
昨天我們看了 Pod 調度策略,從最簡單的 Node Selector,到更靈活的 Node Affinity / Pod Affinity,再到從 Node 角度反向管控的 Taints & Tolerations。我們看到 Kubernetes 不只是把 Pod「跑起來」,更能透過策略決定 Pod「跑在哪裡」。
但有些任務其實不需要長期保持執行狀態,比如一次性的資料處理任務或定時報表生成。這類任務跟 Web Service 最大的不同在於:它們不是長期運行,而是執行完就結束。今天就要來看看 Kubernetes 如何處理這些需求:Job 與 CronJob。
Job 專門用來處理執行完就結束的任務,跟需要持續提供服務的應用程式完全不同。如果有使用過雲端服務,應該知道類似的概念:需要一直服務使用者的是 Services,執行一次就結束的就是 Jobs。
典型的 Job 使用場景:
在實務上最常見的是資料處理 Pipeline,會先寫好資料處理邏輯,如果處理時間固定就設定定期執行,如果不是就用其他服務當 Trigger,一旦觸發就執行整套資料處理流程。
在 Docker 裡,如果只想跑一次性任務(比如計算兩數相加),容器啟動、執行、輸出結果、結束,這很自然。容器的退出狀態碼遵循標準:0 代表正常完成,非 0 代表出現錯誤。
但在 Kubernetes 裡,如果用一般的 Pod 來跑,因為預設 restartPolicy=Always,Scheduler 會不斷重啟這個 Pod,完全不符合一次性任務的需求。這就是為什麼需要 Job 的原因。
Kubernetes Job 的特性:
如果 Job 解決的是「執行一次」,那 CronJob 就是解決「週期性排程」的需求。
他是管理基於時間的 Job,,可以在特定時間或週期性地執行任務。比如特定時間運行一次 Job 或週期性的於特定時間運行 Job。ConJob 格式與 Linux 下的 crontab 相同。(分、時、日、月、週)
例如:
0 9 * * * → 每天早上 9 點執行*/5 * * * * → 每 5 分鐘執行一次0 0 1 * * → 每月 1 號午夜執行先看看命令式建立 Job:
# 建立 Job
kubectl create job my-job --image=busybox -- echo "Hello my job"
# 觀察 Job 和 Pod 狀態
kubectl get jobs,pods -l job-name=my-job
# 查看執行完畢 Jobs 的 log
kubectl logs pods/my-job-8hh9z
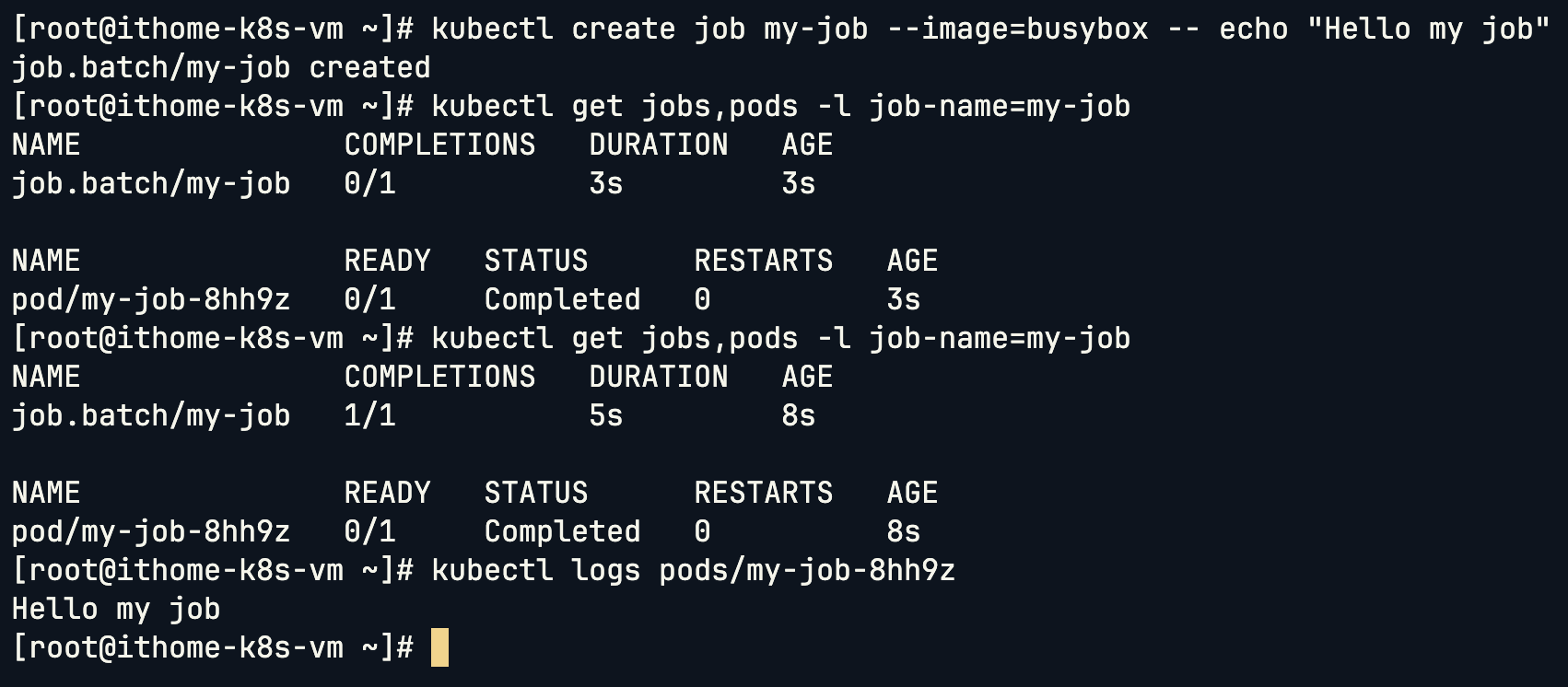
這是 Job 執行成功的情況。我們來看看如果故意讓 Job 失敗:
kubectl create job my-job --image=busybox -- 123
下方錄頻可以看到右邊我們查看 Pod 的狀態,可以看到因為 123 不是有效指令,Job 會一直失敗並重試,直到成功或手動刪除。
先看看用一般 Pod 會怎樣:
apiVersion: v1
kind: Pod
metadata:
name: math-pod
spec:
containers:
- name: math-add
image: busybox
command: ['expr', '5', '+', '2']
因為 restartPolicy 預設是 Always,Pod 會不斷重啟。
雖然可以改成 OnFailure 或 Never,但這不是 Best Practice。來看看 Job 聲明式:
apiVersion: batch/v1
kind: Job
metadata:
name: math-pod
spec:
template:
spec:
containers:
- name: math-add
image: busybox
command: ['expr', '5', '+', '2']
restartPolicy: Never
注意 Job 的 restartPolicy 不支援 Always,只支援 OnFailure 和 Never。
Job 執行完就結束,不會重啟。實務上的 Job 通常會處理資料後將結果存到雲端儲存 (Google Cloud Storage) 或持久化儲存中 (PV / PVC)。
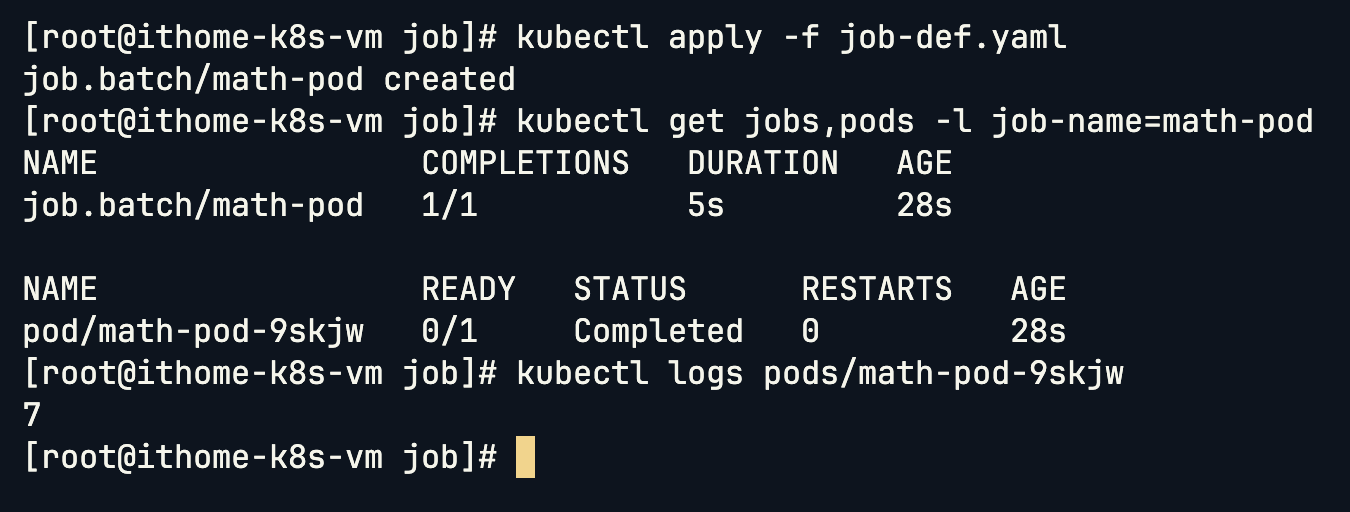
如果要讓 Job 執行多次,可以加入 completions 參數:
apiVersion: batch/v1
kind: Job
metadata:
name: math-pod
spec:
completions: 10
template:
spec:
containers:
- name: math-add
image: busybox
command: ['expr', '5', '+', '2']
restartPolicy: Never
Pod 會依序執行,右邊可以看到 Job 狀態會同步更新,直到完成指定的次數。
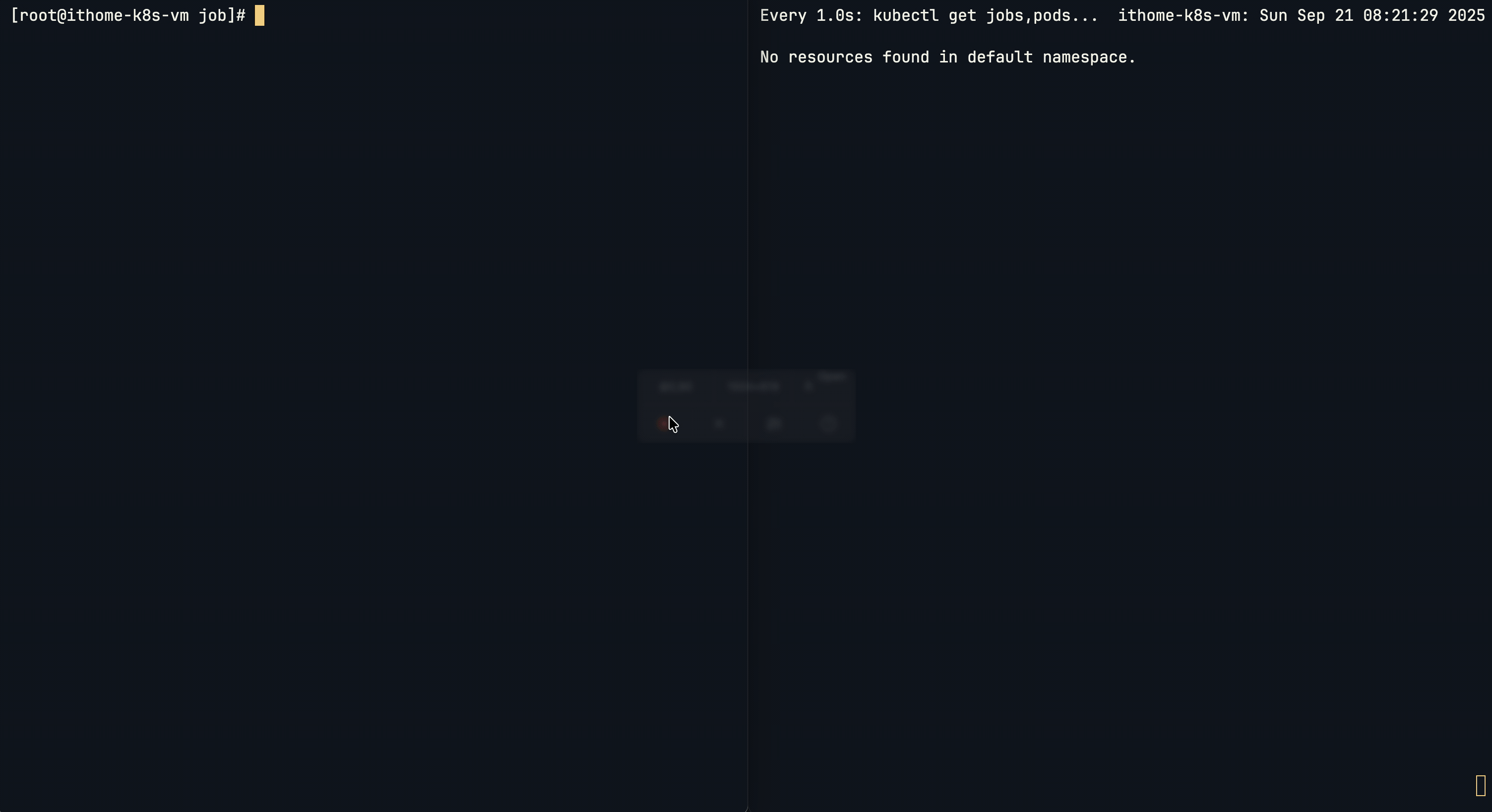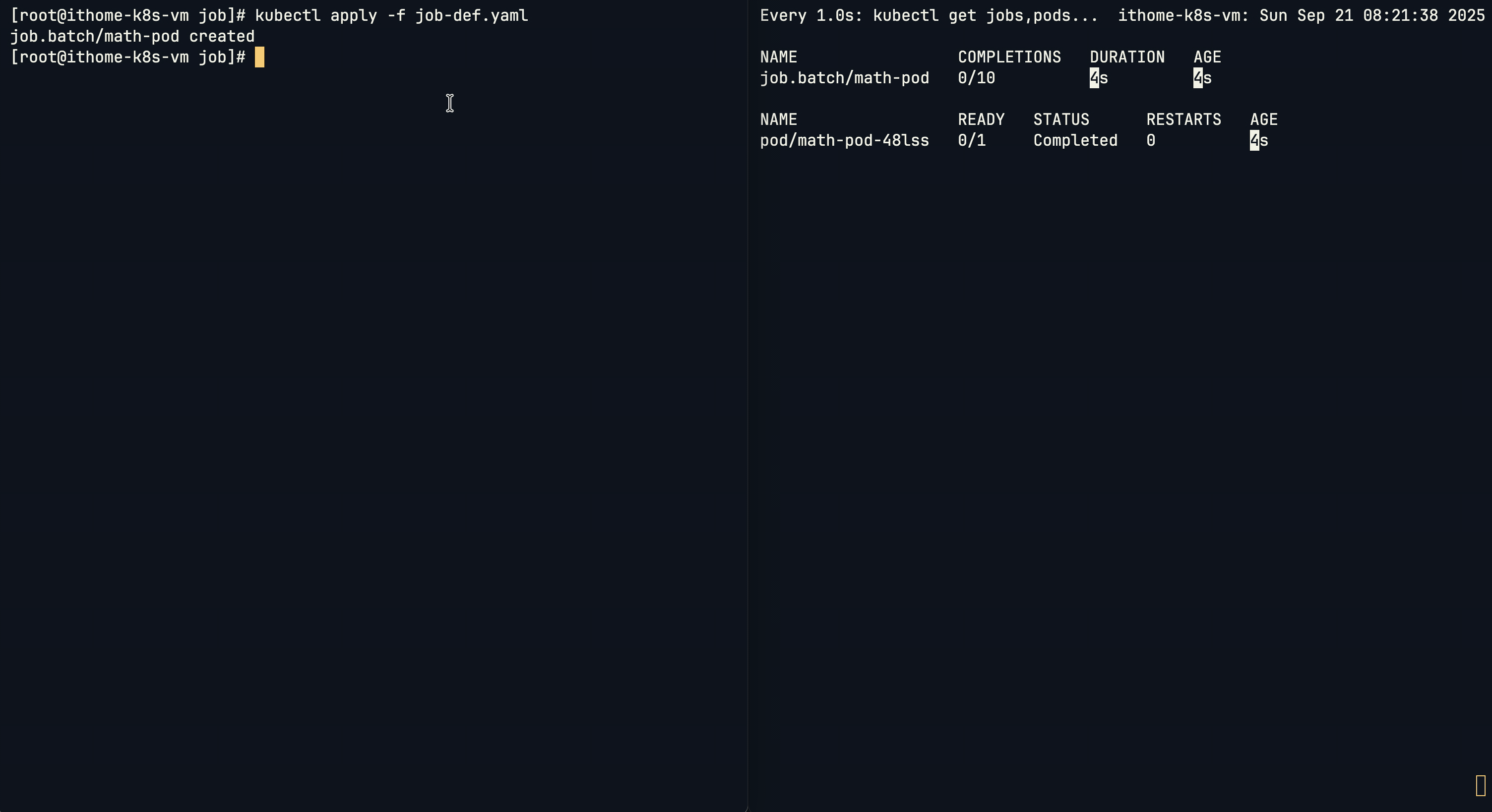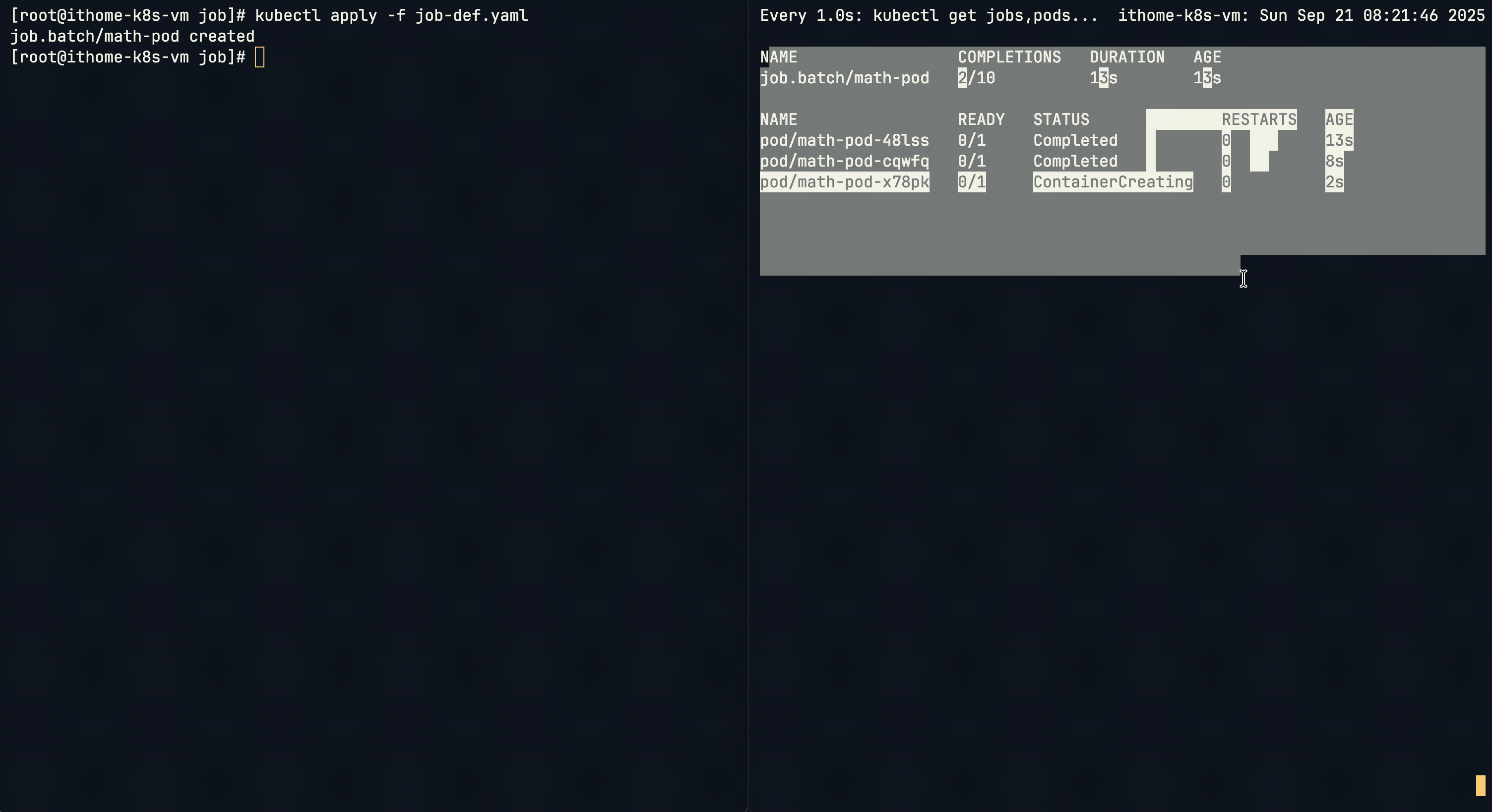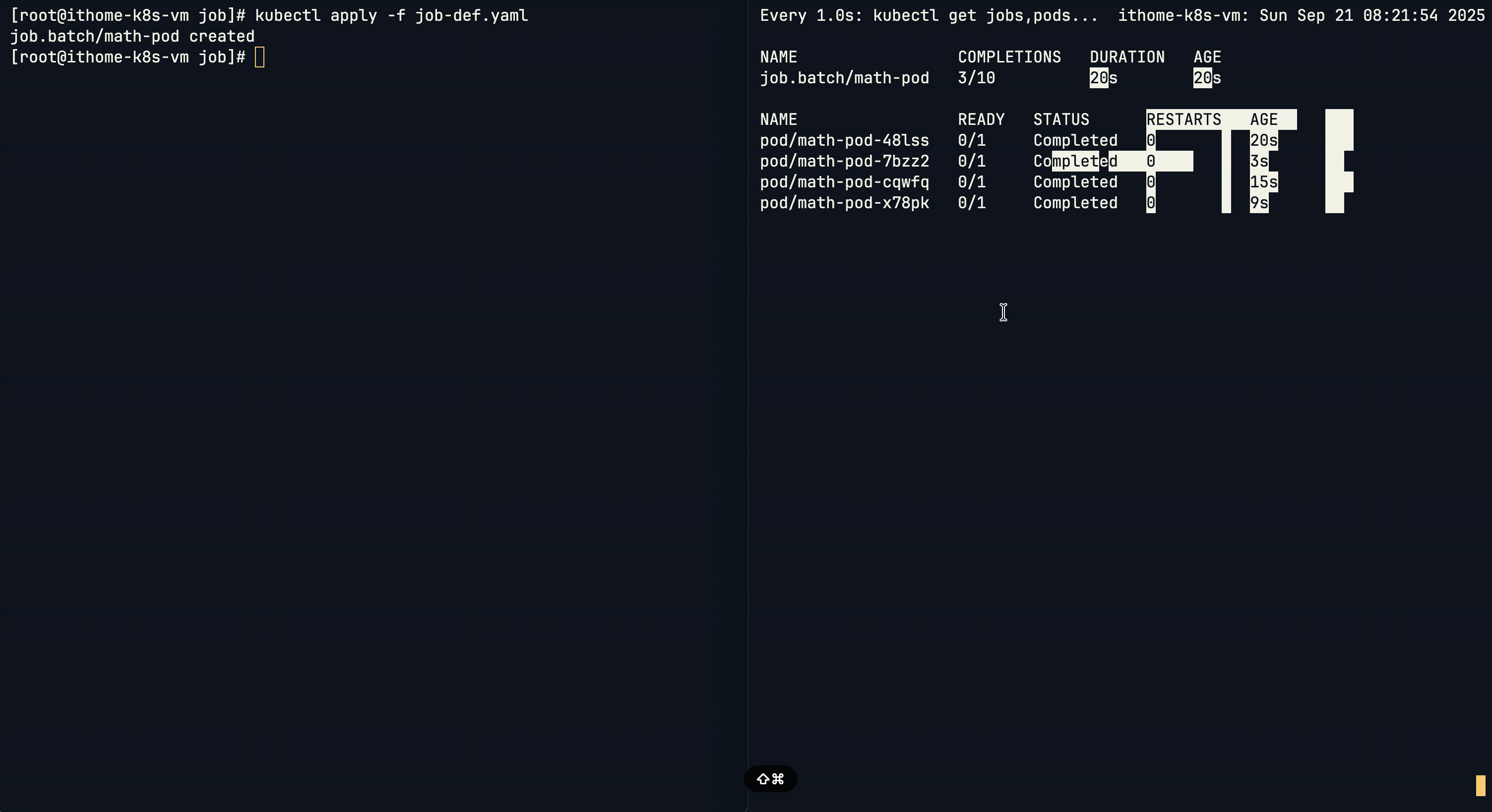
測試 Job 執行失敗的情況:
apiVersion: batch/v1
kind: Job
metadata:
name: random-error-job
spec:
completions: 3
template:
spec:
containers:
- name: random-error
image: kodekloud/random-error
restartPolicy: Never
即使某些 Pod 執行失敗,Job 會繼續建立新的 Pod 來重試,直到達到指定的成功完成次數。
假如我們不想要按照順序,想要一次同時執行 Job,可以加上 parallelism 參數同時執行多個 Job:
apiVersion: batch/v1
kind: Job
metadata:
name: random-error-job
spec:
completions: 3
parallelism: 3
template:
spec:
containers:
- name: random-error
image: kodekloud/random-error
restartPolicy: Never
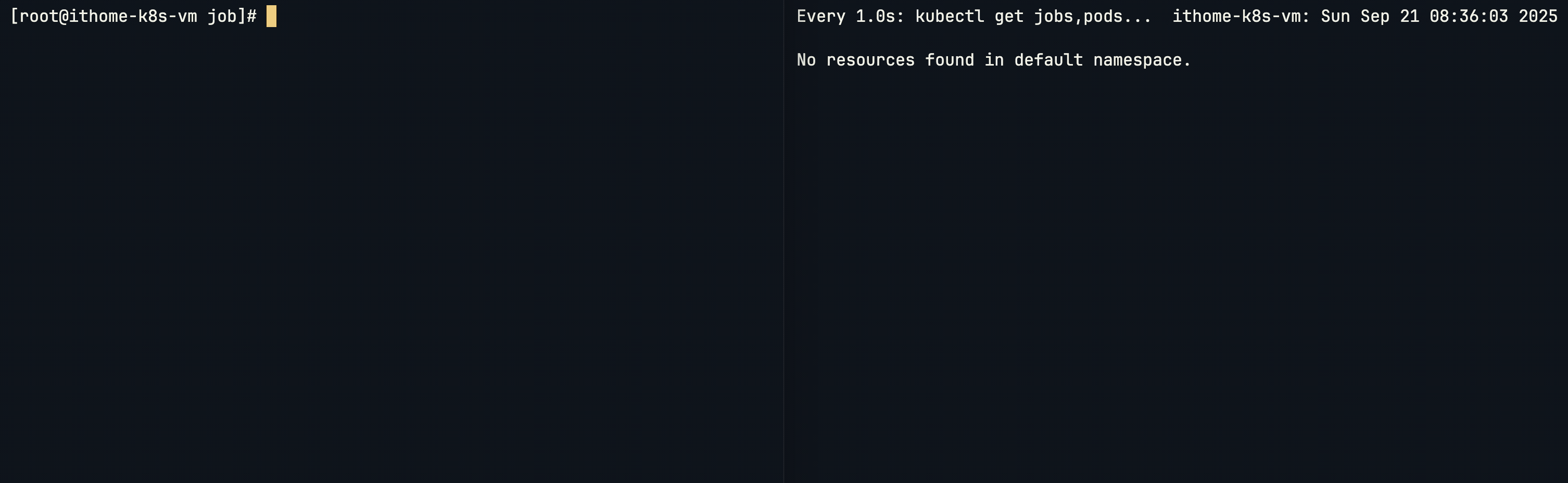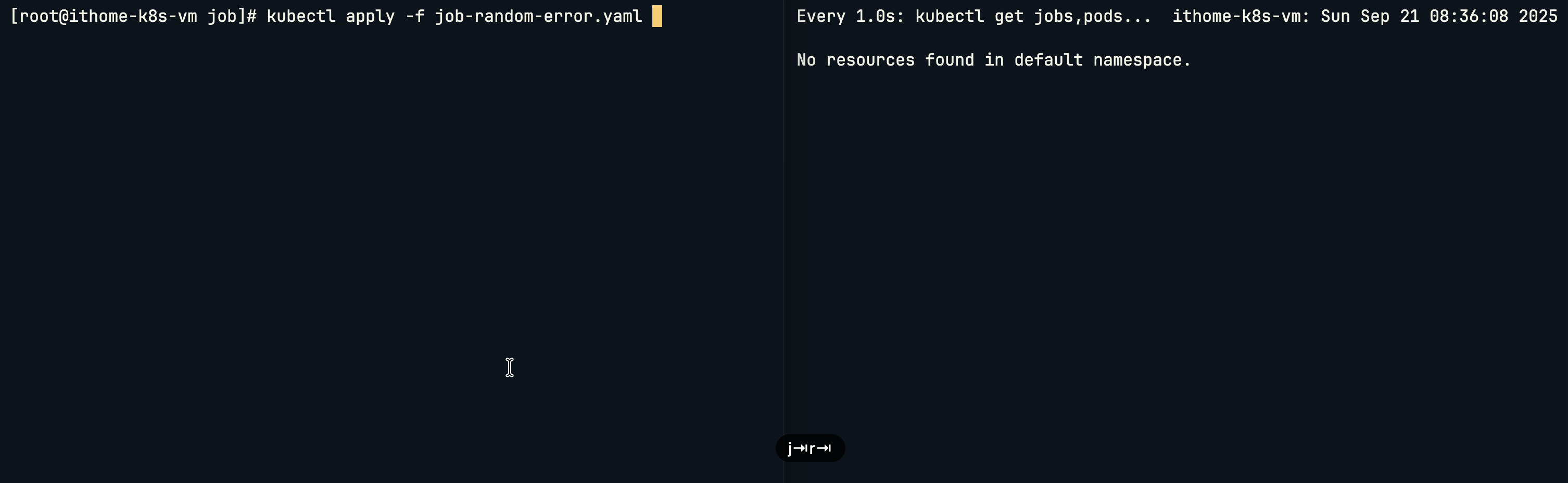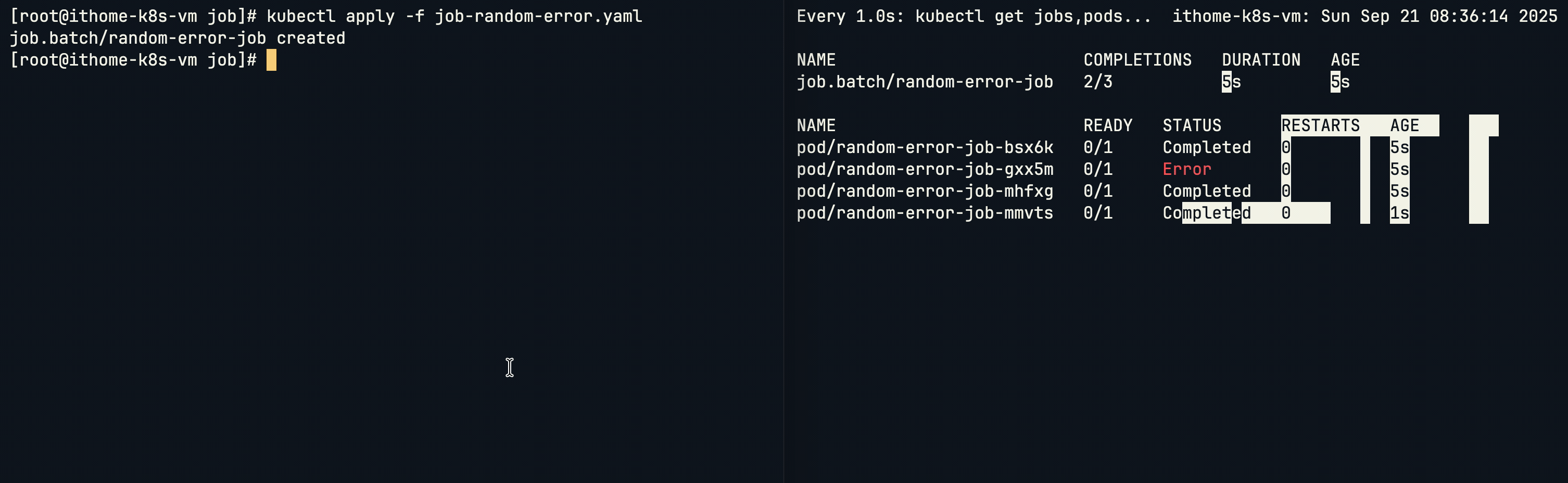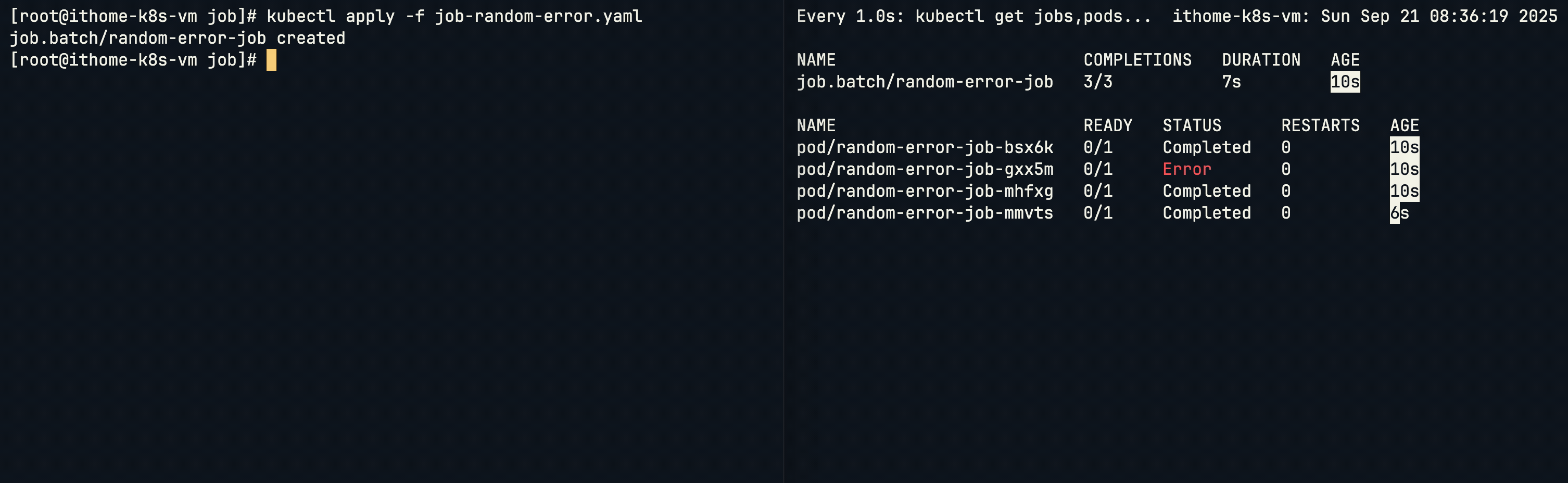
設定 parallelism: 3 後,如果剩餘未完成的任務少於 parallelism 次數,就會只啟動需要的 Pod 數量,而不會強制啟動 3 個。
命令式建立 CronJob:
# 建立 CronJob(每分鐘執行一次)
kubectl create cronjob my-cronjob --image=busybox --schedule="*/1 * * * *" -- /bin/sh -c "date; echo my conjob"
# 查看 Job 的狀態
kubectl get cronjobs,jobs,pods
每分鐘 CronJob 會建立一個新的 Job,當 Job 的 Pod 完成後,CronJob 的 ACTIVE 計數會回到 0。
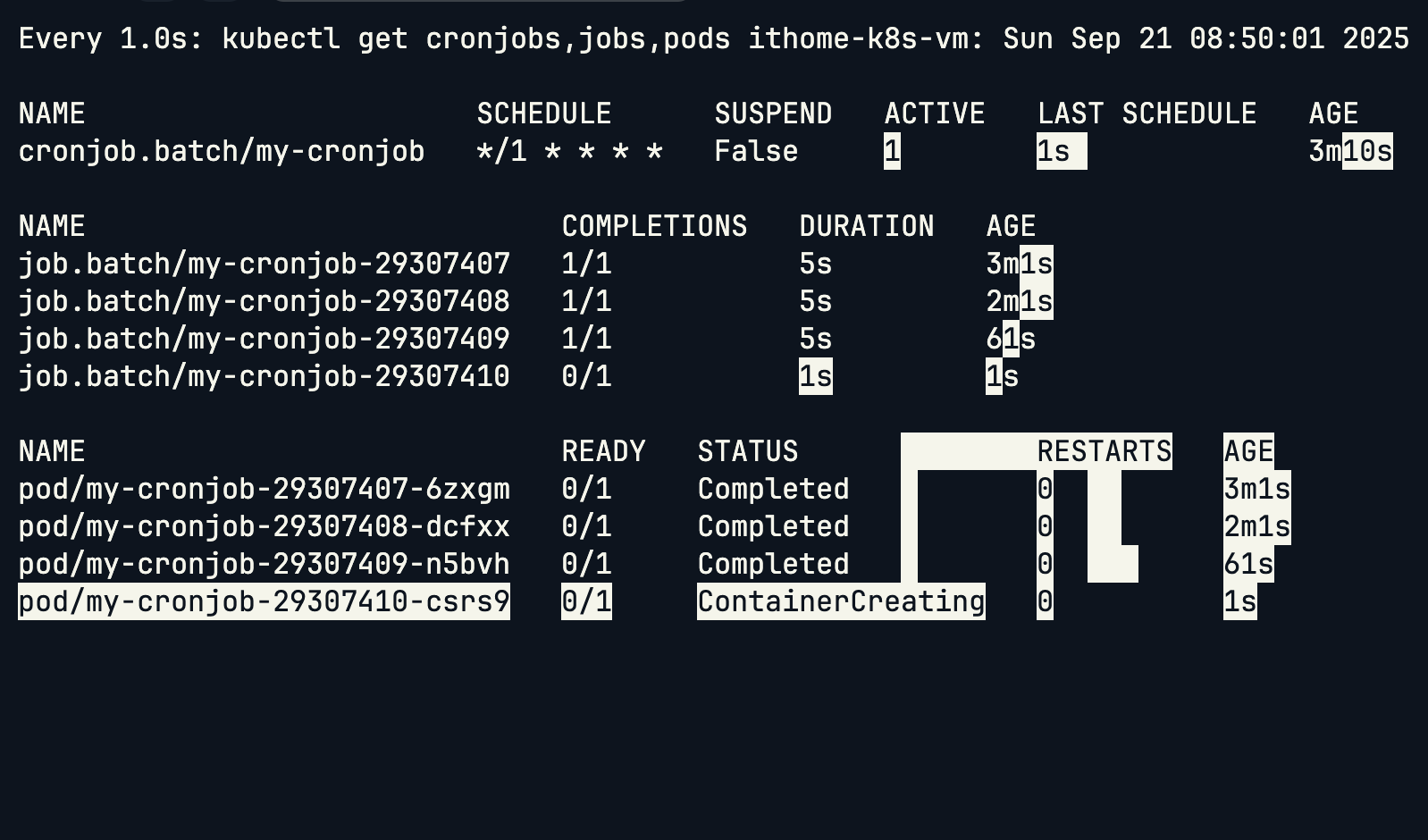
CronJob YAML 結構:
apiVersion: batch/v1
kind: CronJob
metadata:
name: math-job
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
completions: 10
parallelism: 3
template:
spec:
containers:
- name: math-add
image: busybox
command: ['expr', '5', '+', '2']
restartPolicy: Never
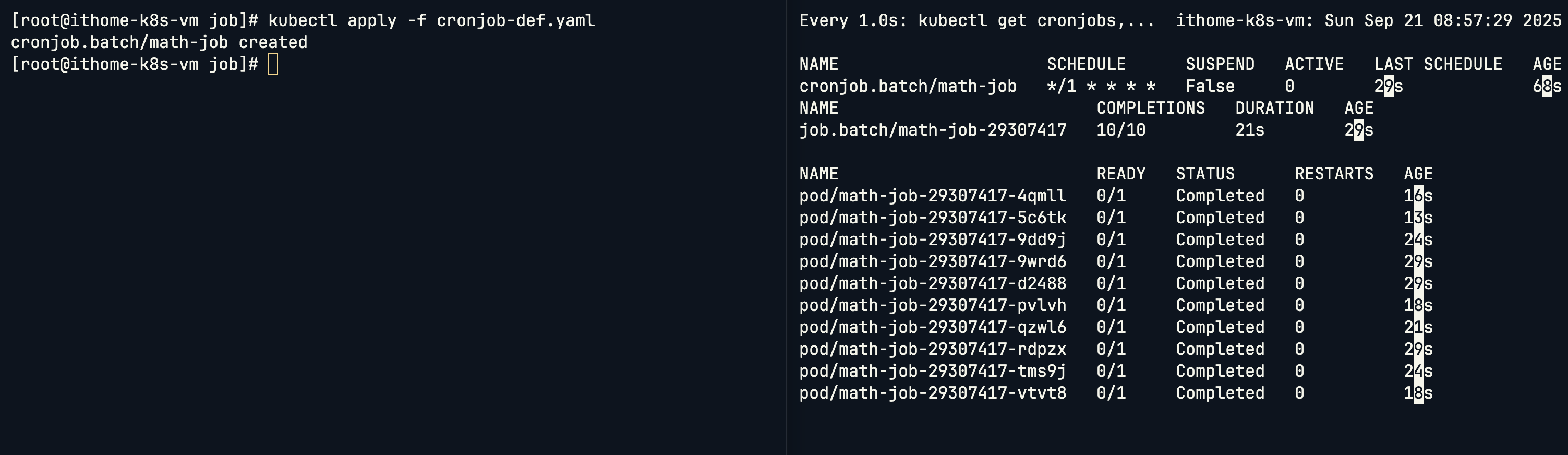
CronJob 的 spec 有三個層級:
spec → 負責 schedule。spec → 負責 completions / parallelism。spec → 負責容器定義。今天我們看了 Job 和 CronJob 如何處理一次性任務和排程任務。Job 解決了執行完就結束的任務需求,避免了用一般 Pod 會不斷重啟的問題。透過 completions 和 parallelism 參數,我們可以精確控制任務的執行次數和平行度。CronJob 則把時間排程納入,讓批次任務能自動在固定週期執行,像是資料備份、報表生成、系統清理等情境。
不過,光是能控制「什麼時候執行」還不夠。無論是 Deployment 常駐的 Web Pod,還是 Job/CronJob 一次性的工作 Pod,都會面臨同樣的問題:Kubernetes 怎麼知道這個 Pod 真正能工作?
想想看這些情境:應用程式可能需要一些時間來初始化資料庫連線、載入配置檔案,或者執行中的應用程式可能因為記憶體洩漏而變得無回應,但容器本身還在運行。如果沒有適當的健康檢查機制,Kubernetes 可能會把流量導向還沒準備好的 Pod,或者讓已經故障的 Pod 繼續運行。
明天我們要來看看 Readiness Probe 和 Liveness Probe,看看 Kubernetes 如何透過這些探針機制來確保應用程式的健康狀態,讓服務真正達到高可用性!


 iThome鐵人賽
iThome鐵人賽