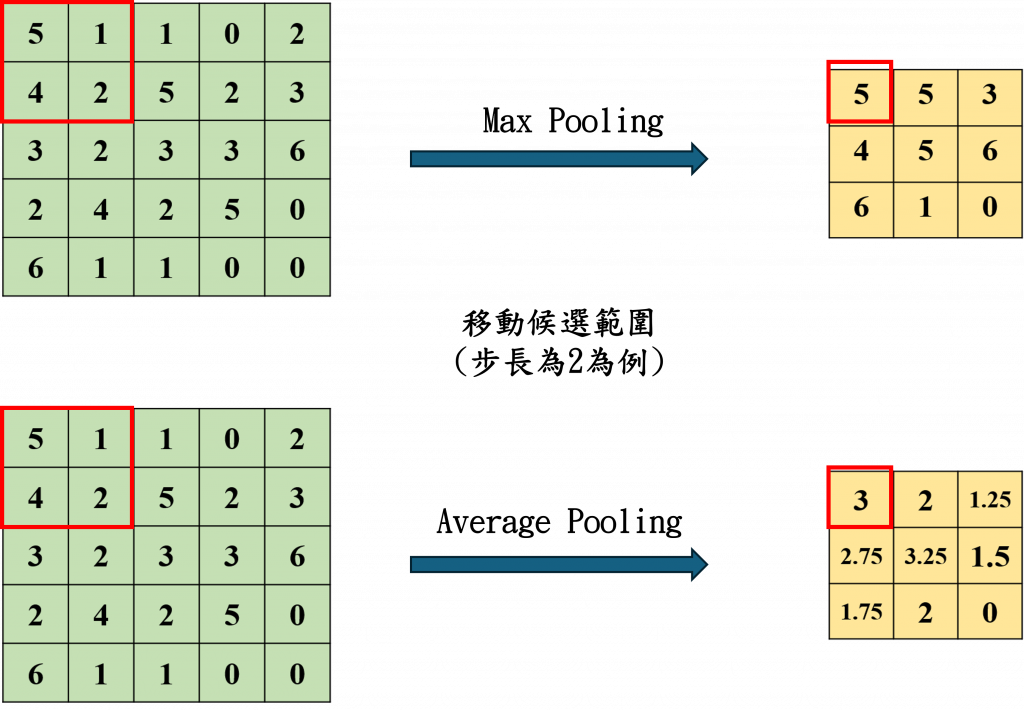
如圖中顯示最大池化會在小區塊中取出數值最大的那個,聚焦於最強烈的特徵訊號;而平均池化則取該區塊中的平均值,使特徵圖整體趨於平滑,兩者本質上都是為了讓網路在保留關鍵訊息的同時,降低圖像維度與計算成本。
經過前面的卷積與池化步驟後CNN已經完成了它的任務,它抽取了像是邊緣、紋理、形狀,甚至更抽象的高階概念,但接下來,一個問題浮現了:我們該如何根據這些特徵,做出具體的判斷? 這個答案就是全連接層(Fully Connected Layer)。
所謂全連接其實就是我們的DNN,只不過接收的是特徵圖,而該層也是在 CNN 中進行「決策」的地方。例如,當我們訓練一個用來分類狗、貓、人臉的模型時,前面的卷積層與池化層負責抽取特徵,而全連接層則會根據這些特徵值,最終輸出「這張圖是哪一類」的判斷結果。
在實作上 CNN 中的特徵圖會先被攤平成一維向量,再送入一個或多個全連接層進行加權計算,並搭配**激勵函數(如 ReLU、Sigmoid 或 Softmax)**產出最終輸出。
簡單來說,卷積層與池化層像是圖像的觀察者,而全連接層則是做決定的人。這三者各司其職,構成了一個能夠學習、理解並判斷視覺資訊的完整神經網路架構。
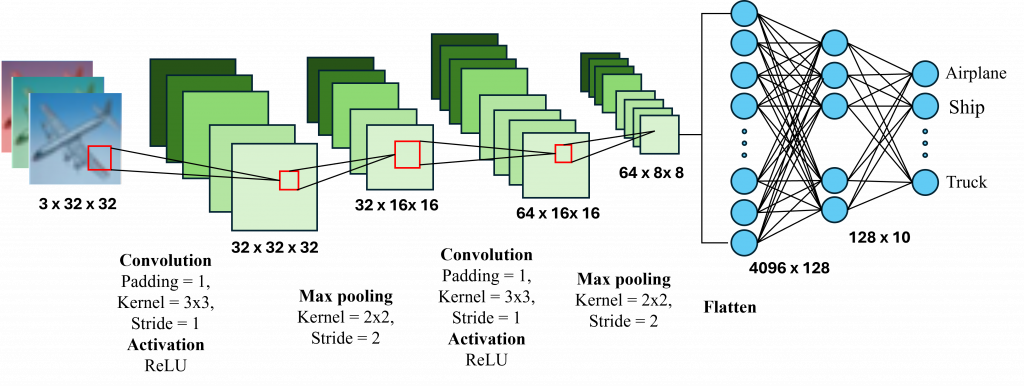
到這裡,我們已經完整理解了 CNN 的基本架構從卷積層如何提取特徵、池化層如何濃縮資訊、到全連接層如何完成分類判斷。明天我們將透過一個實際的圖像分類任務,一步步帶你用 PyTorch 從零建構 CNN 架構,讓你親手實踐今天所學的內容。
不只是學理更是實戰!但一旦動手實作,就會變得具體而清晰。


 iThome鐵人賽
iThome鐵人賽