在前一天的內容,我們了解了向量(vector)與 embedding 的概念,知道文字必須轉換成數字,才能讓電腦理解與運算。
今天我們要介紹 Bag-of-Words(BoW),這是最基礎也是最直觀的文字表示方法。
介紹概念的同時也會有一些程式的實作,大家可以一起試試看!
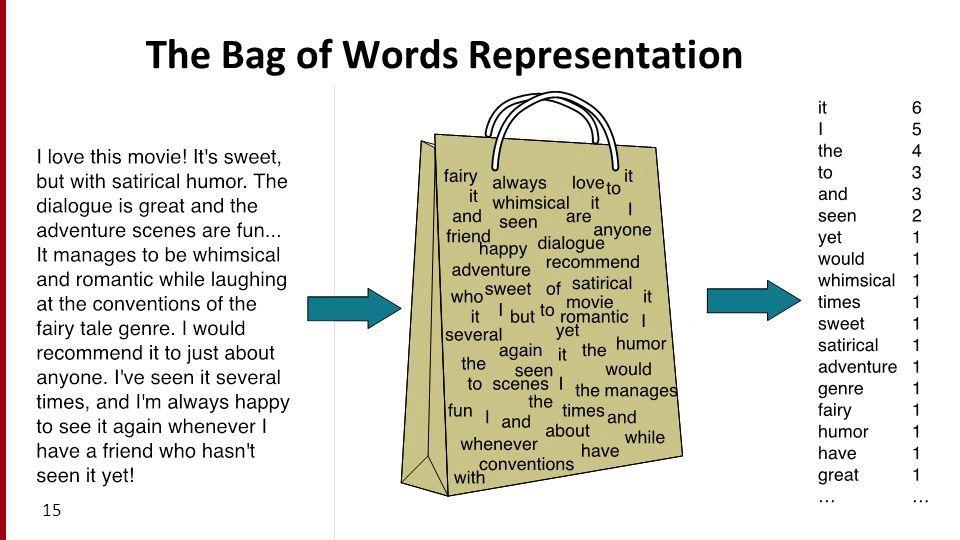
圖片來源:https://sep.com/blog/a-bag-of-words-levels-of-language/
上面這張圖很好地詮釋了「一袋詞」是什麼概念~
一段文本是由一大~堆~詞所組成的,有些詞可能會重複出現,有些詞可能只出現一次。所以我們可以依據詞的出現頻率(詞頻),整理出最右邊的列表。這樣統計詞頻的結果,就可以初步的代表這個文本。
以下用中文舉個例子,首先我們有四個句子:
要統計詞頻就要先斷詞:
電影/很/好看
電影/不/好看
電影/很/難看
電影/好看/不/好看
現在我們有一個詞袋,裡面有不同的詞:
電影、很、不、好看、難看
接著我們就可以統計詞頻,用表呈現:
| 電影 | 很 | 不 | 好看 | 難看 | |
|---|---|---|---|---|---|
| 電影很好看 | 1 | 1 | 0 | 1 | 0 |
| 電影不好看 | 1 | 0 | 1 | 1 | 0 |
| 電影很難看 | 1 | 1 | 0 | 0 | 1 |
| 電影好看不好看 | 1 | 0 | 1 | 2 | 0 |
最後就可以用向量呈現:
[1, 1, 0, 1, 0]
[1, 0, 1, 1, 0]
[1, 1, 0, 0, 1]
[1, 0, 1, 2, 0]
jieba
import jieba
from sklearn.feature_extraction.text import CountVectorizer
# 測試文本
docs = ["電影很好看", "電影不好看", "電影很難看", "電影好看不好看"]
jieba進行斷詞因為這邊
jieba會把「難」、「看」分成兩個字,所以我們用自定義詞典的方式,規定「難看」要被視為一個詞
# 加入自定義詞
jieba.add_word("難看")
tokenized_docs = [" ".join(jieba.cut(doc)) for doc in docs]
# 印出斷詞結果
print("斷詞結果:")
for doc, token in zip(docs, tokenized_docs):
print(f"{doc} → {token}")
print("\n斷詞列表:", tokenized_docs)
# === Output ===
斷詞結果:
電影很好看 → 電影 很 好看
電影不好看 → 電影 不 好看
電影很難看 → 電影 很 難看
電影好看不好看 → 電影 好看 不 好看
斷詞列表: ['電影 很 好看', '電影 不 好看', '電影 很 難看', '電影 好看 不 好看']
cv = CountVectorizer(tokenizer=lambda x: x.split(), token_pattern=None)
bow_vec = cv.fit_transform(tokenized_docs)
print("詞彙表:", cv.get_feature_names_out())
print("BoW 向量:\n", bow_vec.toarray())
# === Output ===
詞彙表: ['不' '好看' '很' '難看' '電影']
BoW 向量:
[[0 1 1 0 1]
[1 1 0 0 1]
[0 0 1 1 1]
[1 2 0 0 1]]
相信今天的內容,大家應該覺得很簡單吧~~
BoW 的優點就是簡單、快速而且也容易理解。但是 BoW 也有一個很大的限制是,它在將文字轉成向量時,只關心每個詞在文本中出現的頻率,而忽略了文字是有順序的。
不過理解 BoW 後,我們就建立了文字向量化的基本概念。明天的內容是 TF-IDF,它是建立在 BoW 之上更進階一點的表示法,我們明天見囉~

