我們知道電腦無法像人一樣直接理解文字。要讓電腦「看懂」文字,我們必須先把文字轉換成數字的形式,才能進行後續的分析或建模。
在 主題三:特徵與表示 中,我會介紹一系列把文字轉成數字的方法,也就是文字的 表示法(representation),也可以稱作文字的 特徵(feature)。
這些表示法從最簡單、直觀的統計方法開始,隨著對文字資訊理解的加深,會演變得更精緻,能捕捉更多語意和上下文的資訊。
首先要來介紹兩個概念,也是後面會不斷提到的詞:向量(vector)和嵌入(embedding)
「向量」就是大家在高中數學有學到的一個數學上的概念。基本上就是一串數字,像這樣 [0.2, 0.8, 0.1]。向量有方向和大小的概念,可以做數學運算,可以是多個維度,可以在空間中表示。
所以向量本身是一種資料結構,可以用來表示任何數字化的資訊,包括文字、圖片和聲音等等。
而當我們是把「文字」轉成數字後,這串向量我們就可以稱之為 「嵌入」(embedding)。
當我們把文字向量化,變成 embedding 後,文字本身的各種特徵或資訊就像是被「打包」起來,例如:詞頻、詞的重要性、語義等,都可以用這串向量來表示。
像是我們在之前文章提到的 OpenAI token 計算的網頁中,將「自然語言處理」這段文字 tokenize,每個 token 有自己的 token ID,然後形成的這串數字 [116258, 40909, 17765, 129805, 5584] 就是一個 embedding。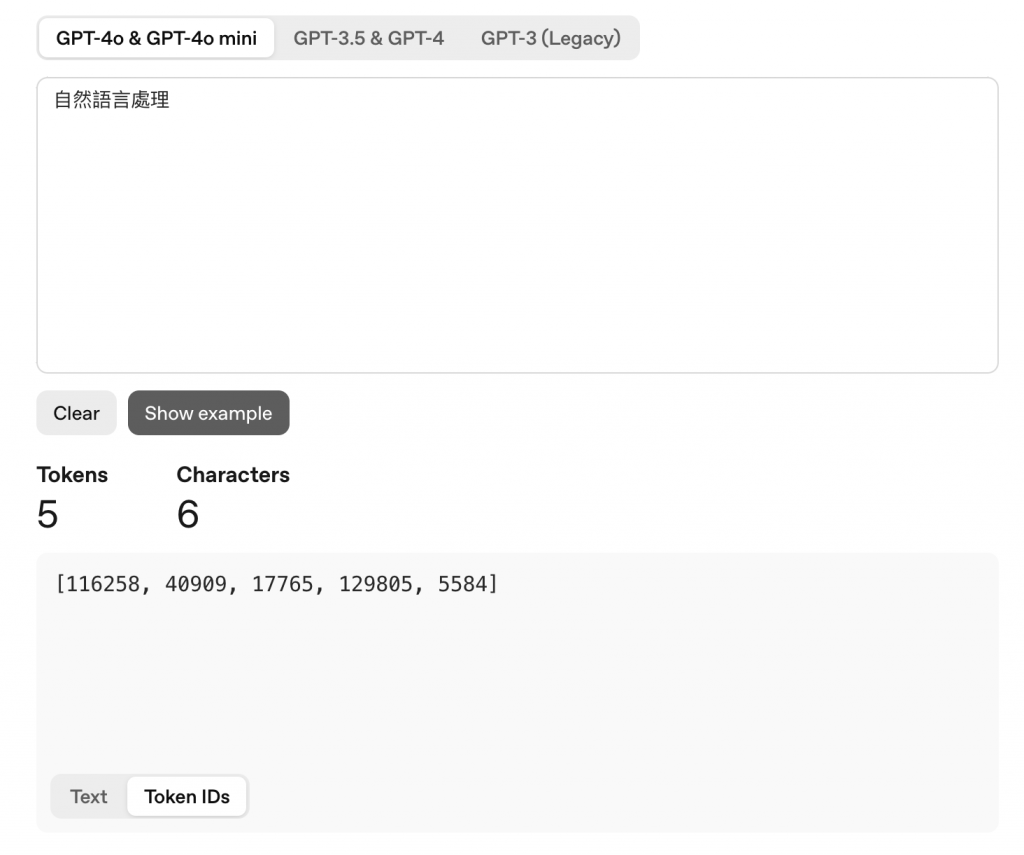
而依據文字的尺度,會有 「詞嵌入」(word embedding) 或是 「句子嵌入」(sentence embedding)
將文字向量化後,電腦就能以數學的方式去理解和比較文字
可以透過向量計算文字之間的意思是否相近。如下圖,將向量在空間中表示,可以看到水果類比較靠近,動物類則在另一邊彼此靠近。

圖片來源:https://ubiai.tools/how-vector-similarity-search-functions/
一樣透過在空間中的分布,我們可以看到比較相近的會聚在一起,形成集群(cluster),這樣我們就可以為文本分類。例如:判斷評論是正面還是負面

圖片來源:https://douglasduhaime.com/posts/clustering-semantic-vectors.html
向量涵蓋了文字的語意關係,又因數字可以去做加減乘除的運算,所以語意的關係可以用向量來計算,例如:國王 - 男人 + 女人 ≈ 女王

圖片來源:https://towardsdatascience.com/word2vec-research-paper-explained-205cb7eecc30/
接下來,我們會依照歷史發展與複雜程度,逐一介紹文字轉換成向量的方式:

