

昨天我們看了 Job 和 CronJob 如何處理一次性任務和排程任務。Job 解決了執行完就結束的任務需求,CronJob 則把時間排程納入,讓批次任務能自動在固定週期執行。
不過,光是能控制「什麼時候執行」還不夠。無論是 Deployment 常駐的 Web Pod,還是 Job/CronJob 一次性的工作 Pod,都會面臨同樣的問題:Kubernetes 怎麼知道這個 Pod 真正能工作?
想想看這些實際情境:
如果沒有適當的健康檢查機制,Kubernetes 可能會把流量導向還沒準備好的 Pod,或者讓已經故障的 Pod 繼續運行,造成服務中斷或效能問題。
今天我們要來看看 Liveness Probe 和 Readiness Probe,看看 Kubernetes 如何透過這些探針機制來確保應用程式的健康狀態!
預設情況下,kubelet 只會監看 Pod 中的容器進程 (process) 是否還在運行。只要進程存在,kubelet 就會認為 Pod 處於 Running 狀態,並且不會介入。
但這會產生一個盲點:想像一個情境,我們的應用程式因為程式碼的 bug 陷入了無限迴圈,或是後端資料庫連線池已滿導致無法處理新請求。此時,容器的進程本身並未崩潰,Pod 狀態依然是 Running,但它實際上已經失去了服務能力。
對於這種情況,kubelet 無法自行察覺。如果沒有一個主動檢查的機制,這些有問題的 Pod 會繼續接收來自 Service 的流量,導致使用者請求失敗。為了解決這個問題,Kubernetes 提供了健康探針 (Probe),讓 kubelet 能夠深入容器內部,檢查應用程式的真實健康狀況。
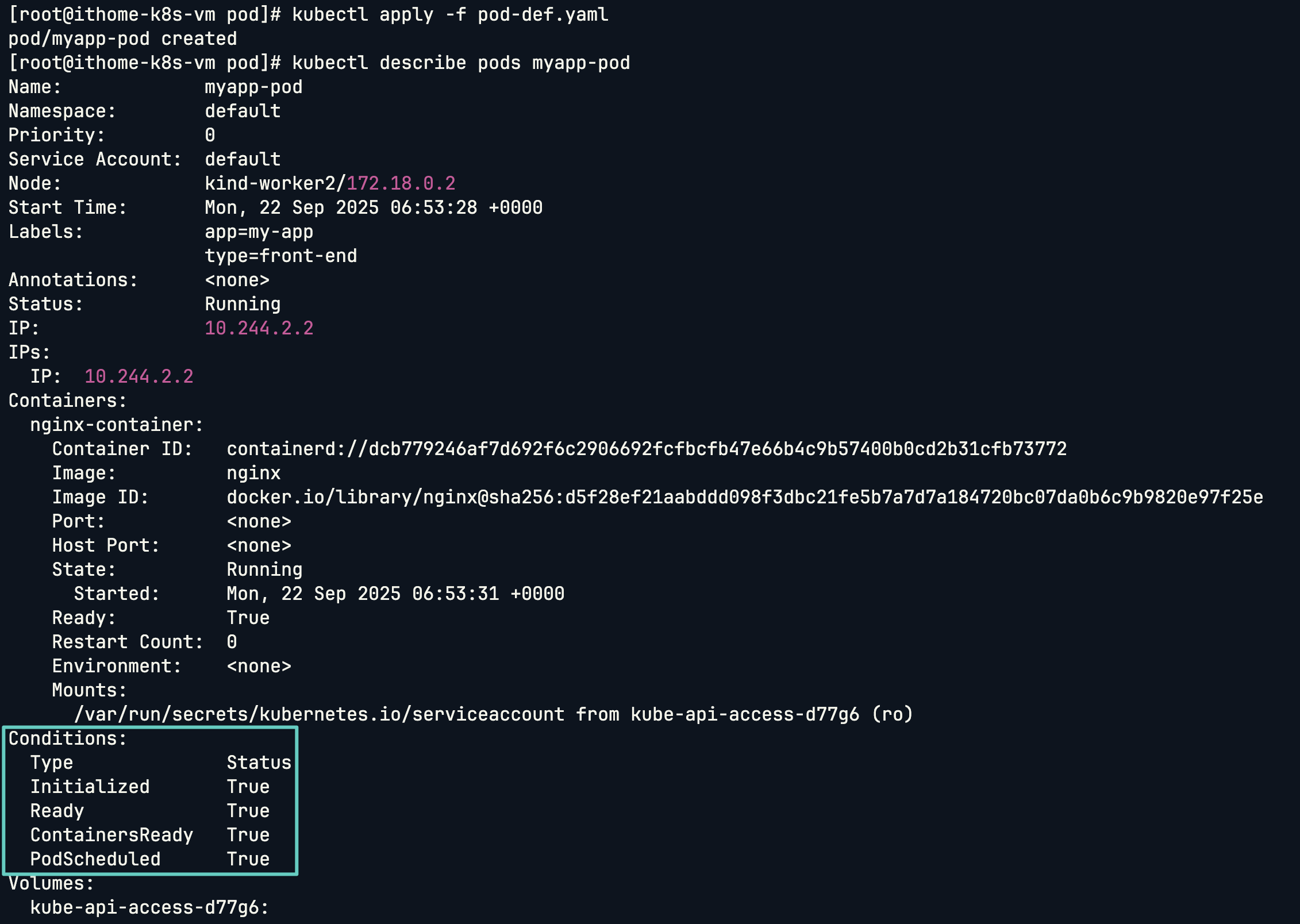
要理解探針的作用,先來看看 Pod 的狀態。當我們用 kubectl get pods 查看時,看到的是 STATUS,它是一個宏觀的總結,例如:
Node Affinity 或 Taints & Tolerations 時,若找不到合適的節點,Pod 就會處於此狀態。然而,STATUS 提供的資訊很有限。要了解更詳細的內部狀態,我們需要查看 Pod 的 Conditions:
探針的核心目標,就是去精準地控制 Ready 這個條件,告訴 Kubernetes 何時該將流量導入 Pod,以及何時該將其移除。
我們可以用 describe 指令來查看 Conditions:
kubectl describe pod <pod-name>
Liveness Probe 的職責很單純:定期檢查容器內的應用程式是否還「活著」,也就是判斷當前容器是否健康。
我們先從 Docker 來看看。如果在 Docker 中,一個 Nginx 容器的進程崩潰了,容器會直接退出 (Exited 狀態 (非0))。但 Docker 作為一個容器引擎,並不會自動重啟它,服務就此中斷,直到管理者手動介入。
在 Kubernetes 中,情況好一些。如果容器進程崩潰,Kubernetes 的自我修復機制會根據 restartPolicy 自動重啟容器。
但真正的問題是:如果應用程式卡死了,程序沒有退出,容器本身還在 Running 狀態,實際上卻無法提供服務怎麼辦?
這時就需要 Liveness Probe 來進行探針,必要的話針對 Container 進行重啟或刪除後重新運行一個新的 Container。我們來看看它的運作機制:kubelet 會定期執行探針,如果連續失敗達到設定的閾值 (failureThreshold),kubelet 就會判定這個容器不健康,並果斷地將其終止 (kill),然後根據重啟策略建立一個全新的容器來取代它。這確保了卡死的應用能被即時汰換,實現真正的自我修復。
Readiness Probe 則解決了另一個問題,Container 雖然啟動了,但它是否已經 準備好接收流量?
預設情況下,只要容器程序一啟動,Kubernetes 就會將其標記為 Ready,並開始導入流量。但在實務上,許多應用程式需要一段載入或初始化的「暖機」時間。
一個經典的例子是 Jenkins 服務。它的容器可能在幾秒內就啟動了,但 Jenkins 應用本身需要 10 到 15 秒來初始化,載入插件和設定。在這個空窗期,如果 Service 冒然把流量導向這個 Pod,使用者只會看到錯誤頁面。
Readiness Probe 正是為此而生。當一個 Pod 啟動時,如果配置了 Readiness Probe,那麼在探針成功之前,它的 Ready 狀態會一直是 false。端點控制器 (Endpoints Controller) 會因此將這個 Pod 的 IP 位址從所有相關 Service 的端點列表中暫時移除。直到探針檢測成功,Ready 狀態變為 true,它的 IP 位址才會被加回去,正式開始接收流量。
在設定探針時,有兩個參數至關重要,它們決定了探針是否有效。
第一個是 initialDelaySeconds (初始延遲)。每個應用程式從啟動到能夠穩定回應需要時間,這個時間會因為程式複雜度、硬體資源(尤其是在我們 【Day08】叢集資源怎麼分?ResourceQuota 和 LimitRange 配額管理實戰 提過 Limit 和 Quota 的限制下)而有所不同。我們必須設定一個合理的初始延遲,確保 kubelet 不會在應用程式還在暖機時就進行探測,否則探針註定會失敗,也就失去了意義。
第二個是 timeoutSeconds (超時時間)。它定義了 kubelet 等待探針回應的最長時間。如果在指定時間內沒有收到成功的回應,kubelet 就會認定本次探測失敗。這個值需要根據應用程式的回應速度來權衡設定。
我們已經了解了為什麼需要探針,以及它們如何影響 Pod 的狀態。那麼,節點上的 kubelet 實際上是如何對容器進行診斷的呢?它主要透過以下四種「處理器」(Handler) 來執行檢查:
這是最靈活的一種探針方式。kubelet 會直接在容器內部執行一個我們所指定的命令。判斷成功的標準非常簡單:只要該命令的 返回碼 (exit code) 為 0,探針就視為成功。如果返回任何非零值,則視為失敗。
這種方式適用於需要自定義檢查邏輯的場景,可以執行一個 cat 命令來檢查某個關鍵設定檔是否存在,或是運行一個內部腳本來確認多個服務依賴項(如資料庫連線和快取服務)是否都已準備就緒。
這種探針會嘗試與容器的某個指定 IP 位址和通訊埠(Port)建立 TCP 連線。如果連線能夠成功建立(代表該通訊埠正在被監聽且可接受連線),探針就診斷為成功;反之,若連線被拒絕或超時,則為失敗。
這個方法非常直接且高效,特別適合用來檢查非 HTTP 的後端服務,例如資料庫(MySQL、Redis)或其他任何基於 TCP 協定的應用程式,能快速判斷服務的網路層是否可用。
這是最常用於 Web 服務和 API 的探針方式。kubelet 會對容器指定的 IP、Port 和路徑發送一個 HTTP GET 請求。只要伺服器返回的 狀態碼 (status code) 介于 200 到 399 之間(即 2xx 成功或 3xx 重定向),探針就視為成功。
這種方式不僅能確認網路服務是否在監聽,更重要的是,我們可以透過設計特定的健康檢查端點(例如 /healthz 或 /ready),在 API 內部執行更豐富的邏輯來回報應用程式的真實健康狀況,是確保 Web 應用可靠性的首選。
這是針對使用 gRPC 框架的現代微服務所設計的專門探針。kubelet 會使用 gRPC 協定,對指定的通訊埠發送一個遠端程序呼叫 (RPC),以確認服務的健康狀態。要使用此探針,容器內的應用程式必須實作標準的 gRPC 健康檢查協議。
如果服務回報的狀態為 SERVING,則探針診斷為成功。相較於只能確認通訊埠是否開啟的 TCPSocketAction,gRPC 探針能更深入地確認應用程式本身是否已準備就緒且能正常處理請求,是一種更精準、更貼近應用層的檢查方式。它非常適合用來檢查 etcd、Prometheus 等原生支援 gRPC 的雲原生應用。
在進入實戰之前,先補充一個小重點:
Liveness Probe 和 Readiness Probe 在 YAML 中的配置方式其實是一樣的,只有參數名為 livenessProbe 和 readinessProbe 的差異。
不管是 Exec、HTTP、TCP 還是 gRPC,四種探針方法都能同時應用在 Liveness 或 Readiness 上,只是檢查的目的不同。因此,以下實戰部分我會分別實作四種探針方式,並隨機搭配 Liveness / Readiness。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
來看一下我們這個是如何進行模擬的,首先我們在 Container 啟動之後會立刻在 /tmp 目錄下建立一個名為 healthy 的空檔案。這個檔案就是我們用來標記「健康狀態」的信號。接下來等待 30 秒之後,我們將這個檔案刪除,那因為我們刪除了代表「健康狀態」信號的檔案,因此應用程式就模擬進入了「故障」狀態。
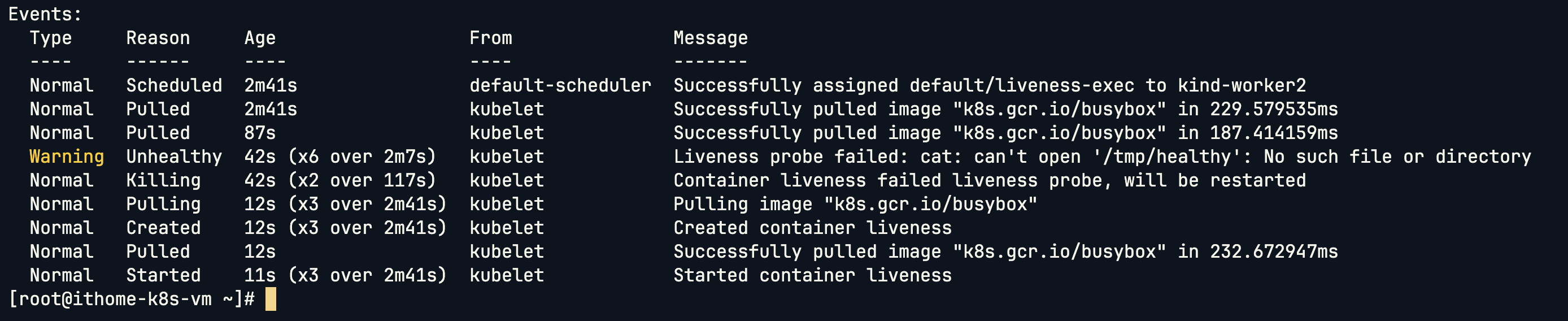
上圖可以看到是 kubelet 在用我們寫好的 Exec Command 在執行探針,每五秒進行一次探測。可以看到當探測失敗的時候會發出 Unhealthy 的 Warning,並且隨後將 Container 刪掉之後重啟。他會去判斷 /tmp/healthy 這個檔案是否存在,存在代表探測成功,不存在則代表探測失敗。
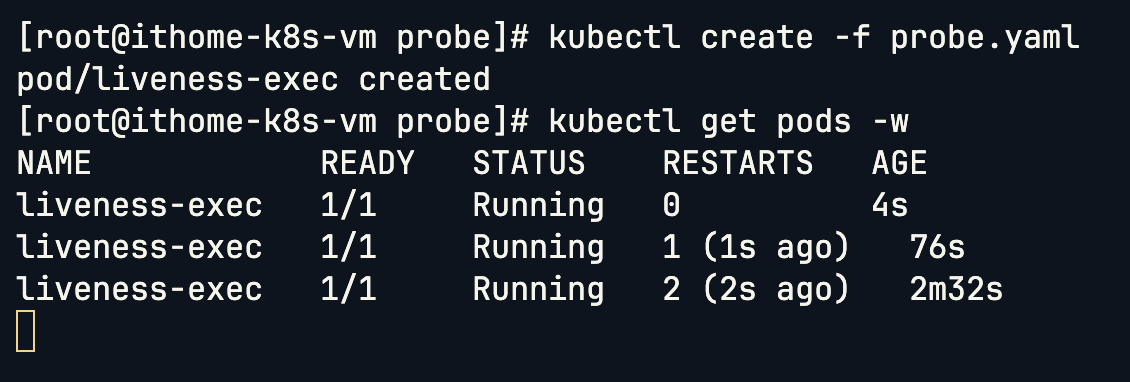
容器啟動時會建立 /tmp/healthy 檔案,30 秒後自動刪掉。探針每 5 秒檢查一次檔案是否存在。當檔案消失時,探針失敗,kubelet 會判定容器不健康並自動重啟。
我們使用由 Kubernetes 官方專案提供的多功能測試映像檔 agnhost 來進行 HTTP Get Action 探針,我們傳入args: [- liveness] 告訴 agnhost 映像檔要以特定的「liveness」模式運行。他會立即在 8080 通訊埠上啟動一個 Web 伺服器,在 啟動後的前 10 秒內,對於 /healthz 路徑的任何請求,它都會回應 HTTP 200 OK(代表健康),10 秒之後,它會開始回應 HTTP 500 Internal Server Error(代表內部伺服器錯誤)。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/e2e-test-images/agnhost:2.40
args:
- liveness
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
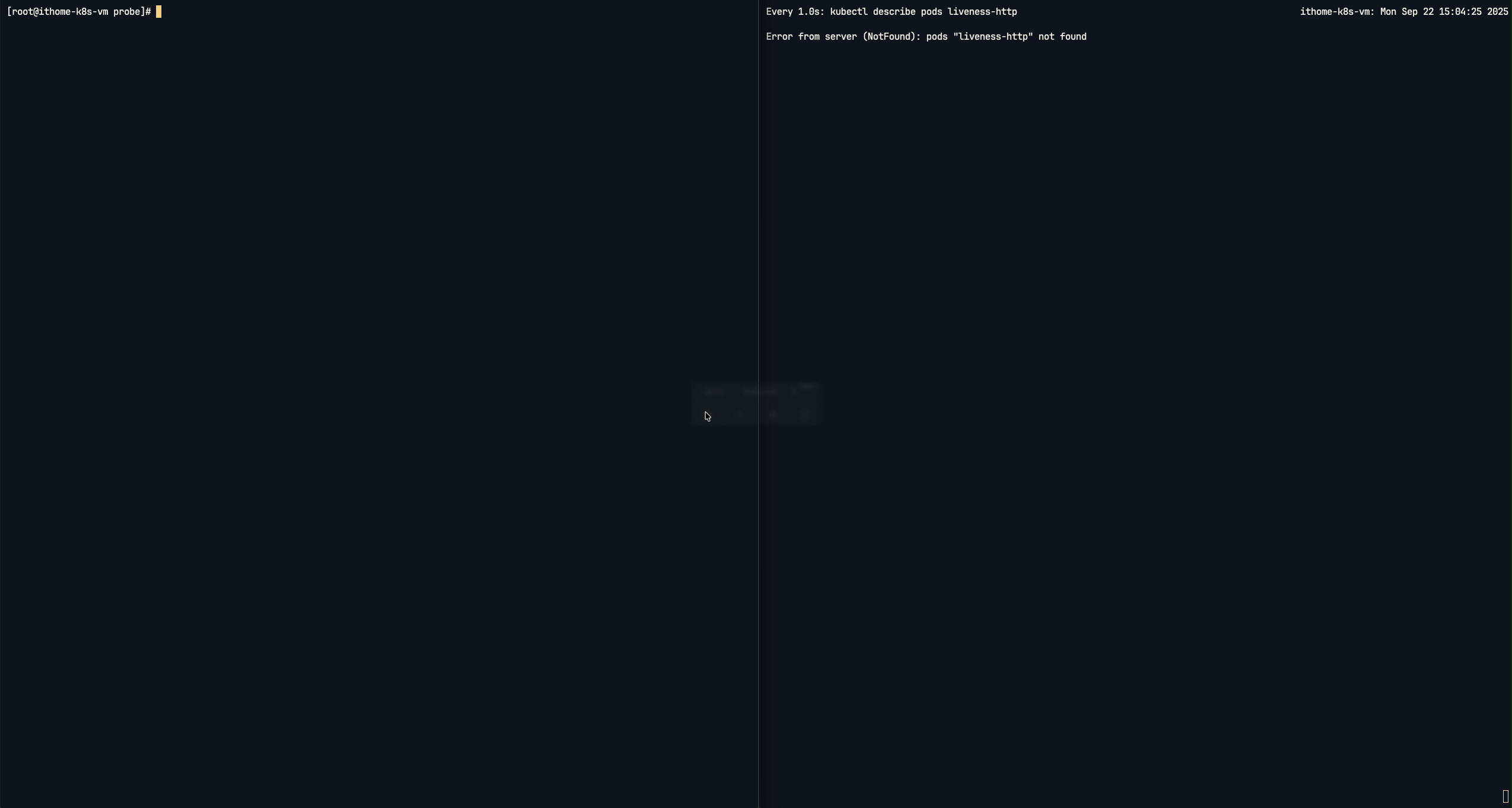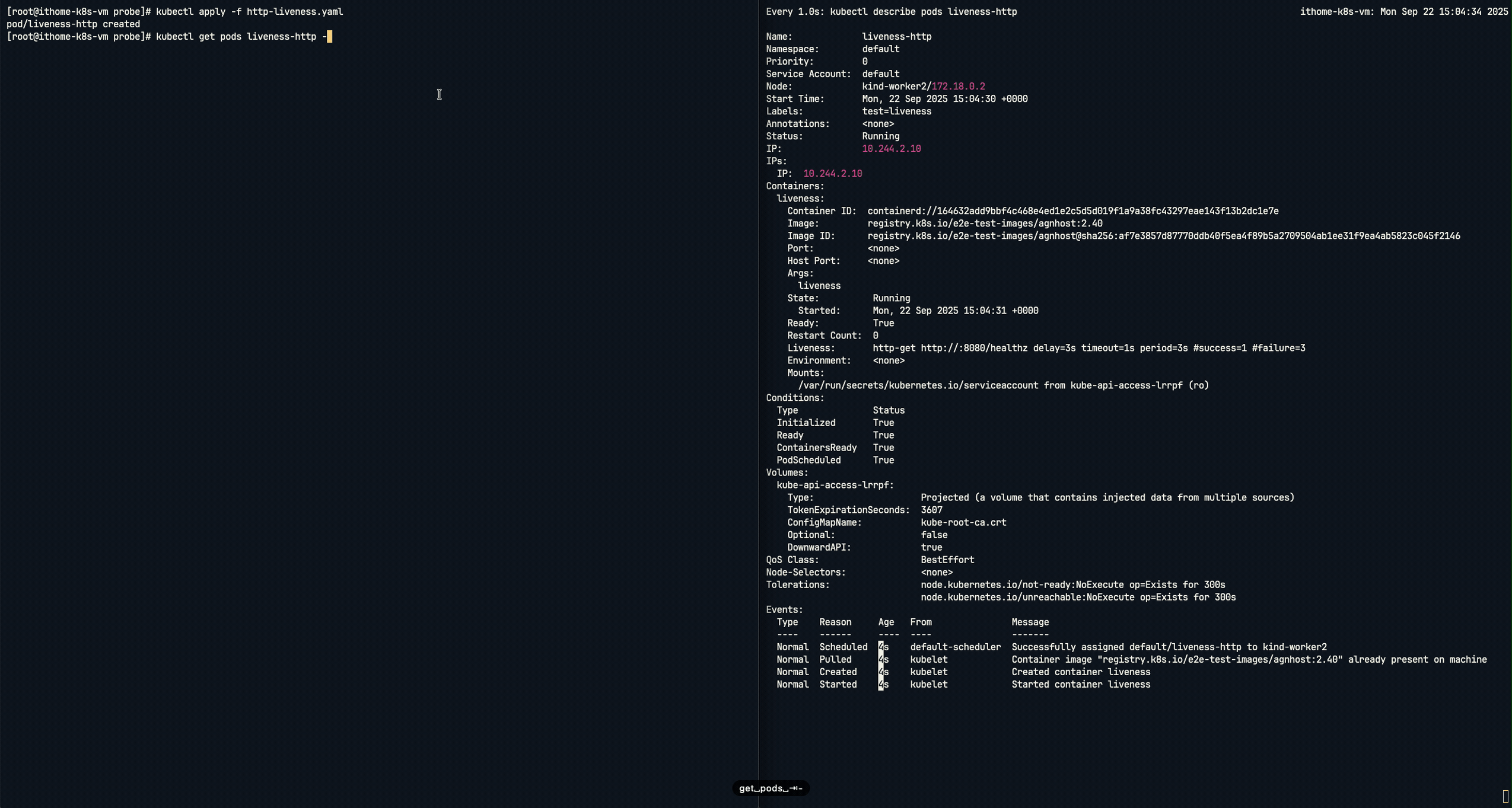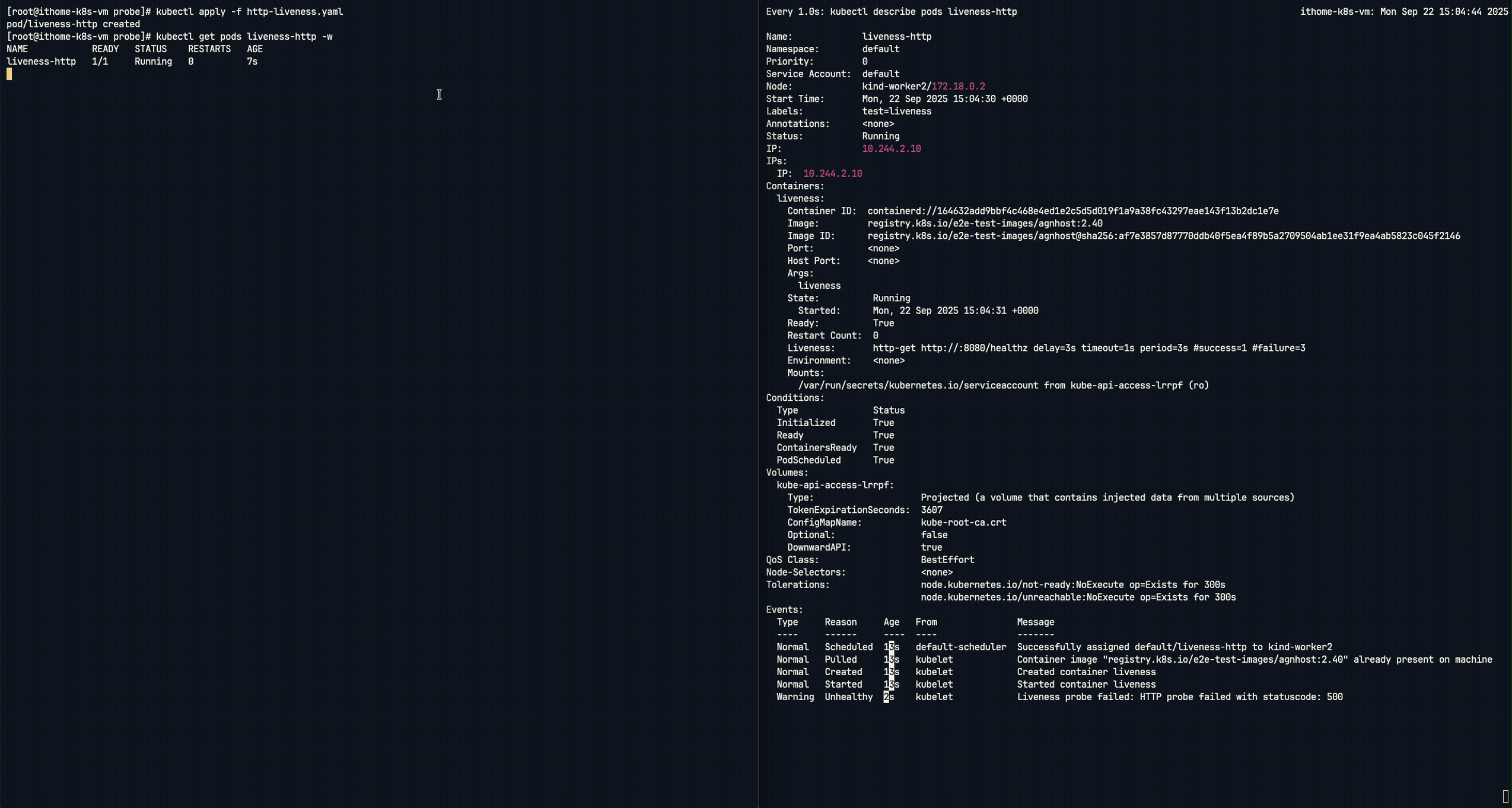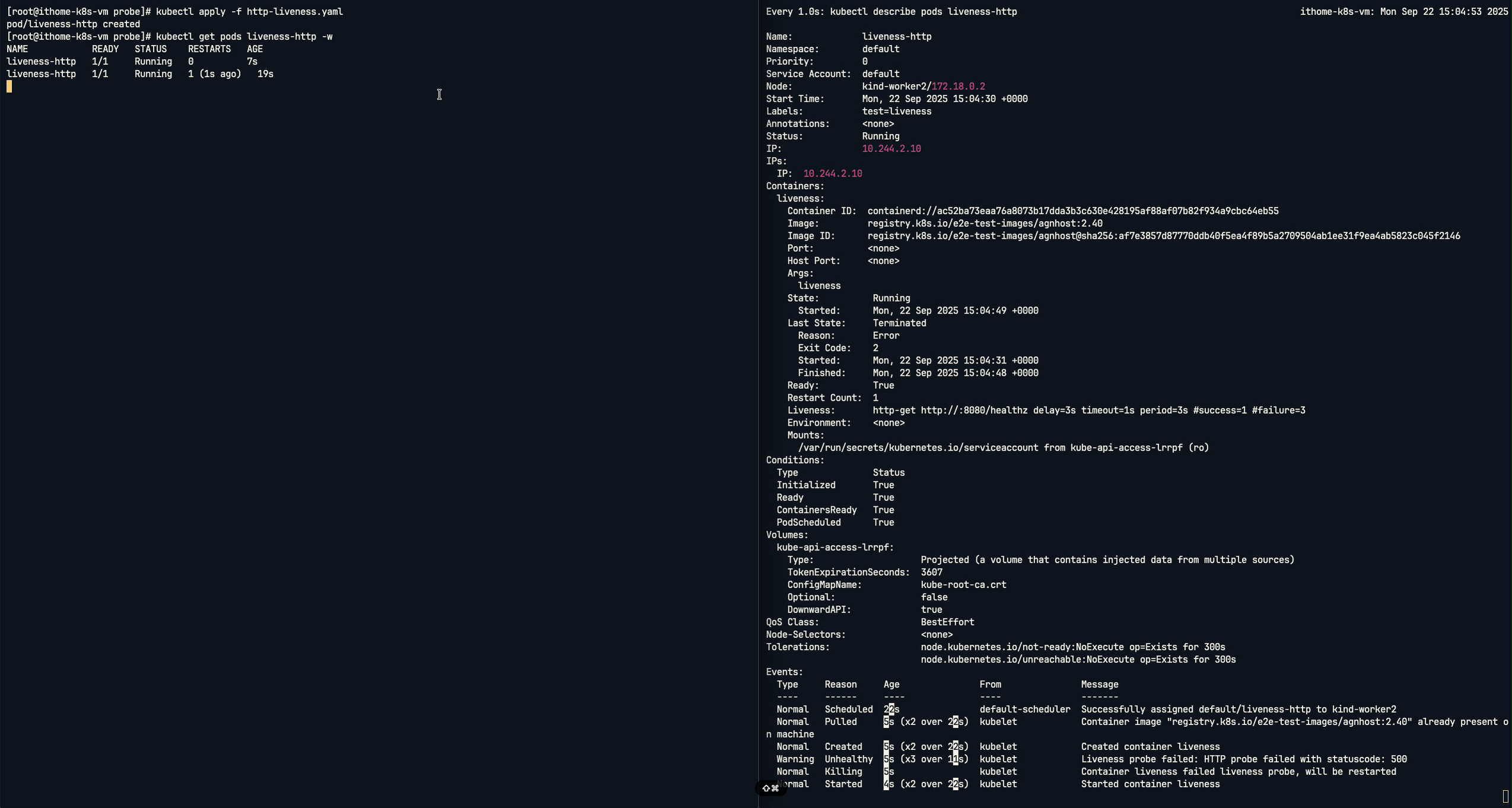
從圖中可以看到,他會立即在 8080 通訊埠上啟動一個 Web 伺服器,在 啟動後的前 10 秒內,對於 /healthz 路徑的任何請求,它都會回應 HTTP 200 OK(代表健康),10 秒之後,它會開始回應 HTTP 500 Internal Server Error(代表內部伺服器錯誤)。系統發出了 Unhealthy 的警告,訊息明確指出 Liveness Probe 因為收到 HTTP 500 狀態碼 而失敗。在連續探測失敗後,Kubernetes 觸發了修復流程,如 Killing 事件所示,kubelet 果斷地終止了這個不健康的容器,並立即將其重啟以試圖恢復服務。
這是 Kubernetes 官方的測試映像檔,我們設定容器在 15 秒 (initialDelaySeconds) 後啟動,kubelet 會開始每隔 10 秒 (periodSeconds) 嘗試與容器的 8080 通訊埠建立 TCP 連線。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
下圖可以看到右邊 Conditions 的地方,一直不是 READY 的狀態,是在 20 秒的時候才變成 True,那是因為探針是每 10 秒一次,第一次沒有連線到,因為 Container 還沒啟動。從圖中可以清楚看到 Pod 在 Running 狀態下,Ready 依然是 False,直到探針檢測成功才變為 True,這就是 Readiness Probe 在避免「流量過早導入」的價值。
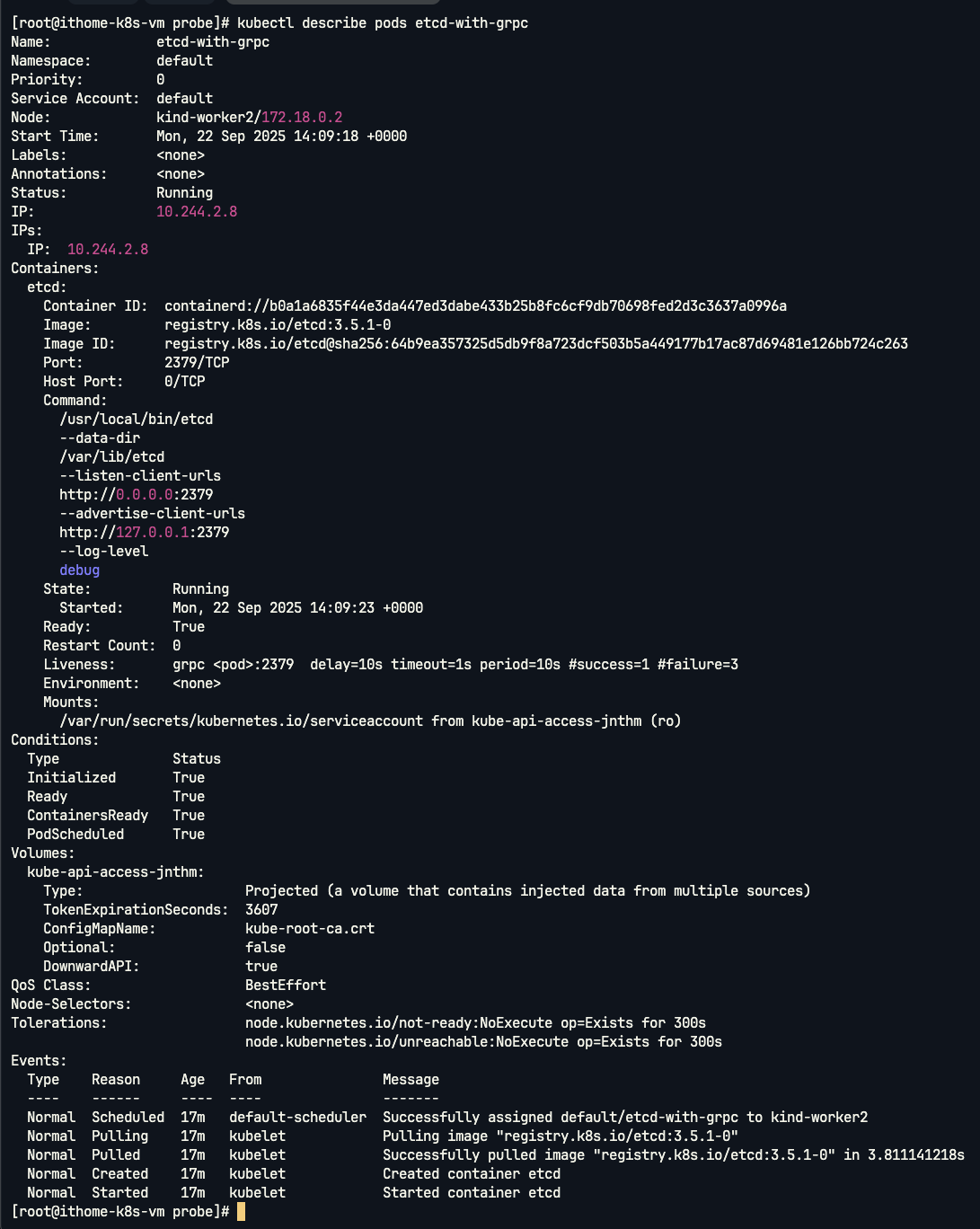
這邊 kubelet 會透過 gRPC 健康檢查協定,直接探測 etcd 的 gRPC 服務。如果探測連續失敗,容器就會被終止並重新建立。
apiVersion: v1
kind: Pod
metadata:
name: etcd-with-grpc
spec:
containers:
- name: etcd
image: registry.k8s.io/etcd:3.5.1-0
command: [ "/usr/local/bin/etcd", "--data-dir", "/var/lib/etcd", "--listen-client-urls", "http://0.0.0.0:2379", "--advertise-client-urls", "http://127.0.0.1:2379", "--log-level", "debug"]
ports:
- containerPort: 2379
livenessProbe:
grpc:
port: 2379
initialDelaySeconds: 10
在這個範例中,etcd 容器使用了 gRPC 探針。雖然在事件紀錄中不會像 HTTP 或 Exec 那樣明顯顯示 Unhealthy,但探針確實會透過 gRPC 健康檢查協定與容器互動。如果服務沒有回應或回報 NOT_SERVING 狀態,容器就會被終止並重啟。從圖中可以看到 Pod 狀態穩定顯示 Running,這代表探針成功確認了 gRPC 服務處於健康狀態。
今天我們透過 Liveness Probe 和 Readiness Probe 理解了 Kubernetes 如何檢查應用程式的真實健康狀態。探針能避免流量被導向還沒準備好的 Pod,或是長時間停留在已經卡死的 Pod 上,讓叢集更可靠、更具自我修復能力。
不過,健康檢查解決的是「服務可用性」的問題。對於大多數 stateless 微服務,Pod 的重啟並不影響運作;但一旦遇到需要保存資料的應用,例如資料庫或檔案系統,單純的探針機制就不夠了。因為 Pod 的生命週期短暫,容器一旦銷毀,裡面的資料也會跟著消失。
因此我們明天要來看看 PersistentVolume (PV) 與 PersistentVolumeClaim (PVC)。它們是 Kubernetes 中用來處理資料持久化的機制,讓應用不再只依賴 ephemeral 的 Pod 生命週期,而能在叢集裡安全保存狀態與資料。
