大家有沒有遇過這種情況,就是你問 GPT 一些文獻要怎麼找,結果它開始亂丟一堆研究給你,講得天花亂墜,但大部分它說的文獻根本就不存在 😭
有時候,當 LLM 要回答你的問題,但它的知識不夠時,它就只能「唬爛」,這種時候真的是氣氣氣...
就像我們之前說的,GPT 是文字接龍的高手,但它不是百科全書。所以我們能做的就是「把一本書塞給它」,讓它有正確的內容可以參考,然後再做它擅長的事,就是生成流暢、有邏輯的文字。
這就是 RAG(Retrieval-Augmented Generation) 的核心概念!它能讓 LLM 不再只靠過去 「讀」(訓練)過的記憶 來回答問題,而是結合 外部資料、找到 正確答案,再依據這些知識 生成可靠的回答!

圖片來源:https://x.com/CustomGPT/status/1829548452981674392
我們這篇會先介紹 RAG 的概念跟流程,然後接下來幾篇的內容會是一系列實作~~
RAG 這三個字母分別說明了三個核心概念:
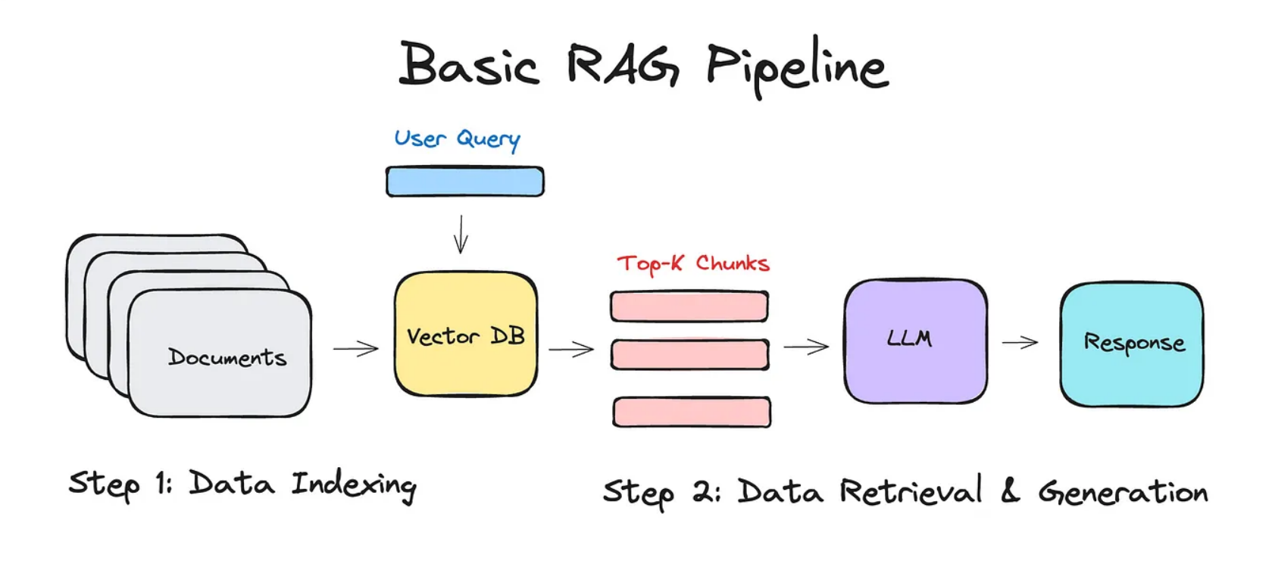
圖片來源:https://medium.com/@mayssamayel4/building-a-rag-system-with-gpt-4-a-step-by-step-guide-291711342f0d
RAG 系統就像是一位「會查資料的 AI 助理」,當你問它問題時,它會依序做以下動作:
使用者問問題(Query):一切從你的問題開始。這個問題就會被送進 RAG 系統,準備啟動它的資料搜尋之旅。
檢索(Retrieval):在回答之前,RAG 會先去「找資料」。主要有兩種常見的方式:
不過,這個階段找回來的資料不一定每一條都那麼相關,所以接下來可以進入下一步。
重排序(Reranking):在前一階段他可能 retrieve 了 100 個文件,有些非常相關,有些只是擦邊。Reranking 就是要重新評估每篇文件與問題的相關性,把最重要、最相關的排在前面。
生成(Generation):最後,RAG 會把這些「補充知識」餵給 LLM,讓模型進行整理、歸納,生成出最終回答!
以上就是 RAG 的基礎架構啦~
還記得我們一開始提到的那個「GPT 唬爛」的例子嗎 XDD
其實像這樣 LLM 產生 幻覺(Hallucination) 的狀況,現在也在慢慢改善中。像現在 GPT 的新功能會顯示它正在搜尋網頁,那其實就是一種 RAG 的應用哦!
我在寫這篇文章的時候,剛好有一些時事新聞,我就請 GPT 幫我整理懶人包。結果就算是這麼新的議題,它也已經可以整理出蠻完整也蠻正確的資訊,甚至會加上圖片,太厲害了~~

但你可能會想問:「GPT 都這麼厲害了,我還需要學 RAG 嗎?」🤔
當然還是要啊!!
因為有些應用場景,我們可能無法使用網路版的 LLM(例如:隱私、企業內部知識庫、沒有網路環境)。所以接下來幾天,我們把整個流程拆成幾個小步驟,一起來一步步在地端實作一個屬於自己的 RAG 系統吧!!

