前面三天我們一步步完成了資料前處理、建立向量資料庫、向量檢索、重排序,今天終於要進入最後一塊拼圖:生成(Generation),也就是讓 LLM 把前面找到的知識,轉化成自然、流暢又有邏輯的回答 💬
但是呢除了讓模型生成答案,我們還要讓整個流程「看得見」,這樣才用得爽 XDD 所以今天的任務不只是文字生成,我們還會用 Streamlit 做一個簡單的互動式網頁介面,讓你能直接輸入問題、即時看到系統從檢索、重排序到生成的完整過程~~
這樣就完成我們整個 RAG 實作系列的最終成品:一個屬於自己的 「不唬爛」AI 小助手 🤖
本系列實作的架構圖:
ithomeNLP_RAG/
├── requirements.txt
├── data/
├── db/ # qdrant vector db
├── indexer.py # store vector
├── retriever.py # vector search
├── reranker.txt # rerank
└── frontend.py # generation + UI
我們今天會做的是 frontend.py
這邊使用的是 Gemini 的免費 API,大家可以依自己需求去串接不同的 LLM。但是不同的 LLM 吃 Prompt 的方式不一樣,要再自行研究一下~
import streamlit as st
from collections import defaultdict
from reranker import main as rerank_main
import google.generativeai as genai
# 設定模型
API_KEY="your_API_key"
genai.configure(api_key=API_KEY)
def generation(prompt):
# 初始化文字模型
model = genai.GenerativeModel('models/gemini-2.5-flash-lite-preview-06-17')
response = model.generate_content(prompt)
return response.text
# Streamlit 頁面設定
st.set_page_config(page_title="RAG Demo")
st.title("🤖 📚 RAG Demo")
# 使用者輸入
query = st.text_input("請輸入你的問題:", placeholder="tfidf算法是什麼?")
if st.button("Search") and query.strip():
st.info("🔍 正在檢索...")
top_k = 10 # 預設向量檢索為 10 筆
try:
# Retriever + Reranker
original_results, reranked_results = rerank_main(query, top_k)
st.success(f"✅ 檢索完成,共取得 {len(original_results)} 筆結果")
# 顯示 reranking 後前 5 筆結果
grouped = defaultdict(list)
for res in reranked_results[:5]:
grouped[res.get('source', 'Unknown')].append(res)
st.subheader("📑 Top 5 相關參考資料")
for source, items in grouped.items():
# 按 id 排序
items_sorted = sorted(items, key=lambda x: x.get('id', ''))
with st.expander(f"Source: {source} ({len(items_sorted)} chunks)"):
for i, res in enumerate(items_sorted, 1):
st.markdown(f"**{i}.** **Score:** {res.get('similarity_score',0):.4f}")
# 顯示前 300 字,如果超過用 ... 截斷
content_preview = res.get('content','')[:300]
if len(res.get('content','')) > 300:
content_preview += "..."
st.write(content_preview)
st.write("---")
# Generation: 將 top-k content 拼接成 context
context = "\n\n".join([res['content'] for res in reranked_results[:10]])
# 餵入模型的提示詞
prompt = f"請根據以下內容回答問題:\n\n{context}\n\n問題: {query}\n答案:"
st.info("📝 正在生成回答...")
answer = generation(prompt)
# 顯示回答
st.subheader("🧠 AI 生成回答")
st.write(answer)
except Exception as e:
st.error(f"❌ 發生錯誤: {str(e)}")
最後在指令介面將網頁起起來就大功告成啦~~
streamlit run frontend.py
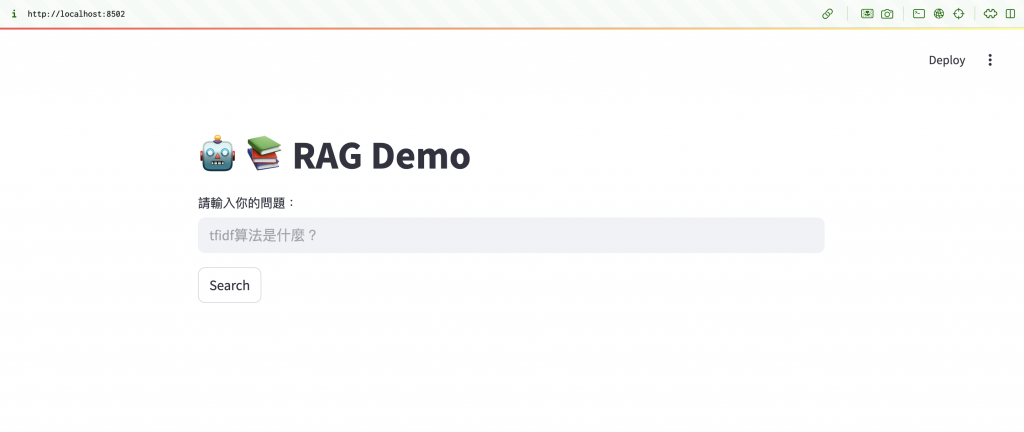
圖一:初始頁面
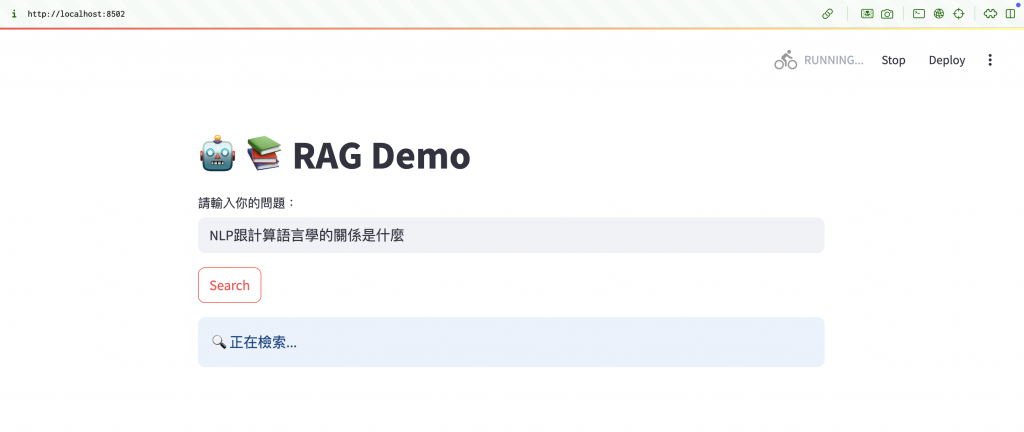
圖二:搜尋開始
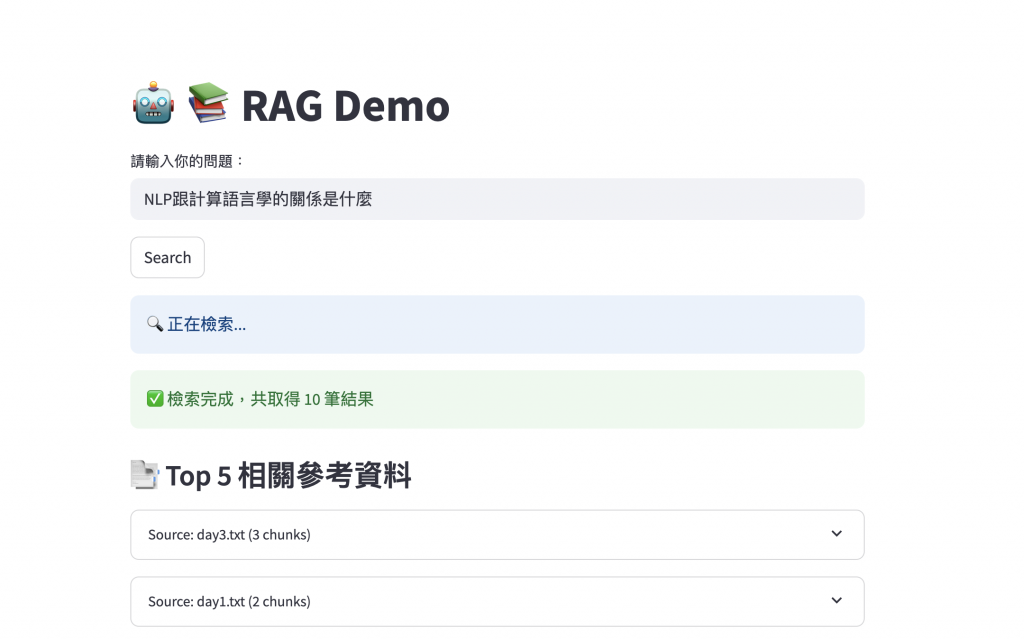
圖三:向量搜尋回 10 筆資料,網頁顯示重排序後前 5 筆

圖四:重排序後前 5 筆的內容預覽

圖五:LLM 整合檢索資料進行增強生成
我們在今天加入了 Generation 和 Streamlit 展示介面,把整個流程串成一個完整的知識問答系統後,就終於完成 RAG 系列的最後一步啦 🎉🎉🎉
回歸到 RAG 的目的,其實就是把「讓 AI 不再亂講話」這件事一步步具體實踐出來。
現在你已經具備打造自己專屬 AI 助手的能力了!接下來你也可以試著用不同的文件資料集、抽換不同的 embedding 模型、還有改良 Prompt,探索各種方式讓這個系統越來越貼近你的應用場景,提升整體的表現~~
RAG 的旅程到這裡告一段落,這三十天的挑戰也終於走到終點啦 🥹🎊
感謝看到這裡的你們,我們後會有期囉~~👋🏻💅🏻

